Prepare for the Future of Observability
ARCHIVED
18 September 2024 - ID G00807970 - 7 min readBy Mrudula Bangera
Digital transformation, growth in the volume of telemetry data in cloud environments and other factors are causing I&O leaders to reevaluate observability strategies. This research identifies the aspects of observability that must evolve and measures I&O leaders need to adopt to remain relevant.
Overview
Key Findings
- Cloud-native environments generate large amounts of observability data, making it costly to ingest and retain telemetry, especially when some data is redundant. Collecting all available telemetry data also increases the risk of missing important insights among less valuable data.
- As multiple tools and silos increase the complexity of infrastructure environments, organizations struggle to maintain the pace of innovations while keeping applications secure.
- Many organizations recognize AI’s transformative potential to empower observability but are uncertain how to begin leveraging these capabilities.
Recommendations
- Build and continuously evolve your observability strategy by establishing a center of excellence (COE) or centralized observability team capable of performing this role. Ideally, they determine which data to collect from sources and eliminate collection and retention of redundant data. This makes the data meaningful, governs data retention and implements best practices for observability.
- Enhance application resilience and speed up product delivery times by consolidating and standardizing the observability toolset for efficiency and consistency across the enterprise.
- Improve processes by leveraging advanced AI capabilities built into many vendor tools. This will help with anomaly detection, predictive analytics, root cause analysis, automated remediation and natural language processing to drive efficiency and improve performance overall.
Introduction
The surge in dynamic, multicloud environments, use of microservices and serverless, combined with increased volumes and velocity of data and a growing number of stakeholders, has introduced a level of complexity that traditional monitoring tools and approaches can’t handle. The inability to make sense from the ever-growing volumes of data and understand the “why” behind deviations and anomalies results in delays in getting the insights needed to inform action.
For many enterprises, increasing costs associated with storing and analyzing observability data, whether they are building their own solution or using vendor tools, offsets the benefits they receive from it. The increasing number of disparate monitoring tools also adds to inefficiency and complexity in the organization, creating a need to manage multiple tools interfaces and different data formats. To ensure insight that keeps pace with the growing speed and complex architectures, infrastructure and operations (I&O) leaders must prepare their organizations for the future by evolving from traditional monitoring to observability.
Observability is the characteristic of software and systems that enables them to be understood, based on their outputs, and enables questions about their behavior to be answered (see Figure 1).
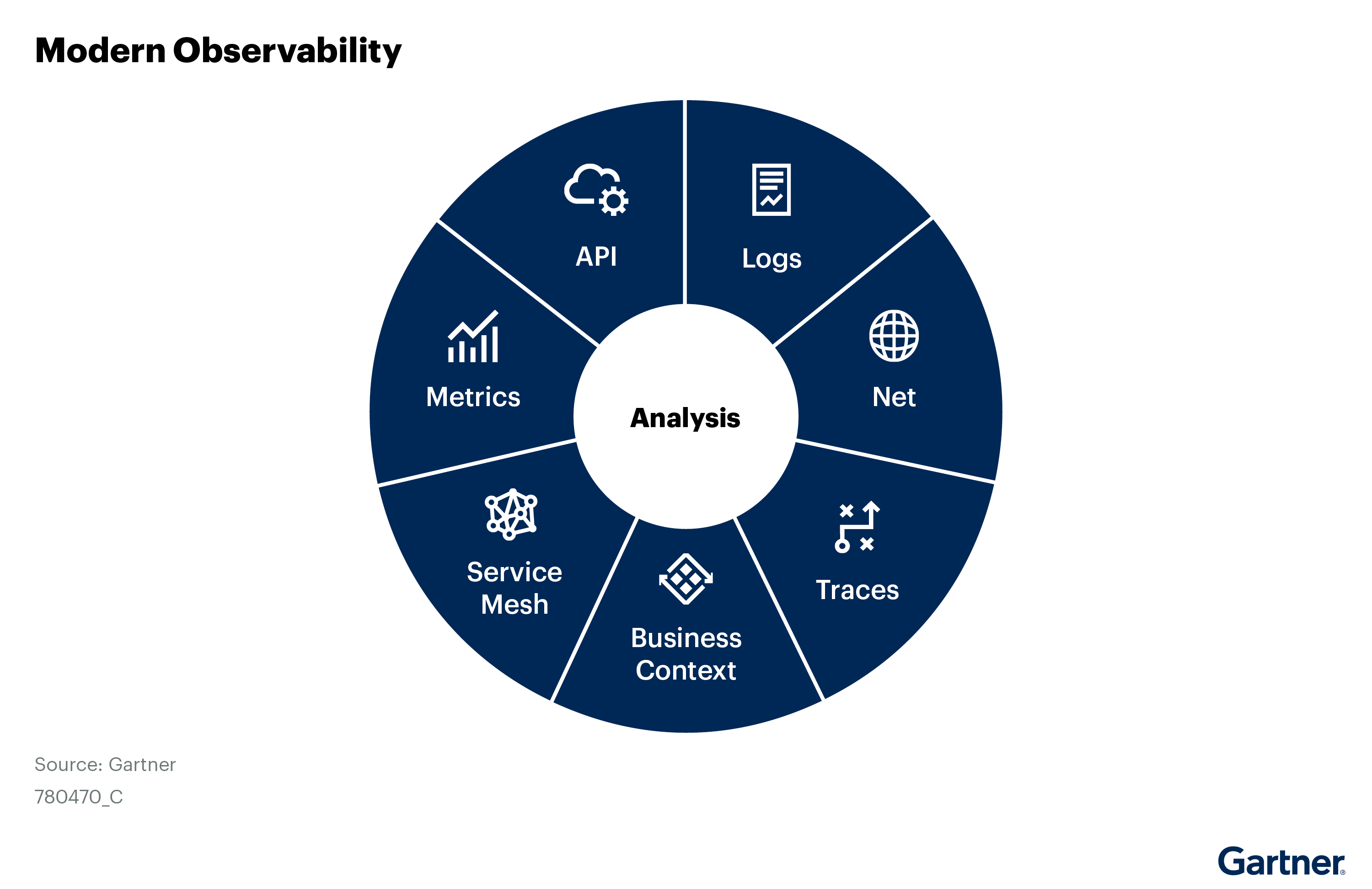
In monitoring, we relied on fixed agents from vendors for collection of data like logs, metrics and traces to monitor for indicators that we already understand have a potential impact on availability or performance. In observability, we are not only supporting IT operations but also business objectives by enhancing data-driven decision making.
We must understand how the data and the telemetry we collect about the applications and infrastructure relate to critical business services, as well as customer experience and employee experience. It is about connecting all these together to understand the complete picture as it continuously changes.
While there are many benefits of adopting observability as a practice and many are rushing to implement observability platforms, the following are key considerations to ensure benefits are realized in the future.
Analysis
Build and Continuously Evolve Your Observability Strategy
The cost of observability has become a significant focus, influenced by prevailing macroeconomic conditions, consumption-based pricing and increased scrutiny applied to cloud spend. Previously, monitoring pricing was primarily determined by the number of devices or hosts being monitored, making it relatively straightforward to calculate monitoring spend.
However, with the advent of open standards and consumption-based pricing in commercial observability platforms, the focus has shifted from simply collecting data to leveraging analytics and the valuable insights they provide.
Evaluate Value Versus Cost
To optimize spend on observability, enterprises should continuously evaluate the value of the data they are collecting and storing. It is important to evaluate the cost of observing an application versus the value of insights it delivers. Similarly, even with commercial vendor tools, understanding the usage and billing patterns can help mitigate unexpected spikes and overspending in tools.
Itemized and detailed billing information can be useful for budgeting, planning which data needs to be sent to the observability tool and determining how long it needs to be retained. While evaluating the tools, organizations should include the features available in the tool’s user interface (UI) to track the usage or consumption of units or committed spend.
Adopt Data Standards
Open Telemetry (OTel) is emerging and supported by most observability vendors. It provides an open, industry standard for collecting telemetry data across different applications. While OTel simplifies the telemetry data management, it also can bring significant cost savings through the elimination of some software licensing costs and other efficiencies.
Organizations should standardize data collection by adopting open standards such as OTel. It accelerates development cycles by eliminating the need for repeated instrumentation efforts, enabling engineers to focus more strategically. OTel can also help reduce operational costs such as customization/consulting services by allowing organizations to tailor telemetry data collection and processing to their specific needs. They can do this on their own, without relying on costly proprietary tools or consulting services.
Like commercial and proprietary offerings, OTel provides resource usage data, such as CPU memory that can be used to optimize cloud computing budgets by better informing resource allocation.
Create a Center of Excellence or Centralized Observability Team
The number of personas looking for insights from observability platforms is increasing. Many enterprises are also forming centralized teams for their observability initiatives. These teams can take the form of a physical or a virtual center of excellence team with key stakeholders from I&O and platform teams. Ideally, they are responsible for standardizing the data formats, governance of tools, best practices and introducing automation to improve efficiency.
Standardize the Observability Toolset
To address the issue of tool sprawl, organizations should assess their existing tools to ensure they align with the organization’s requirements. This evaluation will enable them to rationalize and consolidate their tools, where appropriate. In addition, organizations should consider standardizing data formats and automating repetitive tasks to streamline operations and enhance efficiency by minimizing unnecessary workload.
Manage Tooling and Life Cycle
In cloud-native environments, most organizations generate a huge volume of telemetry data — more than five to 10 TB daily, especially log data. This creates cost-driving complexity in managing the data. This can be mitigated by implementing data management strategies, such as categorizing data by relevance. Doing this can improve resource allocation.
Organizations should create a policy for retaining different types of telemetry data, based on their compliance and operational requirements, ultimately applying processing techniques to transform and enrich data. This can involve filtering, aggregating or performing calculations to derive data insights.
Organizations should also regularly review and evaluate the effectiveness of telemetry life cycle management processes. Continuously improve data optimization and collection, processing and analysis workflows, based on evolving business requirements and technological advancements.
Implement Telemetry Pipelines
Adopting telemetry pipelines is increasing to address the growing complexity and volume of telemetry collected by observability tools.Telemetry pipelines allow organizations to collect, enrich, transform and route data to multiple destinations. It helps organizations control their data, reducing ingestion cost and storage costs. In this approach, processing takes place in the pipeline and can reduce ingestion by filtering, discarding, routing and transforming data (from logs to metrics, for example).
Leverage AI Capabilities to Improve Processes and Productivity
AI plays a key role in observability’s strategic potential. AI/machine learning (ML) helps enterprises analyze the huge volume of data collected by observability tools efficiently, providing insights that are not humanly possible. Organizations should take small steps with tangible benefits in their AI adoption (see Figure 2).
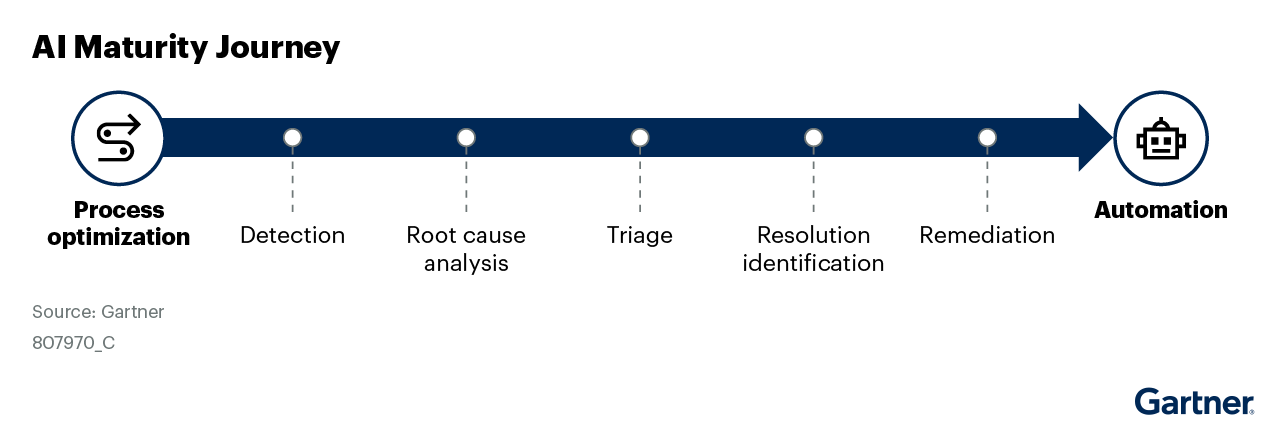
Organizations should view AI as a means to enhance human productivity, expedite processes and, ultimately, automate remediation. Considering the maturity journey, there are many easily achievable use cases (on the left side in Figure 2) that offer immediate benefits.
Steps to undertake in AI adoption:
- Set realistic expectations from AI.
- Explore and leverage AI/ML capabilities available in observability tools.
- Prioritize use cases, and start with ones that offer achievable outcomes, such as anomaly detection, probable cause analysis and triage.
- Understand and implement predictive analytics to predict issues before they occur, causal analytics to identify an issue’s cause and effect by analyzing the relationships. Use generative AI (GenAI) capabilities for natural language data access to create content.
- Elevate the effectiveness of current tools by enabling automation of IT operations (ITOps) workflow and remediation.
AI can bring significant advancements in observability and troubleshooting performance issues. It can analyze data from various sources — metrics, traces, logs and events — and provide a holistic approach for better understanding system behavior. It can be integrated with DevOps workflows, enabling continuous monitoring and feedback loops, leading to faster software delivery. By leveraging AI/ML capabilities, organizations can enhance their ability to detect, diagnose and resolve issues, ultimately leading to improved system performance and user experience.
The information presented in this research is based on the following Gartner Magic Quadrant and Hype Cycle: