Emerging Tech Impact Radar: Generative AI
14 February 2025 - ID G00809486 - 122 min read
By Annette Zimmermann, Danielle Casey, and 15 more
High-impact technologies such as AI agents and reasoning models will disrupt how the world interacts with technology. Use this Impact Radar to make critical decisions on investing in emerging Gen-AI technologies to enable customers to reach new heights of value in their business.
Overview
Key Findings
- The development of reasoning models will offer a significant advancement for businesses due to their ability to solve complex problems with high accuracy. Such models use a chain-of-thought approach that allows them to analyze and articulate the necessary steps to reach a solution.
- Agentic AI will create significant opportunities to improve productivity, customer experience and decision making, but it will require user trust to gain sustained adoption.
- Multimodal GenAI will transform enterprise applications by enabling the addition of new user interfaces, features and functionalities.
- Synthetic data will revolutionize multiple industries and use cases in the next three years as it removes reliance on real-world data and enables endless opportunities for simulations and data-generation techniques.
Recommendations
- Identify high-value applications for reasoning models, particularly agents requiring multistep actions, models serving as coordinators to orchestrate multiagent systems, and improving small-model reasoning performance through distillation and fine-tuning.
- Establish the basis for agentic AI adoption by starting with agents that carry out simple actions reliably and consistently, such as completing expense claim fills or parsing patient intake data in healthcare.
- Accelerate to high-quality multimodal experiences by first exploring acquiring curated text, image, video and audio datasets from AI marketplaces instead of developing in house.
- Create a strategic roadmap prioritizing short-term synthetic data use cases focused on augmenting model training, especially for domain-specific tasks where real data is hard to acquire and noisy, while using simulations to understand and improve business processes in the long term.
Strategic Planning Assumptions
By 2028, one-third of interactions with enterprise generative AI software will invoke autonomous agents to achieve tasks, up from less than 1% in 2023.
By 2028, 40% of AI asset purchases, including models and data by enterprises, will take place via AI marketplaces, up from less than 5% in 2024.
By 2030, 80% of enterprise software and applications will be multimodal, up from 1% in 2024.
By 2030, synthetic data will constitute more than 90% of the data to fill in edge scenarios for training AI models, up from 5% today.
Analysis
This Impact Radar discusses 22 of the most important GenAI technologies and trends along four main themes: model-centric technologies, model performance tools and techniques, the AI data frontier and AI-enabled applications (applied GenAI).
Model-Centric Technologies Are the Basis for Disruption
Model-centric technologies in this Emerging Tech Impact Radar fall under three sub-themes, which include:
- Enhanced reasoning and contextual understanding
- Reasoning Models
- Long-context window models
- Active inference
- Model efficiency and accessibility
- Domain-specific language models
- Small language Models
- Open language Models
- Other capabilities
- Multimodal GenAI
- Diffusion AI models
- Large action models
Enhanced reasoning and contextual awareness in AI focus on improving the ability to tackle complex tasks through better problem solving and text processing. A key development in this area is “inference time scaling.” Reasoning models like OpenAI o1 and DeepSeek-R1 use reinforcement learning to improve performance in logic, math and coding by generating “chains of thought.” Long-context window models, such as Qwen2.5-1M, excel in facilitating in-context learning, a vital aspect of generative AI. These models manage up to 1 million tokens using techniques like Dual Chunk Attention, allowing them to adapt to various tasks without explicit retraining. By leveraging context in prompts, they efficiently generate responses, enhancing performance in nuanced tasks and simplifying user interaction. Active inference, based on the free energy principle, further boosts AI adaptability by integrating perception, cognition and action, focusing on continual learning and real-time interaction.
Model efficiency and accessibility are key trends in AI, focusing on making technology more usable and affordable. Innovations such as outsize small language models (SLMs) and domain-specific models are at the forefront of this movement. The evolution of small model development, highlighted by DeepSeek, enables the creation of SLMs that can match or even surpass the performance of larger models while using two to three orders of magnitude fewer parameters. This advancement allows powerful AI to run on consumer-grade hardware, including laptops and edge devices, freeing generative AI from the data center for a wide range of use cases. Additionally, domain-specific models, tailored to particular industries or tasks, can now be developed on local hardware. This is made possible by the lower barriers to entry demonstrated by a mix of known and new innovations from DeepSeek’s efficient architectures, thereby making AI more accessible to a broader range of users.
Other capabilities focus on enhancing AI’s ability to seamlessly integrate into a wide range of use cases and workflows. Innovations such as multimodal generative AI, diffusion models and large action models are driving this trend. These technologies enable AI to process and synthesize diverse data types, including text, images and audio, enhancing its contextual understanding and applicability. Large action models, in particular, empower AI to execute complex task sequences and make informed decisions in dynamic environments, significantly expanding its utility. This equips AI systems with the capabilities needed to effectively integrate into fields like healthcare, entertainment and autonomous systems. By developing these capabilities, AI systems become more effective and valuable tools, ensuring high-quality outputs and adaptability in real-world scenarios, while complementing advancements in model efficiency, accessibility and reasoning.
Model Performance Tools and Techniques Will Drive Accuracy, Safety and Sustainability
The technologies included in this theme include:
- Sustainable AI
- GraphRAG
- GenAI engineering tools
The technologies included in this theme are enabling advancements in model accuracy and safety, as well as ethical considerations concerning the use of GenAI outputs. Sustainable AI incorporates environmental, social and governance aspects into decision making. The rapid development and adoption of small language models (see model-centric technology theme) present an opportunity for enterprises and product leaders to leverage GenAI models that are much more resource-efficient than generic LLMs. A critical driver is the alignment of cost and sustainability benefits, with resource-efficient models being, in general, considerably cheaper as well. We expect the breakthroughs demonstrated by DeepSeek to accelerate this trend. With the lower costs and compute requirements, the whole industry will move from large, generic LLMs to more industry- and domain-specific models.
GraphRAG alleviates some of the accuracy challenges with GenAI solutions, which result from generating responses based on patterns in data rather than verified facts, leading to hallucinations or misinformation.
The AI Data Frontier Is Expanding to Address Advanced Model Building
This theme includes the following technologies:
- Synthetic data
- AI marketplaces
- Data center microgrid
This theme discusses some of the critical steps that involve building a GenAI model and the decisions that have to be made with each of these steps and building blocks. Helping clients make their data AI-ready is one of the key building blocks in any AI journey and a common challenge that will need to be addressed by tech providers. Whether data is AI-ready is determined by different parameters, including the use case and the qualification of datasets. AI marketplaces help organizations to address some of these key issues by making high-quality data accessible. AI marketplaces accelerate collaboration, innovation, processes and know-how. These marketplaces will become indispensable and drive over 40% of transactions (data, apps, and model sharing and selling), exceeding direct transactions outside of AI marketplaces.
Emerging types of datasets, including synthetic data, can enhance real-world datasets. At the current rate of adoption, we expect synthetic data to play a critical role in the near term to the point where it will become indispensable, as real-world data will not keep up with the demand for training data. This represents a great opportunity for vendors to offer value, especially in situations where high-quality data is needed or real-world data cannot be used or sourced. Moreover, synthetic data can play an important role in enhanced reasoning. There is an opportunity to create a wide range of scenarios with synthetic data, including edge cases that are not available with real-world data. With these extended scenarios, the system can learn broader concepts and therefore exhibit strong reasoning capabilities by handling rare and extreme cases.
Applied GenAI Will Concurrently Enhance Existing Experiences While Enabling New Use-Cases
Applying GenAI in practice includes:
- GenAI virtual assistants
- Agentic AI
- GenAI API extensions
- AI molecular modeling
- GenAI-enabled apps
- Intelligent simulation
- AI code assistants
Higher performance, parameter efficient models will enable new use cases, particularly in resource-constrained environments. We expect a myriad of new applications to emerge over the next three years, some of which will enable new use cases, while others will enhance existing experiences. Prominent examples include agentic AI and polyfunctional robots. We expect new applications, such as workflow tools and agentic AI, to have a fundamental impact on how people work and complete tasks.
Advanced simulation techniques, such as simulation twins, will eventually enable test environments to operate at a fraction of the cost and time required for testing in the real world. An increasing number of organizations are focusing on augmenting existing software and solutions with GenAI.
Figure 1 depicts the 22 emerging generative AI technologies and trends across the 4 different themes in the respective quadrants.
The Impact Radar
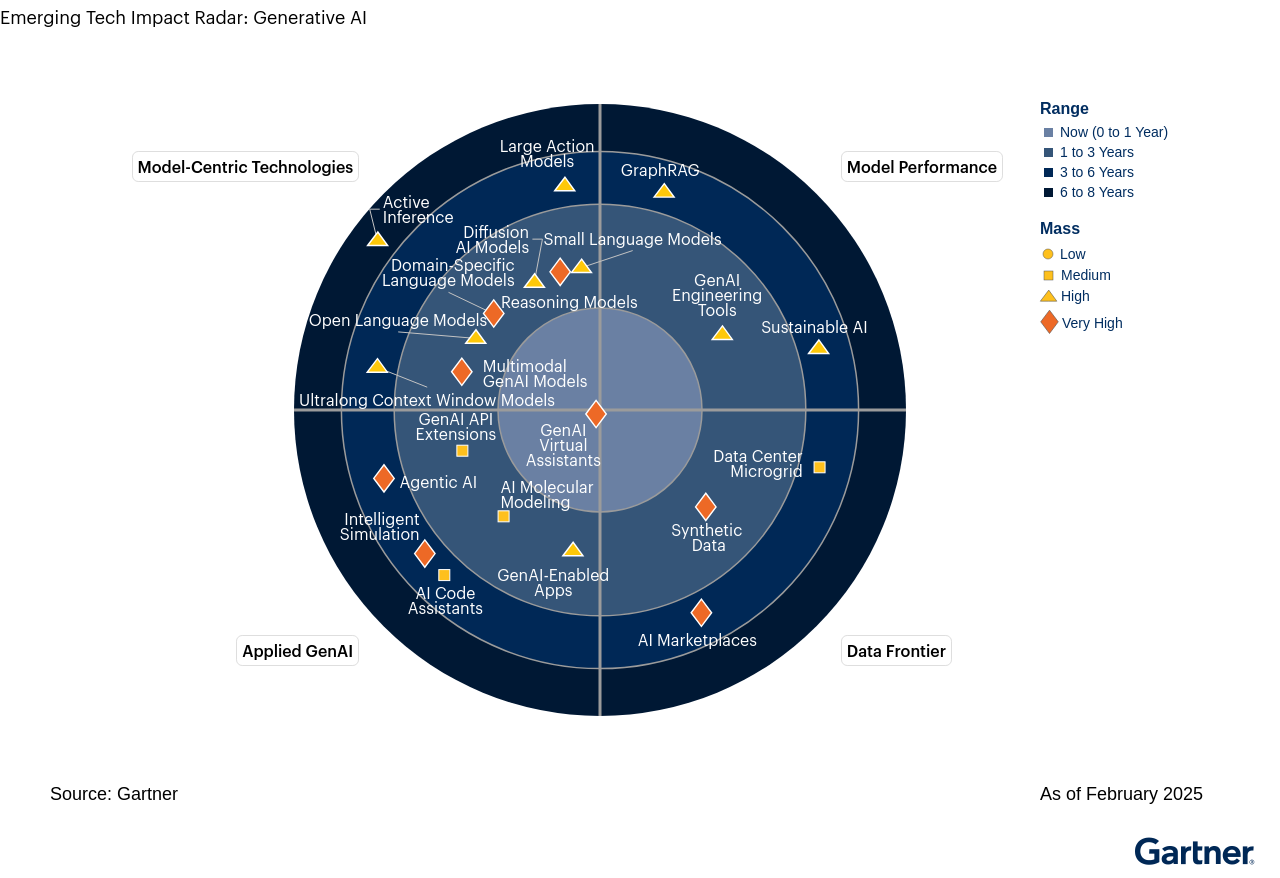
Product leaders should use the Radar Profile range to plan investment timing in the related emerging technology or trend (ETT). “Range” represents Gartner’s estimate of time to reach early majority (more than 16% target market adoption), not when product leaders should act on investment. Considering time to plan, develop and launch, a starter guide to product leader investment timing, based on product strategy, is as follows:
- First movers should be acting now on items in the 6-to-8-years ring (or beyond).
- Fast followers should be acting now on ETTs in the 3-to-6-years ring.
- Majority followers should be acting on ETTs in the Now and 1-to-3-years rings.
- Laggard followers can wait until the ETT has passed through to early, or even late, majority.
Refer to the About the Impact Radar section for more information.
Emerging Technologies or Trend Profiles
Priority Matrix for Generative AI
| Mass | Range | |||
|---|---|---|---|---|
| Now (0 to 1 Year) | 1 to 3 Years | 3 to 6 Years | 6 to 8 Years | |
Very High | ||||
High | ||||
Medium | ||||
Low | ||||
Source: Gartner
Now
GenAI Virtual Assistants
Analysis By: Danielle Casey
Definition:
Generative AI (GenAI) virtual assistants (VAs) represent a new generation of VAs that leverage large language models (LLMs) to deliver functionality not obtained with traditional conversational AI technology. GenAI enables improved Q&A support, new features and modalities, extended task automation and improved value outcomes.
Sample Vendors
Aisera; Google; Haptik; IBM; Kore.ai; Leena AI; OneReach.ai; Openstream.ai; Ushur
Range: Now (0 to 1 Year)
The range for GenAI virtual assistants is “now” because they have emerged as one of the foremost applications of GenAI technology within the organization.
Large language models have materially augmented VAs to enable new capabilities and enhance the quality of outputs, with leading providers having already productized or at least piloted GenAI capabilities in their VAs. However, adoption of GenAI VAs varies by industry, use case and organizational risk tolerance.
Despite the growing popularity of GenAI VAs, 2024 adoption rates have not yet surpassed early majority customer adoption (16% of the target customer base). This is expected to change in 2025 as trust in GenAI VAs and their performance improve.
There are different approaches to incorporating an LLM into a VA. They include chaining multiple LLMs, embedding an out-of-box model into an offering, using an architecture based on retrieval-augmented generation (RAG), model fine-tuning, retraining or otherwise customizing an LLM for use. Each option must be evaluated against performance requirements, implementation time and costs.
Gartner predicts that by 2026, GenAI will be embedded in 90% of conversational AI offerings, up from 50% in 2024.
Both venture capital firms and established conversational AI tech providers are driving significant investments in GenAI VAs, leading to rapid market growth and a rapidly changing competitive landscape. There are several drivers and inhibitors impacting GenAI VA adoption.
GenAI VAs are being driven by:
- Customer demand for GenAI: GenAI hype has organizations wanting to pilot the technology. GenAI VAs are popular as the VA use cases and KPIs are well-defined and the need to improve customer or employee support may already be recognized.
- Vendors rapidly pivoting and repositioning offerings: Many VA providers have preexisting knowledge graphs, indexed vector databases and in-house technical expertise. Coupled with existing high-performing out-of-box models, repositioning VAs as “GenAI-enabled” is achievable for most vendors.
- LLM-enabled capabilities and value: Vendors are incorporating LLMs into their VA offerings to support more advanced Q&A, provide summarization and generation capabilities, and expand language and modality support. GenAI VAs promise improved value outcomes over their non-GenAI counterparts due to higher Q&A resolution rates.
Obstacles inhibiting adoption include:
- Accuracy: Low accuracy translates into poor VA performance and value outcomes, presenting a significant challenge in scaling adoption. Many vendors are actively investing in improving accuracy, hallucination detection and mitigation techniques.
- Customization requirements: To unlock value, GenAI VAs must be connected to customer data via RAG and prompt engineering, data vectorization, model fine-tuning, or other techniques, requiring customer education, budget, skills, custom integrations and data-readiness.
- ROI: Tokenization and generative inferences are changing VAs’ cost structure. Difficulty proving ROI may slow adoption of new offerings versus traditional VA offerings priced on a consumption basis.
- Privacy and security: Privacy and security concerns may necessitate stricter model hosting and data integration requirements.
- Responsible AI: GenAI explainability and model maintenance and monitoring tools will help address accuracy, reliability and compliance concerns and drive usage.
Mass: Very High
The mass for GenAI virtual assistants is very high because of their expected impact across all industries, multiple use cases and many different business functions.
GenAI virtual assistants are being adopted across all industries, though the pace of change and the nature of implementation vary by regulatory environment.
Typically, internal-facing GenAI VAs are the first to pilot, with use cases around employee self-service, information discovery and generation, and intelligent agent assist for call center operators.
External-facing GenAI VAs that support B2C engagements may be pursued after internal-facing GenAI VAs have gone into production and some of the aforementioned inhibitors have been addressed. Some industries (such as retail and media, communications and services) are more receptive to external-facing GenAI VAs than others (such as financial services and healthcare) due to perceived risk.
Generative AI will transform virtual assistant offerings by:
- Enabling complex conversational dialogue with greater contextuality. GenAI VAs capable of handling more complex user requests can improve user self-service and satisfaction rates, reducing call center volumes and associated costs.
- Extending automation beyond Q&A support to content discovery and creation, and analytics capabilities.
- Supporting multimodal interactions (beyond text and voice) to include image, video, code and unstructured data (such as emails, PDFs and websites).
VA providers that enhance their products with GenAI may also offer new services to support data readiness and solution development.
Recommended Actions
- Reduce adoption inhibitors by prioritizing technology investments that will improve model and application accuracy and, therefore, solution performance.
- Drive and scale GenAI VA adoption by developing offerings that solve use-case- or industry-specific business problems and deliver measurable value.
- Differentiate in a GenAI-washed market by investing in LLM accuracy and controls, responsible AI features, multimodal capabilities or advanced analytics tools.
Gartner Recommended Reading
1 to 3 Years
AI Molecular Modeling
Analysis By: Reuben Harwood
Definition:
AI molecular modeling is the application of artificial intelligence techniques to predict and analyze the 3D structures, interactions and properties of molecules. It significantly reduces the time and cost of drug discovery, while enabling the analysis of innovative compounds, which would otherwise have been overlooked or considered too risky to explore. In the life sciences industry, AI molecular modeling underpins a shift from trial-and-error to precision engineering of therapeutics.
Sample Vendors
Dassault Systèmes; DeepMind; Cadence; Chemical Computing Group; Fujitsu; Insilico Medicine; NVIDIA; Schrödinger
Range: 1 to 3 Years
The range for AI molecular modeling is one to three years because the value of AI molecular modeling output continues to be scrutinized, requiring more data and new operating models to fully implement these approaches.
Early adopters are already benefiting from the implementation of AI molecular modeling, with preliminary use cases in protein engineering, drug development and repurposing, biomarker discovery and personalized medicine. Leading pharmaceutical companies have established billion-dollar partnerships with AI-native drug discovery companies, and the software market in this space is also rapidly expanding.
Training AI for molecular modeling is still expensive, time-consuming and held back by the availability of high-quality biological data. Further work needs to be done to integrate these computational approaches with wet lab validation of AI-generated output. However, AI models greatly accelerate development timelines and reduce costs, raising high expectations in the R&D community. The requisite redesign of R&D workflows and implementation of new operating models is expected to take another 18 to 24 months.
Accumulating evidence that AI molecular modeling can help compress the time and reduce the cost of drug development is garnering interest and investment in this technology. Early analysis of AI-discovered drugs in clinical trials showed an 80% to 90% success rate in Phase I, when the drug is tested with a small group of people for the first time. (See How Successful Are AI-Discovered Drugs in Clinical Trials? A First Analysis and Emerging Lessons, Drug Discovery Today.) This is substantially higher than historic industry averages. AI molecular modeling is accelerating the rate of drug discovery to the point where it will rapidly become mandatory for companies wishing to remain competitive. This technology is growing fast, in part due to advances led by big tech companies, including Google DeepMind and NVIDIA.
Mass
The mass for AI molecular modeling is medium. While AI molecular modeling and computational drug discovery as a whole are likely to transform life sciences R&D, this technology has limited relevance outside of the life sciences, chemicals and materials engineering sectors.
While the applicability of AI molecular modeling is focused, the advancements within life sciences, chemicals and materials engineering underscore its critical role in these fields, making it indispensable for future innovations and breakthroughs. Notably, the Nobel Prize in Chemistry 2024 was awarded to David Baker (University of Washington, USA), Demis Hassabis and John Jumper (DeepMind) in part for developing the AI model, AlphaFold2, which predicts proteins’ complex structures. In materials engineering, AI molecular modeling can accelerate discovery and optimization of new materials with specific, tailored properties such as enhanced strength, durability, thermal resistance or electrical conductivity.
In an industry where 90% of trials fail, any technique that can reduce the cost of drug development and improve the success rate of clinical trials will have a significant impact. Existing projects have a strong emphasis on proving the viability of the technique, for example, by focusing on targets with validated biology. But momentum in this field will see a rapid uptick as the first wholly AI-designed-and-developed drugs proceed through clinical trials and gain regulatory approval, which we expect to happen within the next two to three years. Still, there are several hurdles to address:
- AI molecular modeling requires high-quality, extensive datasets to train sophisticated algorithms
- It is computationally intensive requiring cloud-based infrastructure and high-performance computing (HPC)
- It mandates expertise in both AI and specific scientific domains (for example, protein biology, materials science).
Recommended Actions
- Identify parts of the drug development process where the implementation of broader AI-enabled techniques will have the maximum business value by partnering with stakeholders to understand current inefficiencies and future opportunities.
- Help drug development companies differentiate by assisting in customizing their models and integrating proprietary data into the training process, via connections with common laboratory platforms (e.g., laboratory information management systems [LIMS], electronic lab notebook [ELN])
- Prioritize transparency in AI model performance and the explainability of AI output to guide scientist decision making.
Gartner Recommended Reading
Diffusion AI Models
Analysis By: Roberta Cozza, Radu Miclaus
Definition:
Diffusion models are generative models that use probabilistic variation to add noise to data (for example, blurring an image) and then reverse the process (clearing of the image) to generate new samples of data. Diffusion models have proven more effective than generative adversarial networks (GANs), especially in applications related to image/video processing, synthesis and summarization, and computer vision.
Sample Vendors
Adobe; Baidu; Google; Hugging Face; Midjourney; OpenAI; Shutterstock; Stability AI
Range: 1 to 3 Years
The range for diffusion models to reach early majority adoption is one to three years because applications targeted for creative content creation and synthetic media are already available and are adopted rapidly.
These models are evolving rapidly both in their capability to refine image and video generation, achieving higher resolutions and photorealism. Since the introduction of OpenAI DALL·E and earlier models, more diffusion models and applications for content generation have increasingly entered the market. These applications, which include multimodal type outputs (such as avatars, video and others), are penetrating both the consumer and enterprise sectors, thereby intensifying competition. Recently, there has been a surge in efforts to create diffusion models capable of running on-device in smartphones for tasks like text-to-image generation or enhancement of computational photography. Initiatives like Google’s MobileDiffusion and others, along with efforts in graphics processing unit (GPU) optimization to execute diffusion models locally, exemplify this trend.
The creative user community has seen rapid growth in the experimentation with diffusion model-based applications. Concurrently, there is increasing scrutiny and concern regarding intellectual property (IP) protection, particularly around generative outputs produced from models trained on protected content. This can expose companies to IP infringement litigation. Regulations around IP protection, along with self-regulation of vendors of models and applications, continue to evolve and adapt to the pace of change. In addition to this, ethical considerations are paramount in order to ensure diversity in the visual data used to train diffusion models to avoid perpetuation of social or cultural biases.
Mass: High
The mass for this technology is high because it can be applied to multiple areas and industries.
These models can produce high-quality synthetic media, creating realistic and compelling content for applications ranging from entertainment and marketing, to education and training. They enhance the professional’s ability to generate and edit visual content, extending beyond creative sectors like marketing and media to unlock new opportunities in fields such as life sciences and intelligent simulation.
While application in the image generation and editing has been one of the front-running applications of diffusion models, the use cases for diffusion models include:
- Image processing — generation, resolution, restauration, editing, anomaly detection.
- Computer vision — synthetic image and video generation, semantic segmentation, resolution.
- Multimodal generation — text-to-image, text-to-3D, text-to-motion, text-to-video, text-to-audio/sound.
- Natural language processing — various use cases.
- Temporal data processing — time series data imputation, forecasting, anomaly and signal detection.
Beyond the rapid generation of images or videos from text prompts, which finds applications in media, gaming and marketing, diffusion models are increasingly contributing to other fields. Their growing impact is evident in applications based on sequences and connections like material design, medical image processing, biochemistry applications — encompassing industrial and life science applications. In particular, these models can be used for the generation and support of GenAI-driven simulation of molecule and protein structures, impacting fields like drug discovery, for example. Other opportunities are in the area of simulation and modeling of networks, environment and construction.
Diffusion models will enable transformational capabilities in the democratization of visual content-generation capabilities. These will enable critical optimization and time savings in creative tasks and workflows, both within enterprises and across a variety of creative industries. The evolution of future models will further enhance sophistication of content output. In addition, we see continuous investment aimed at enhancing the efficiency and maintenance of diffusion models, with a focus on optimizing them to limit their substantial computational requirements.
Recommended Actions
- Advance the content creation capability for enterprise software with human-augmentation capabilities by exploring both open-source and proprietary diffusion models to benefit from GenAI-enabled productivity experimentation.
- Build or integrate with models developed in an ethical manner, ensuring that they are free from exposure to IP-protected content. This approach will provide a competitive advantage in enterprise use cases that are focused on mitigating such risks.
- Invest in superior prompt engineering experience and a support community to share best practices for refining the completion from diffusion model-based applications.
Gartner Recommended Reading
Domain-Specific Language Models
Analysis By: Ray Valdes, Danielle Casey, Akhil Singh
Definition:
Domain-specific language models (DSLMs) are designed to address knowledge requests within a particular area, including functional domains (such as sales, HR, marketing or research), industry domains (such as finance or retail) and use cases (such as recruitment or lead generation). They are trained on focused datasets representative of the specific domain. Because of their focused nature, they can be valuable as constituent elements of agentic solutions (broad systems that combine and take action across multiple domains). Unlike general-purpose models such as GPT4 or Gemini, which have been exposed to a wide range of topics, these models focus on specific areas. Although an industry refers to a particular economic sector (such as manufacturing or healthcare), a domain is a more general field of study or activity — such as sales, HR, marketing or research — that can be found across various industries.
Sample Vendors
Jasper AI; Oracle; SAP; Salesforce; ServiceNow; Workday; Writer; Zendesk; Zest AI
Range: 1 to 3 years
The range for DSLMs is one to three years because of rapid model proliferation, including those incorporated into legacy applications as well as those from pure-play generative AI (GenAI) startup vendors.
Domain-specific models have proliferated over the past year, and this trend will continue: The entire tech sector is pivoting to incorporate generative AI into their products and services.
For example, the sales function is found in many industries, in roughly the same pattern, with some variations. Historically, the sales function in an enterprise has been supported by enterprise applications (such as Salesforce CRM) that target that domain. Legacy enterprise CRM applications have more recently been augmented by domain-oriented models. In addition, there are emerging GenAI-intensive solutions that use domain-oriented models. Established vendors of legacy applications (in categories such as CRM, ERP, IT service management [ITSM] and human capital management [HCM]) have added or are adding generative-AI-based capabilities. In addition, there are a host of new tech startups creating and launching solutions based on domain-oriented models for human resources, sales, research, marketing, accounting, legal and research.
The speed at which GenAI capabilities are being added to domain-oriented solutions is rapid because the technical effort is relatively low for the first wave of GenAI augmentation. In the simplest case, it is technically straightforward to embed a text window into an enterprise application that launches a conversation with a large language model (LLM) through an API. This approach provides only limited incremental value to the user. The next step is multipoint integration in various workflows, such as generating a draft email to a prospect, generating a summary of an interaction, or prioritizing a dataset based on conversational input. This kind of augmentation provides more value, but is still incremental in nature. Progressing further, deeper use of GenAI in a domain-oriented application can transform high-value, inefficient processes and make them faster and more effective. This could result in significant productivity benefits, cost reduction and, in some cases, increased revenue.
Mass: Very High
The mass for DSLMs is very high because of their ability to leverage vast amounts of data within a specific domain to generate results that are impactful, relevant and accurate. Though near-term value will be incremental, as the technology matures and industry specialization deepens, these systems will evolve to reinvent business processes.
Domain-specific models can be quite focused. For example, an LLM for the oil and gas (O&G) industry may have knowledge of O&G practices in sales, shipping, refinery operations, geologic sampling, environmental regulations and reports. This industry-specific LLM can support a range of functional areas or domains within that industry sector, possibly including sales, HR and accounting functions (hence the overlap). The overlap is why, in some cases, it may be hard to distinguish a functional-specific LLM versus an industry-specific LLM. Further examples of utility are:
- Medical image analysis: Analyze X-rays, EKGs or other lab results and correlate diverse datapoints
- Language translation for human languages that are not widely used, or for industry domains that have specialized vocabularies
- Drug discovery: Identify potential drug candidates and predict their properties
- Legal contract analysis and generation
- Financial analysis and forecasting: Analyze financial statements and reports, and generate a financial model that enables prediction of future results
- Fraud detection: Correlate diverse datasets to identify fraudulent transactions and bad actors
- Credit scoring and risk assessment: Evaluate the credit-worthiness of individuals or businesses
- Marketing campaign: Generate plans for online advertising that will produce optimal results
- Content creation: Write blog posts and social media posts for product vendors
- HR job applications: Evaluate resumes and generate draft response emails
Initial use of domain-specific models is incremental in nature: They are used to incrementally automate or improve certain workflows in established applications. This is because the domains in question (such as sales, HR, finance or marketing) are well-understood and have been well-served by legacy applications (such as CRM, HCM and ERP). Established vendors in those categories have added or are adding generative AI capability. The first wave of improvements will deliver incremental benefits, making some specific tasks (such as drafting a letter to a prospect) more efficient.
As the technology matures and understanding of the problem deepens, high-value business processes and workflows could be significantly transformed, and this could lead to more impactful benefits. Also, within a domain, there will regularly emerge new workflows and tasks that are not well-served by legacy applications and can be addressed by GenAI products that use domain-oriented models. Examples include managing online advertising campaigns or undertaking credit scoring for individuals who have limited credit histories. These emerging pockets of opportunity could grow to have a significant impact on the business.
Domain-specific models benefit from some overlapping trends in models: small models, open-source models and industry-specific models. These trends can make it easier and cheaper to build domain-specific models and get effective results. Domain-specific models can benefit from the recent trend of small models, which are often open-source and can run on-premises or in colocated hosting. Though linked, small models are not essential to meeting the requirement of domain specificity. Synthetic data generation can also accelerate time to market by reducing the need for large domain datasets.
Recommended Actions
- Within a domain, analyze business processes and workflows to identify high-value processes that can be made more efficient, or whose timelines can be accelerated, in order to deliver significant business value.
- Conduct a thorough inventory of all data within a domain — including traditional structured data controlled by legacy applications as well as unstructured data (such as documents, emails, meeting transcripts, voicemails and focus group raw data) that can be ingested into a domain-oriented model — so that it can produce relevant and effective output.
- Evaluate and deploy tools, techniques and technologies such as open models, small models, Low-Rank Adaptation (LoRA) and related fine-tuning advancements that can greatly facilitate the task of building and using domain-specific models.
Gartner Recommended Reading
GenAI API Extensions
Analysis By: John Santoro, Jim Hare
Definition:
Generative AI (GenAI) API extensions augment the capabilities of GenAI models by giving them the ability to retrieve real-time information, incorporate company and other business data, perform new types of computations and safely take action on a user’s behalf. GenAI extensions indicate, via their metadata, the types of prompts that they support. They map keywords in those prompts to API calls that can access information or take actions that otherwise could not be performed by the GenAI model.
Sample Vendors
Adobe; AppDirect; AWS; Google; Microsoft; Nuance; OpenAI; SAP; Zapier
Range 1 to 3 Years
The range for GenAI extensions is one to three years because the technology has become simpler to implement and technology providers need to invoke APIs to make large language models (LLMs) useful in the context of their product experiences.
Providers initially created extensions to connect their content to the user interface tool associated with the LLM. But, the majority use case quickly has become application providers embedding LLMs into their products via API. As a result, users will enter a prompt within a product’s user interface and not even be aware that the prompt is executed by an LLM (or which one is used) with GenAI extensions to give it product-specific capabilities.
GenAI models need to invoke APIs to take action or to access data that changes more frequently than the model can be updated. Therefore, the simplicity with which GenAI models support API extensions will affect the speed of adoption by product providers and independent software vendors. A lack of a standard extension architecture across AI models will inhibit adoption, as providers and developers will have to reproduce some portion of their effort developing, testing, supporting and maintaining API extensions for multiple GenAI models.
Mass: Medium
The mass for this technology is medium, because not all providers will need API access. They may not need to access real-time data or to take action via APIs, and some will use custom models or chatbots to achieve the same result without extensions.
GenAI plug-ins offer the potential to be used across industry verticals by automating tasks, enhancing creativity and delivering personalized experiences at scale. In healthcare, they can streamline medical reporting, diagnostics and drug discovery, while in finance, they can automate financial analysis and improve fraud detection. Retail and e-commerce can benefit from AI-driven product descriptions and inventory optimization, whereas manufacturing could see gains in product design, predictive maintenance, and supply chain management. Media, entertainment and education could leverage AI for content creation and adaptive learning, while legal, real estate and human resources sectors could use it for document generation, market insights and candidate screening. Across marketing and advertising, AI promises to boost campaign efficiency with personalized content and real-time performance analytics.
The impact of this technology also will depend on the simplicity of employing API extensions, including whether LLMs provide a marketplace for customers to discover extensions that they wish to buy.
Vendors are increasingly investing in GenAI plug-ins by developing flexible, modular tools that can be easily integrated into various platforms and applications. They are focusing on creating plug-ins that support a wide range of use cases, from content creation to personalized recommendations, to cater to diverse industry needs. Many vendors are also building extensive developer ecosystems, offering APIs and software development kits (SDKs) to enable customization and scalability. Also, they are enhancing plug-in capabilities by incorporating advanced AI models and ensuring compatibility with popular software environments aiming to provide seamless user experiences and accelerate adoption.
Recommended Actions
- Create a GenAI extension to enhance a product that uses an LLM but requires dynamic information or needs to take actions.
- Verify the accuracy of the information an extension provides before attempting to use it. AI accuracy and hallucinations remain common issues with GenAI models so consider supporting guardrails.
- Identify whether supporting multiple LLMs or BYO LLMs would be useful, weighing portability across models and licensing costs to determine potential feasibility and profitability.
Gartner Recommended Reading
GenAI Engineering Tools
Analysis By: Eric Goodness
Definition:
Generative AI (GenAI) engineering tools enable enterprises to operationalize development models faster, balancing both governance and time to market. AI engineering tools can be subdivided into model-centric and data-centric tools. There are numerous terms, such as DataOps, LLMOps, LangOps, FMOps and, more broadly, ModelOps and MLOps, that are used frequently to refer to AI engineering but are really subsets of AI engineering. Prominent tool categories specific to GenAI engineering include prompt engineering, vector and graph databases, model fine-tuning, model deployment, application frameworks, and AI trust, risk and security management (TRiSM) tools.
Sample Vendors
C3 AI; DataRobot; Fiddler AI; Holistic AI; Humanloop; IBM; OctoAI; Palantir; Snorkel AI; Weights & Biases
Range: 1 to 3 Years
The market for GenAI engineering tools will reach early majority adoption in one to three years. GenAI engineering tools make up a fast-emerging, critical set of middleware necessary for developing and managing GenAI technologies to achieve business goals. The emergence of purpose-built software to support the life cycle requirements of generative models is key to the technology’s adoption.
Despite the utility of these tools, the marketplace is highly fractured, with a set of existing data science and machine learning/MLOps software, and a large number of specialty tools brought to market by a growing collection of startup software companies. Very few providers offer end-to-end platforms to manage the life cycle of LLMs. Many enterprises lack experience in operationalizing GenAI, and this is magnified during the due diligence process of choosing the right tools for their GenAI projects and initiatives.
This presents users with the decision of whether to accept “good enough” solutions with legacy providers or to engage in extended due diligence with a marketscape of emerging and innovative providers where viability and a deep pool of references are concerns.
Despite the challenges of this emerging market, there is a stabilizing element where coalescing ecosystems of large and small providers of GenAI engineering tools are partnering with large independent software vendors (ISVs) and hyperscalers in their AI marketplaces and model hubs.
Mass: High
The impact of GenAI engineering tools is high as the software is the main catalyst for the development, monitoring and operationalization of generative models.
GenAI engineering tools are critical for developing and managing GenAI technologies to achieve business goals. In short, GenAI engineering tools are the picks and shovels to the GenAI gold rush. Some of the valuable capabilities offered by GenAI engineering tools include:
- Steering models without incurring significant retraining costs
- Enabling applications to respond with low latency to high concurrency requests (prompts)
- Fine-tuning base models for task specificity, higher model performance and fewer hallucinations
- Orchestrating workflows by chaining prompts or models together to achieve intended outcomes
- Protecting against loss of intellectual property, hallucinations, a lack of model explainability, bias and toxicity in model output, and misinformation
- Providing AI observability for GenAI-enabled systems and applications
- Optimizing models through techniques such as quantization and low-rank adaption (LoRA), among others
The tools will affect all sectors and businesses operationalizing GenAI directly or indirectly. GenAI engineering tools that embody end-to-end foundation model operations (FMOps) capabilities would help organizations pave a clear path from data preparation to experimentation, and then to model deployment and production monitoring.
Because of the proliferation and use of GenAI, it is expected that many different product types, which did not offer organic MLOps prior to the emergence (commercialization) of GenAI, may integrate one or many elements of the toolsets, such as data preparation, model development, prompting, model deployment, model monitoring and governance. Gartner believes that over the next 24 months, there will be a huge increase in the acquisition of these smaller, pure-play tool providers by hyperscale providers and larger ISVs and legacy data science and machine learning platform companies.
Recommended Actions
- Speed up bottom-up adoption to accelerate sales cycles and promote growth and advocacy by exploring product-led growth initiatives focused on developers and citizen data scientists.
- Engage in GenAI ecosystem partnerships to enhance your offerings by collaborating with providers that supplement and complement capabilities when offering single-purpose tools, such as model fine-tuning, model deployment or prompt engineering.
- Create demand for your GenAI engineering tools by demonstrating capabilities to add value with both closed- and open-source models and model hubs.
Gartner Recommended Reading
GenAI-Enabled Apps
Analysis By: Annette Zimmermann, Radu Miclaus
Definition:
Generative AI (GenAI)-enabled applications use generative AI for user experience (UX) and task augmentation to accelerate and assist the completion of a user’s desired outcomes. When embedded in the experience, generative AI offers richer contextualization for singular tasks like generating and editing text, code, images and other multimodal output. As an emerging capability, process-aware generative AI agents can be prompted by users to accelerate workflows that tie multiple tasks together.
Sample Vendors
Adobe; Amazon Web Services (AWS); Google; INFORM Software; Microsoft; OpenAI; Salesforce; ServiceNow; UiPath; Uniphore
Range: 1 to 3 Years
The range for generative AI-enabled apps is one to three years from early majority customer adoption, as the majority of B2B software vendors are either planning to, starting to or have already implemented, GenAI capabilities into their software experiences.
B2B GenAI-enabled applications are already in production and accessible in general availability, preview or beta stages. These applications span across multiple productivity domains, including text editing, creative design support, as well as software engineering tasks like coding and low-code/no-code applications. Independent software vendors (ISVs), encompassing both incumbent vendors in the hyperscalers, SaaS providers as well as specialized vendor startups and scale ups are actively announcing ongoing roadmaps. These plans focus on integrating new GenAI capabilities into their applications for the second half of the year.
The rapid adoption of GenAI-enabled apps by both end users and tech providers alike, coupled with the growing number of offerings from both major tech companies and startups suggests that early majority adoption may be imminent. We expect continuous investments in this area by both startups and large tech. This is both induced by vendors offering software such as virtual assistants that are migrating the underlying technology to large language models (LLMs) as well as the development of brand new software powered by GenAI.
Despite these fast developments, some challenges remain. The main challenge with GenAI-enabled applications lies in the nature of “upgrading” a legacy application with next-generation technology. The user organization is often not prepared in terms of cultural readiness as well as data readiness. The former relates to employees’ concerns regarding whether the new GenAI application could potentially replace them, which may lead to delays in adoption. The latter arises from the fact that many organizations do not possess AI-ready data because a common data structure simply does not exist. This and eliminating data silos are needed to drive adoption of the low-hanging fruit in GenAI, such as enterprise search, virtual assistants and the automation of manual tasks (like summaries and reports).
Mass: High
GenAI-enabled applications are projected to achieve a high mass due to their pervasive application throughout the entire technical stack, their applicability across horizontal and vertical use cases, and their broad adoption across industries.
GenAI-enabled application providers are designing experiences that focus on ease of adoption and scale onboarding for users, without forcing steep learning curves. These experiences are either augmented from current task workflows or completely redesigned for intuitive and easy-to-use interfaces, for example, conversational interfaces for users. The increased democratization afforded by GenAI-enabled applications will lower the technical barriers for operating applications, increasing the volume of users and interactions within applications.
Technology advancements are made continuously by augmenting existing applications with LLMs in combination with other capabilities and techniques, such as knowledge graphs, reasoning, plug-ins and retrieval-augmented generation (RAG). For example, for the development of an advanced semantic search solution leveraging GenAI for a large pharma company, the generative pretrained transformer-3 (GPT-3)-based model extracted information from medical research articles. The RAG architectural pattern was used on a library of 2,000 historical papers to ensure sources were delivered along with result output. The process of extracting the most relevant information from medical research articles was previously a manual process. With the enhancement of the LLM-powered search solution, process efficiency increased tenfold, reducing manual effort significantly. Accuracy and lack of short-term memory in extended chat conversations, as well as effective guardrails, remain challenges that could potentially lower the overall impact of embedded-GenAI applications. As demonstrated in the aforementioned example, there are tools and techniques available that contribute to organizations’ transparency and reliability efforts.
Recommended Actions
- Prepare your clients for GenAI by offering data advisory services, including data integration management and data governance, or by facilitating access to such services via a third party. A strong data strategy will prove critical to the success of any GenAI application project.
- Help your clients overcome cultural barriers to the adoption of embedded GenAI applications by actively getting involved and directly supporting change management within those organizations.
Gartner Recommended Reading
Multimodal GenAI Models
Analysis By: Roberta Cozza, Danielle Casey
Definition:
Multimodal GenAI provides the ability to use multiple types of data inputs and outputs — such as images, videos, audio (speech), text and numerical data — within a single generative model. Multimodality augments the usability of GenAI by allowing models to interact with and create outputs across data in various modalities. Today, many multimodal models offer processing across two or three modalities (e.g., text-to-video or speech-to-image). This will increase over the next few years to include more modalities.
Sample Vendors
Anthropic; Apple; DeepSeek; Google; Meta; Microsoft; Mistral; OpenAI
Range
The range for multimodal GenAI is one to three years from early majority adoption due to the accelerated availability of general-purpose multimodal large language models (LLMs) from hyperscalers mainly and some smaller players. In addition, we are seeing the increased availability of smaller multimodal GenAI models built around domain-specialized content.
Multimodality scales the benefits of GenAI across potentially all data types and applications. It removes traditional unimodal data barriers by allowing users to interact with, manipulate, and create outcomes from numerous data types typically used in different business environments.
Early models have mainly been about processing two or three well-understood modalities as inputs, and generating outputs that mainly include text, speech, images and video. Over the next few years GenAI models will include additional modalities, as well as more advanced techniques for training on video data and analytics generation.
During the past year we have seen more investment from all key players in extending the multimodal capabilities of their large language model (LLM) offerings, both for generic-knowledge LLMs and domain-specific models. Multimodal GenAI models bring key benefits:
- Increased accuracy: Since multimodal GenAI models do not depend on one modality, they can provide responses that are richer and have more context.
- New applications: The ability to process and ultimately analyze data from various modalities opens the door to new or more innovative applications (such as multimodal questioning/retrieval, or video generation from text input).
- Augmented capabilities: Cross-modal information and reasoning helps identify complex patterns (i.e., emotion, intent nuances) to increase the relevance of GenAI models’ responses.
- Rise of specialized multimodal models: Models trained on data about specific industries and business functions that are intrinsically multimodal (e.g., legal, finance, healthcare, marketing and multimedia) will be able to enhance productivity and add new value in these areas.
Multimodal GenAI models are not easy to build or integrate. They can be costly as they are computationally heavy and require disparate types of data. Faster adoption is currently inhibited by the following challenges:
- Training challenges: Multimodal GenAI models use deep learning, data alignment and fusion techniques to train on and integrate data sourced from the multiple modalities. Multimodal data can have varying degrees of quality and formats versus unimodal data; in addition, data may be limited in some modalities. For example, the availability of 3D images or large-scale audio datasets is more limited compared to other modalities like 2D images and text.
- Risk of privacy violations: Multimodal GenAI increases the exposure to a wider range of sensitive data, potentially increasing data privacy concerns. This is important as more government regulations will be increasingly in place and demand transparency in the use of sensitive data for model training.
- Data management: Keeping multimodal data with varying degrees of quality up to date, clean and accurate is a more complex task than for unimodal data.
- Bias and inaccurate or fabricated outputs: The risk of such outputs is potentially amplified by multimodal data sources.
Mass
The mass for multimodal GenAI is very high because it supports the creation and expedition of new tasks, workflows and applications, such as extracting multimodal data, converting one data type to another, and creating new data outcomes. Applications that support multimodality will have higher automation potential across industries.
Over the next one to three years, multimodal GenAI models will increasingly appear in more and more applications, as the future of GenAI is multimodal. Emerging use cases include the following:
- Data and analytics (D&A) by supporting the manipulation of text, numerical, voice and visual data to glean insights.
- Multimodal content and website creation, including website design, product descriptions and images, and content creation for the marketing function or e-commerce applications.
- Visualization of text, graphs and numerical information in data-heavy industries (such as financial services) for D&A support.
- AI avatars (which use multimodal UI layers) used for corporate training or as virtual assistants.
- Multimodal search, in which search engines are leveraging multimodal LMs and natural language processing (NLP) for conversational capability and to deliver more relevant answers or artifacts by handling multimodal data extraction. For example, domain-specific GenAI multimodal models are able to extract and process multimodal information (such as tables, images, graphs and slides) from enterprise knowledge documents.
- Multimodal domain-specific models used for specialized tasks, such as legal research and analysis, or in healthcare handling multimodal patient data to generate treatment plans, or to combining medical images, textual medical records and electronic health records (EHRs).
Multimodal GenAI will have a transformational impact on enterprise applications by enabling the addition of new features and functionality that are otherwise unachievable. These models will have a major impact on the development of industry-specialized applications and services, as they can better support domain-specific LMs and take advantage of multimodal data specific to vertical domains like healthcare, finance, insurance and manufacturing. Multimodality in GenAI models will also help achieve greater accuracy and better decision-making processes for future agentic AI types of applications. These will be highly impactful tools for automating and optimizing employees’ operations and driving more contextual decision intelligence, as agentic AI will be able to proactively take actions in a semi- to fully autonomous way.
Recommended Actions
- Start with your customer use case by assessing what modalities are best aligned to truly optimize workflows, tasks and user experiences via a multimodal model.
- Improve data quality and obtain curated multimodal datasets by assessing how AI marketplaces can be leveraged for quality text, image, video and audio datasets.
- Build or acquire expertise to cover the technical complexities of processing and integrating data inputs and outputs from diverse multimodal sources, and validate early how these can best be integrated with key legacy or more current data workflows.
Gartner Recommended Reading
Open Language Models
Analysis By: Annette Zimmermann, Ray Valdes
Definition:
Open-source language models (OLMs) — or more correctly, “open language models” — are foundation models distinguished by the terms of use and distribution granted to developers. Open language models are publicly available through various licenses that allow one to access, use, modify and distribute different parts of the system. Most open models are, strictly speaking, not “open source” per the definition from opensource.org (Open Source Initiative). Instead, there are degrees of openness depending on access to system components such as training data, training scripts, model architecture, model weights and inference code, and whether the system can be used for commercial purposes. In models that are fully open source, all these components are available for viewing, modification and deployment. This complete openness is found in open-source software packages (such as Linux or Python), but rare in the world of generative AI (GenAI) models. Most GenAI models are not fully open source and are termed “open weight.” These are models for which the pretrained weights are released but the training data, algorithms and architecture remains private.
Sample Vendors
Alibaba; BigCode; Cerebras; DeepSeek; EleutherAI; H2O.ai; IBM; Meta; Mistral; NVIDIA
Range
The range for OLMs is one to three years because open models are closing the gap with commercial proprietary LMs in terms of accuracy, completeness, quality and cost, thereby boosting the rate of adoption.
OLMs are halfway to early majority adoption. The key drivers behind them are increased flexibility, transparency and control, the ease of fine-tuning for small models and the perception that they cost less than proprietary LMs. The perceived cost advantage (“free and open source”) depends on many factors and is not always borne out in terms of total cost of ownership.
OLMs often provide access to developer communities in enterprises, academia and other research roles that are working toward a common goal of improving the models. Organizations can leverage new model architectures and training techniques from open LMs, using them to build additional innovation into their own technology. This collaboration and adaptation makes the models more valuable by improving the speed and quality of innovation, and the increased value drives greater adoption. OLMs often also provide greater transparency than proprietary LMs, which have become more opaque due to increased competitive pressure. OLMs’ greater transparency drives adoption among certain segments of the market that prioritize this aspect.
OLMs often provide access to developer communities in enterprises, academia and other research roles that are working toward a common goal of improving the models. Organizations can leverage new model architectures and training techniques from open LMs, using them to build additional innovation into their own technology. This collaboration and adaptation makes the models more valuable by improving the speed and quality of innovation, and the increased value drives greater adoption. OLMs often also provide greater transparency than proprietary LMs, which have become more opaque due to increased competitive pressure. OLMs’ greater transparency drives adoption among certain segments of the market that prioritize this aspect.
The emergence and growth of open-source communities is driving the adoption of OLMs. Their adoption is going hand-in-hand with the increased use of small language models, on-premises deployments and edge AI. The motivators include the need for cost reduction, increased data privacy, increased flexibility and customization for narrow-scope use cases, and vendor product portfolio augmentation. Vendors and enterprises that value one or more of these attributes are gravitating toward small models run on-premises, which are typically open models such as Llama 3.2 or Mistral. Closed commercial models running in hyperscale clouds remain by far the dominant segment of the market. Open models and small models are growing at a rate that outpaces the broad market, but are ascending from a tiny market share (single digits).
Recent revelations from the open-source community reflect the enormous investments in strategic AI initiatives by the Chinese government and Chinese enterprises. Globally, OLMs like Qwen, DeepSeek and Mistral will serve as the foundation for organizations to improve resource efficiency that will accelerate GenAI adoption.
Adoption challenges for open large language models (LLMs) include the following:
- Investments in data engineering, tooling integration and infrastructure to train and run OLMs can be high. These costs represent a significant fixed cost compared with proprietary alternatives.
- The variety of licensing agreements in open models impedes adoption. Open-source licenses (such as Apache, MIT or GPL) have been adopted by GenAI creators. Some organizations have defined their own variant licenses, with some unique restrictions.
- Model systems’ level of openness varies greatly, presenting trade-offs to anyone studying or adopting an open-source model.
- One specific area of weakness in several of the open-weight models is a lack of transparency in training datasets. While this problem is not unique to open-source LMs, it hinders adoption given enterprises’ increased attention to privacy and ethics.
As measured by various benchmarks, the accuracy gap between proprietary and open-source LLMs is still present, but has narrowed significantly. The remaining gap might not matter, depending on your product’s or service’s requirements.
Mass
The mass for open-source LMs is high because it will improve customization, align with specific enterprise requirements, enhance privacy and security controls, provide collaborative development and model transparency, and reduce vendor lock-in.
This will improve the utility of LMs across multiple industries. Ultimately, many OLMs will offer enterprises smaller models that are easier and less costly to train, and that enable business applications and core business processes.
Increased interest in customization is driving OLM adoption across use cases and industries. The recent industry trend toward growth in domain-specific and industry-specific models and solutions is having an impact, as these are easier to build with small models that can run on-premises, as opposed to large models deployed in the cloud. The small models tend to be open-source rather than closed-source. Financial services, healthcare, and telecom and media are among the leading industries to adopt open (and domain-specific) models.
Open LMs are more customizable than proprietary LMs because engineers can access their model parameters, source code and data. This access gives developers and product leaders more control over costs, output and alignment. By investing in OLMs, enterprises maintain ownership and control, and can continuously develop solutions. This ongoing investment can result in a short-term “moat” against early adopters.
Open LMs are more customizable than proprietary LMs because engineers can access their model parameters, source code and data. This access gives developers and product leaders more control over costs, output and alignment. By investing in OLMs, enterprises maintain ownership and control, and can continuously develop solutions. This ongoing investment can result in a short-term “moat” against early adopters.
Adoption of open LMs is following a trajectory similar to that of closed LMs, with a certain time lag that we expect to close in the next three years. OLMs are advancing GenAI initiatives for both vendors and end-user organizations, and are clearly growing at a robust rate based on recent Gartner interaction volumes and observations of online developer communities. The recent announcements by Chinese vendors offer a trajectory for researchers and enterprises to learn and benefit from. Specifically, organizations can build on the Chinese models’ advanced reasoning capabilities, allowing language models to solve more complex tasks.
There are many robust examples of open LM adoption, such as the following:
There are many robust examples of open LM adoption, such as the following:
- Uber has built a unified platform for all LM use cases within the company, which provides access to both open models (like Meta Llama) and closed models (such as OpenAI GPT4 variants). This platform (Uber GenAI Gateway) is itself open-sourced.
- NVIDIA’s ChipNeMo project is an LM solution built on an open LM (in this case, Llama’s series of small models from Meta) that performs better than the large GPT4 models on technical tasks such as electronic design automation (EDA) script generation. Over time, this system could potentially transform the way the next generation of semiconductor products is built.
- Shopify has added an image generator using an open-source visual language model to assist their customers in creating product illustrations.
- Wells Fargo bank has deployed applications that use open-source LMs for internal uses. Their GenAI platform, called Tachyon, supports multiple models, both open and closed.
Recommended Actions
- Perform due diligence to understand the legal exposure related to training data and the potential biases in LMs. This applies to both open models and closed models.
- Proactively engage with open LM communities as part of the due-diligence process to discern the advantages and drawbacks associated with various models.
- Evaluate different open LMs based on factors such as performance, resource requirements, compatibility and documentation by testing the models on sample data, and compare their outputs against your defined objectives.
Gartner Recommended Reading
Reasoning Models
Analysis By: George Brocklehurst, Ray Valdes, Eric Goodness
Definition:
Reasoning models are an advanced evolution of AI models, capable of performing logical inference, complex problem solving and multistep reasoning. These models utilize chain-of-thought processes and self-reflection to mimic human-like thought patterns, moving beyond simple pattern recognition to understand the underlying structures and relationships within data. Enhanced reasoning capabilities emerge during reinforcement learning, where the model takes feedback on the accuracy and format of its outputs. During this phase, a reward system encourages the development of longer chain-of-thought outputs, which correlate with increased output accuracy. This chain-of-thought reasoning results in significantly more output tokens and, consequently, increased compute demand compared to traditional LLMs. Reasoning models are part of a broader trend toward inference time scaling, an approach intended to continue the improvement of LLM performance. They are designed to tackle intricate queries that require a deeper level of understanding and analytical capacity.
Sample Vendors
AI2; Alibaba; ByteDance; DeepSeek; Kimi; OpenAI
Range: 1 to 3 Years
The range for reasoning models is one to three years because high demand for their advanced capabilities, such as complex problem solving and logical reasoning, will accelerate the knowledge development needed to exploit their capabilities in the field.
The rate of adoption is driven by demand for enhanced capabilities that address the limitations of traditional language models. Reasoning models excel in multistep tasks requiring logical inference, complex problem solving and understanding of context, making them highly valuable in fields like coding, mathematics and scientific reasoning. These enhanced reasoning capabilities are crucial for increasing the autonomy of agentic and multiagent AI systems, allowing them to plan, execute and adapt more effectively. Adoption inhibitors include increased computational overhead due to inference and integration complexity, necessitating improvements in efficiency and user-friendly deployment tools to facilitate widespread use.
In 2024, significant advancements were made in reasoning models, marked by the introduction of new models in the latter part of the year and continuing into early 2025. These developments underscore rapid progress in the field, characterized by reduced training costs and enhanced inference efficiency.
A key trend is the increasing accessibility of these models through platforms that facilitate broader community engagement, thereby accelerating innovation and adoption. This progress has led to widespread excitement and quick integration into major cloud platforms, highlighting the growing demand for advanced reasoning capabilities and a shift toward more autonomous and intelligent AI systems.
Moreover, improvements in reasoning are not confined to large-scale models. A recent initiative by AI researchers demonstrated that core reasoning abilities can be replicated with minimal compute resources, showcasing emergent reasoning behavior in smaller models. Such advancements are expected to further accelerate the adoption of reasoning models across various applications.
Mass: Very High
The impact of reasoning models is very high because they will accelerate the deployment of agentic systems across virtually all industries and businesses.
Reasoning models offer a significant advancement for businesses by providing the unique ability to solve complex problems with high accuracy through a chain-of-thought approach, whereby they analyze and articulate the necessary steps to reach a solution. This capability impacts businesses in two major ways:
- Enhancing agentic systems: Reasoning models improve agentic systems by enabling them to solve complex problems with greater accuracy and autonomy. These models utilize chain-of-thought reasoning and self-verification, allowing agents to make more informed decisions and tackle sophisticated tasks.
- Augmenting human decision making: For humans, reasoning models provide logical, step-by-step analysis to support complex decision making. This allows individuals to concentrate on higher-ROI tasks while AI manages the logical analysis. The collaboration between human creativity and AI analytical skills ensures superior outcomes.
Reasoning models are poised to have a significant impact across all verticals and businesses due to their enhanced, domain-agnostic capabilities. While their core abilities are applicable across various fields, their performance can be further optimized through domain-specific fine-tuning or by providing context via retrieval-augmented generation. This adaptability ensures that reasoning models can effectively address the unique challenges and requirements of different industries, maximizing their utility and impact.
Examples include:
- Finance: While prior LLMs excelled in automating customer service and analyzing market sentiment, reasoning models can identify unusual patterns for real-time fraud detection and develop sophisticated investment strategies by analyzing market trends and historical data. As reasoning models improve, adoption will spread to broader agentic uses where current state-of-the-art LLMs are not trusted for automating customer-facing functions, such as loan origination, know your customer and compliance monitoring.
- Healthcare: Beyond automating patient communication and summarizing medical literature, reasoning models can analyze patient data to suggest diagnoses and personalized treatment plans, considering complex medical histories. They can also accelerate drug discovery by predicting molecular interactions and potential drug efficacy.
- Legal: In addition to summarizing legal documents and extracting contract terms, reasoning models can review legal documents, identify relevant case law and provide detailed legal reasoning for case preparation. They also enhance compliance monitoring by continuously analyzing regulatory adherence data.
- Disinformation security: In addition to detecting and verifying disinformation, reasoning models can be used to analyze context, generate counternarratives and educate users on recognizing false information. They can also automate content moderation and collaborate with experts to enhance strategies for responding to disinformation.
Recommended Actions
- Expand market reach by integrating or developing solutions with open-source models, which offer cost-effectiveness and accessibility, aligning with the growing interest in smaller, self-hosted models.
- Reduce development costs by adopting lean development practices, such as model distillation and mixture of experts (MoE) architecture, to create efficient AI models that operate on resource-constrained hardware.
- Boost the efficiency of generative AI investments by investing in robust software platforms for managing AI model life cycles, ensuring effective development, deployment and maintenance.
- Build user trust by incorporating transparency and explainability in AI models, similar to DeepSeek R1’s chain-of-thought reasoning, to improve user experience and facilitate error resolution.
Gartner Recommended Reading
Small Language Models
Analysis By: Annette Zimmermann, Ray Valdes
Definition:
Small language models (SLMs), also called “light language models” or “small models,” support use cases where traditional large language models (LLMs) are not feasible or ideal. SLMs represent a trade-off between the generalized power of LLMs and the narrower requirements of resource-constrained environments, such as on-premises deployments, smartphones or edge network nodes. SLMs are much smaller than their LLM counterparts. Examples include Meta’s Llama 3.2 1B, Mistral AI’s Mistral 7B, Aleph Alpha’s Pharia-1-LLM-7B-control and DeepSeek-VL2. The number of parameters that categorize a language model as small has changed over time in relation to mainstream LLMs. In addition, the dichotomy of small versus large has become more complex, with various sizes for different use cases. These include 3 billion parameters or fewer for edge devices, 7 billion parameters or fewer for smartphones, 70 billion parameters for laptops or equivalents, and 130 billion parameters or more for on-premises servers. This spectrum of sizes and use cases is evolving rapidly. Most of the SLMs mentioned are open source.
Sample Vendors
Apple; Databricks; DeepSeek; Google; IBM; Meta; Microsoft; Mistral AI; NVIDIA; OpenAI
Range: 1 to 3 Years
SLMs are one to three years from reaching early majority customer adoption due to rapid innovation and strong market demand.
Investment is growing from startups and hyperscalers in the development of SLMs. This vendor activity and the emergence of SLMs so soon after the popularization of LLMs signal strong market demand for language models that can:
- Run in an enterprise data center or in disconnected mode (i.e., without a cloud connection)
- Reduce infrastructure and operational costs
- Run on small devices like mobile phones or laptops
- Leverage company data while keeping it private
- Be fine-tuned to the needs of a particular vertical industry (such as healthcare or legal) for increased accuracy
- Run on Internet of Things (IoT) devices at the edge of a network
- Reduce energy footprints and carbon consumption
- Be customized in various ways, including being embedded in applications or in orchestrated agent frameworks, such as LangChain or LlamaIndex
SLMs provide a good starting point for meeting these requirements. The task requires customization and solution building, which would be done by vertical-focused vendors, external services providers or in-house technical teams (for the small number of enterprises that have these skill sets). An emerging subcategory of SLMs is language models that run on smartphones. This will become increasingly important in the near future.
Small models benefit from ongoing efficiency innovations in training, inference, tooling and frameworks. A steady stream of releases by both existing players and new entrants will continue. Both emerging vendors and startups continue to innovate in model architecture and training techniques to further optimize performance and efficiency. Small language models with a mixture of experts (MoE) architecture are already achieving faster performance and also provide cost advantages due to lower computational costs. The result is a virtuous cycle where rapid adoption of SLMs will occur over one to three years for use cases where they are well-suited.
SLMs cannot match the performance and scope of massive LLMs in terms of generalization, language processing, completeness and reasoning. However, they do offer capabilities that larger LLMs cannot easily replicate:
- Customization: A smaller size makes it easier to customize and support diverse use cases, although this also requires open-source or open-weight licensing.
- Edge computing: A smaller size can also support applications on edge devices (including smartphones).
Mass: High
Small language models will have a high impact on a range of use cases, both on-premises and on-device, and they will extend LLM value to a diverse set of edge devices.
Systems based on small models can process natural language inputs in real time and generate responses on devices such as smart speakers, smartphones and building thermostats, as well as through user interfaces in cars, factory machinery, field robotics and construction equipment. Thus, potential adoption is very broad.
SLMs can reduce the cost basis to enable a range of use cases, stimulate market growth, deliver productivity improvements in various industries, and move the cost of computation from the cloud to the edge (that is, from the provider to the customer). In addition, systems based on small language models have the potential to offer a competitive edge to early adopters, provide an enhanced user experience, ensure data privacy and enable new types of applications.
Code generation for software development is another use case where smaller models can be more effective when focused on a specific language or code repository (such as an enterprise’s legacy COBOL code).
SLMs will drive incremental capabilities in the near term and revolutionary changes in the long term. They will enable more pervasive generative AI (GenAI) solutions by running on various devices and deployment points (e.g., smartphones, scooters and IoT devices). Hybrid architectures will become more common, combining multiple LLMs at different deployment points. An example scenario is a smartphone SLM (handling UI, image processing and language translation) connected to an on-premises small or midsize model (handling enterprise private data). This example configuration further connects to larger LLMs or even massive models in a hyperscaler’s cloud. Small models are essential to this future scenario, which will likely materialize by 2027.
Recommended Actions
- Ensure an adequate degree of loose coupling and modularity in LLM-based solution architecture to allow for the replacement of one LLM with another, due to the rapidly evolving nature of the field.
- Differentiate your GenAI offerings by investing in SLMs to leverage strengths regarding privacy, latency, cost and carbon footprint.
- Leverage emerging edge opportunities and enhance deployment flexibility by designing hybrid architectures that combine small, on-device models with small to midsize on-premises models and larger cloud-based models.
Gartner Recommended Reading
Synthetic Data
Analysis By: Vibha Chitkara
Definition:
Synthetic data (SD) is a class of data that is artificially generated rather than obtained from direct observations of the real world. Synthetic data can be generated using different methods, such as statistically rigorous sampling from real data or generative approaches such as generative adversarial networks (GANs) and foundation models. It can also be created by simulating scenarios in which models and processes interact to create completely new datasets of events. The most emerging aspect is the use of generative AI for creating synthetic tabular, relational and text-based data, and 3D synthetic assets. Real data is highly valuable but often has many flaws, such as being inaccurate, dirty, incomplete or biased. Even if the real data were pristine, it would still, by its nature, be limited to actual, historical events. Synthetic data allows companies to build the data they need or want rather than being restricted to what they have. Using synthetic data, they can create fit-for-purpose data that may reflect the version of the world they want. Or, with simulation data, companies can explore alternative scenarios of what the world could be.
Sample Vendors
Accelario; Aindo; Anonos (Statice); Anyverse; MOSTLY AI; NVIDIA; Parallel Domain; SKY ENGINE AI; Skymantics; Synthesis AI
Range: 1 to 3 Years
The range for synthetic data is one to three years. The core value propositions driving its adoption are privacy preservation, improved model accuracy, scenario exploration, faster time to value for model management and drastically reduced costs for acquiring real data. Synthetic data exponentially expands the possibilities for and the value of artificial intelligence and other data-centric solutions.
The future of data is not real; it is synthetic. Gartner expects that by 2030, SD will surpass real data as a foundation for business decision making. Real data, while valuable, often suffers from inaccuracies, incompleteness and bias, and it is inherently limited to historical events. Synthetic data addresses these limitations by allowing companies to generate fit-for-purpose data that reflects desired scenarios or explores alternative futures. The demand for robust data in the GenAI space is also driving interest in synthetic data. However, tabular and textual synthetic data are still maturing. There is also ongoing experimentation and a shift from using non-GenAI techniques and GANs to incorporating large language models (LLMs) with transformer-based approaches to add contextual layers to data records, enhancing their utility. In addition, LLMs also democratize the synthetic data generation process using language prompts.
SD capabilities are particularly advanced in simulated data, including image and video data, where generative AI techniques like GANs and diffusion models, as well as simulation environments, are nearing mainstream adoption. Those tech advancements will unlock new emerging use cases, such as generating virtual worlds, training AI agents to interact with users in virtual environments, simulating climate/event scenarios, and mitigation planning or simulating cyberattacks for security testing.
Investments into SD development are growing rapidly, with venture capital investment increasing nearly 400% in the last three years. Additionally, we anticipate accelerated interest in synthetic data due to growth in GenAI adoption, which will require robust data for training, model fine-tuning and scenario analysis. However, misunderstandings about applications and reliability are creating the following impediments to growth:
- Variable quality of synthetic data, depending on the AI model that generated it.
- Understanding the transparency of SD data generation techniques and the efficacy of complete privacy guarantees.
- Synthetic data may be complicated to develop, depending on the use case.
- Operationalizing synthetic data requires additional verification steps, such as comparing model results with human-annotated, real-world data, to ensure the fidelity of results.
- User skepticism, as users may perceive it to be “inferior” or “fake” data.
Despite these challenges, the advantages of synthetic data are very compelling. They include:
- Mitigating the limitations of real-world data,
- Enabling the exploration of alternative scenarios
- Exponentially expanding the possibilities for AI and other data-driven solutions
As technology advances and these challenges are addressed, the adoption of synthetic data will accelerate, transforming how organizations leverage data.
Mass: Very High
The mass of synthetic data is very high because it opens an entirely new universe of data possibilities beyond supplementing real data, thus impacting all industries.
Synthetic data has the potential to revolutionize multiple industries and use cases in the next three years. It democratizes access to high-quality data, enabling smaller companies to compete with larger enterprises by creating more intelligent processes, products and services faster. Some of the near-term opportunities will be centered around supplementing real data with SD, while more emerging future opportunities and use cases will open a new universe of data possibilities with simulation scenarios.
Near-term use cases: Privacy-sensitive sectors such as financial services, insurance and healthcare use synthetic data to accelerate model development and deployment without the regulatory hurdles associated with real data. Additionally, industries like automotive, robotics, media, retail, defense and logistics are increasingly adopting synthetic data to enhance the accuracy of computer vision solutions and other AI applications.
Emerging use cases: The integration of synthetic data and AI with simulation techniques further accelerates its adoption across enterprises. By generating data that reflects various hypothetical scenarios, synthetic data enables companies to explore new possibilities and optimize their workflows and operations. For example, advancing drug discovery and the development of personalized medicine via simulated clinical trials, training robots for various tasks (robot-human coworking), and training cyber security models to mitigate attacks. As synthetic data continues to evolve, it will touch virtually every industry and improve data and AI solutions, driving innovation and efficiency on a global scale.
Synthetic data will have transformative capabilities by freeing organizations from relying on real-world data and enabling endless opportunities for simulations and data-generating techniques. Synthetic data opens an entirely new universe of data possibilities, allowing companies to build the data they need or want rather than being restricted to what they have. Using synthetic data, they can create fit-for-purpose data that may reflect the version of the world they want, or, with simulation data, they can explore alternative scenarios of what the world could be.
Moreover, synthetic data can play an important role with enhanced reasoning. There is opportunity to create a wide range of scenarios with synthetic data, including edge cases that are not available with real-world data. With these extended scenarios the system can learn broader concepts and therefore exhibit strong reasoning capabilities by handling rare and extreme cases.
However, building synthetic data is a complex process that requires technical expertise and careful ethical considerations. Ensuring that synthetic data accurately reflects the statistical properties and patterns of real data is crucial, as any errors can lead to poor model performance or misleading and biased insights. Hence, setting clear expectations for synthetic data offerings is essential for building trust, driving market growth, and helping to identify and unlock new opportunities beyond its traditional role as a data complement.
Recommended Actions
- Unlock the transformative power of synthetic data for enterprises by jointly identifying new use cases beyond its traditional role as a data complement.
- Create a strategic roadmap that positions synthetic data supplementary use cases as the immediate focus, while laying the groundwork for future exploration of scenario planning and simulation use cases.
- Target regulated industries and differentiate by providing tools to measure the effectiveness of synthetic datasets, and provide privacy filters to comply with regulations and internal compliance mandates.
- Incorporate synthetic data within your data management principles by setting policies on storage, editing and retrieval once synthetic datasets become important to business outcomes like ML training results and software testing.
Gartner Recommended Reading
3 to 6 Years
Agentic AI
Analysis By: Anushree Verma
Definition:
Agentic AI refers to goal-driven software entities that autonomously make decisions and take action. These entities use AI techniques combined with components such as memory, planning, sensing, tooling and guardrails to complete tasks and achieve objectives. Unlike robotic process automation, agentic AI doesn’t require explicit inputs and doesn’t produce predetermined outputs. Agentic AI entities can receive goal instructions, iterate and delegate tasks, plus output variables and dynamic information, often augmenting the user’s work. Examples include AI agents, machine customers and multiagent systems (MAGs).
Sample Vendors
AI21 Labs; Anthropic; Cohere; KOGO Tech Labs; LangChain; Leena AI; OpenAI; Replit; Revrag.ai; Salesforce
Range: 3 to 6 Years
The range of three to six years is because the current adoption is expanding beyond research and development projects into other applications like virtual assistants. However, the complexity and the lack of trust are significant barriers to its scalability.
Interest in agentic AI has grown rapidly during 2024; however, hype seems to be the driver to provide autonomy and increasing productivity, while adoption still remains very low (for now). Gartner observes that both AI startups and large enterprises are marketing themselves as developers of agentic AI building platforms, with early examples often resembling a front end of an advanced or generative artificial intelligence (GenAI)-enabled virtual assistant. However, agentic AI represents an advanced design pattern for artificial intelligence, characterized by software agents capable of pursuing complex goals and workflows with varying degrees of human supervision. For some years, intent-based chatbots have been able to understand a user’s intent and retrieve requested order information. However, they have not interacted with a large language model (LLM) to develop and execute a comprehensive plan of action. Therefore, agentic AI differs from conventional agent-based systems that are traditionally guided by rule-based or contextual guardrails, whereas agentic AI combines traditional, predictive AI and generative AI.
Agentic AI introduces new security and privacy challenges, as agents may interact with sensitive data, thereby escalating governance concerns and cyberattack vulnerabilities. Moreover, the technology’s novelty, along with its action-oriented and use-case-specific nature, results in highly diverse frameworks, architectures and design patterns in early implementations, presenting additional challenges. Agentic AI can enable new collaboration models, such as “user-in-the-loop” (UITL) solutions, but could also increase workflows. Traffic flows both ways in UITL AI systems — user to AI and AI to user. This complexity in agentic AI architecture poses significant challenges for system integration, interoperability and coordination, thereby hindering rapid scaling.
Agentic AI encompasses a spectrum ranging from highly constrained agents, which operate on explicit inputs and known, planned outputs, to fully autonomous systems that engage and execute based on contextual understanding. These systems exhibit varying levels of autonomy in their decision-making capabilities (where decisions may be mediated by humans, governed by business logic, or driven by sophisticated models and algorithms). Given the diverse set of applications, there is difficulty in the initial standardization of the frameworks and architectures. There is increased investment in the industry for agentic AI. Current LLM-based systems (like virtual assistants) are more adaptable and can tackle more complex tasks than previous systems like deterministic chatbots. However, they remain unreliable and require human supervision; as such, they represent early examples of agentic AI rather than the fully developed agents promised by future AI models. Initial development of this technology by service providers is predicated on these current LLM-based systems.
Despite these challenges, the sophistication of agentic AI, including LLM-based assistants, will increase over time. Similarly, new approaches to building agents, such as the use of large action models, will complement or replace LLMs and other techniques as the core of future agentic AI architectures.
Mass: Very High
Mass is very high because agentic AI will introduce a goal-driven, digital workforce capable of autonomously planning and executing actions. This technology promises to revolutionize all industries and environments via automation and human augmentation.
Agentic AI will be an extension of the workforce, for example:
- Function-specific environments for within CRM deployments
- ERP for human capital management, finance and accounting
- Materials requirement planning
Until now, agentic AI, widely applicable to CRM systems, has been mostly adopted. It will be used in retail to analyze customer preferences, recommend personalized products and adjust inventory levels based on real-time sales data. This will thereby improve both customer experience and inventory management. Various applications such as personalized risk assessment or insurance policy customization exist in the banking, financial services and insurance segment to aid dynamic financial planning.
Applications that create immersive environments in multiple industries will benefit by incorporating agentic AI; for example, smart appliances in smart spaces and virtual assistants in autonomous vehicles. Agentic AI will be part of AI assistants, software, SaaS platforms, Internet of Things (IoT) devices and robotics. Agentic AI also will be used for:
- Selling or purchasing products
- Composing bundles or solutions to meet unique requirements
- Supporting customers, including advanced machine customers
For example, agentic AI can be used to automate selling processes for both outbound and inbound sales by employing scoring and researching algorithms. These can identify high-intent leads while also learning more from an organization’s peer learning platform. Some examples of the most common emerging use cases for agentic AI will be:
- AI agents for medical diagnostics
- AI agents for predictive maintenance
- AI agents for investment advice
Agentic AI is a transformative capability, leveraging a mixture of different generative models and techniques depending on the goal. Semiautonomous or autonomous, depending on the task, agentic AI provides a significant opportunity for productivity gains, predictive analytics and decision making. This will increase over time as the systems learn to achieve their goals more efficiently. As of now, agentic AI deployments are in the very early stages and the technology has limited agency to perform specific tasks under narrowly defined conditions.
These efforts will evolve into future agentic AI systems with full agency that learn from their environment, make decisions and perform tasks independently. They will consist of either a single AI agent or multiagent systems, depending on the task and the ultimate goal to be achieved.
Recommended Actions
- Connect disparate applications and data by incorporating agentic AI solutions while prioritizing improved user experience and overall efficiency.
- Integrate agentic AI capabilities into your products and services, prioritizing the development of robust and scalable solutions. Focus on high-value use cases that can enhance productivity and decision making.
- Establish guardrails for AI governance by ensuring strict security and privacy protocols, such as end-to-end encryption and multifactor authentication, when implementing agentic AI. This is because this technology can start operating autonomously and make decisions on your behalf.
Gartner Recommended Reading
AI Code Assistants
Analysis By: Ray Valdes
Definition:
Gartner defines AI code assistants as tools that assist in generating and analyzing software code and configuration. These tools assist software developers in coding tasks, initially centered around generating code within an integrated development environment (an IDE). However, they are increasingly broadening their scope to go beyond code completion, including tasks such as code review, debugging, refactoring, code search, code quality, security analysis and optimization. These latter capabilities are still emerging in this category.
Sample Vendors
Amazon; Anysphere; Codeium; GitHub; Google; Replit; Sourcegraph; Tabnine; Tencent; Zed
Range: 3 to 6 Years
The range for AI code assistants is three to six years. This is the result of two years of steady growth in early entrants like Tabnine and GitHub Copilot, followed by two dozen other entrants. The field as a whole is evolving rapidly, with much overlap and repositioning.
The growth of adoption varies from region to region and with company size and risk profile. Adoption is greater and more rapid in the U.S. than in other regions, and among development teams at small and midsize companies versus large organizations (with the exception of some tech giants).
There are some vendor surveys that claim high adoption, but these have not distinguished between individual developers experimenting with code assistants at home on personal projects and systematic use on projects at work. Adoption varies by company size, with small and midsize tech companies having higher adoption rates than larger, more risk-averse organizations. Based on inquiries and online communities, it is clear that adoption is well underway but still concentrated among early to midstage adopters.
There are separate but related product categories for software testing, documentation, code modernization and code review that have their own sets of vendors, including legacy vendors that predate generative AI. Beyond developer-focused productions and established software development life cycle (SDLC) vendors, there are general-purpose large language models, such as OpenAI’s GTP-4o, Anthropic’s Claude 3.5, and Google’s Gemini 1.5, that are not specifically designed for coding but are being used by many developers to generate code. Mergers and acquisitions can be expected as the competitive landscape evolves.
The speed of adoption is robust but not exponential. The technology is still new and unfamiliar in comparison to other developer tools. The technology is still immature (although evolving rapidly), and the scope is mostly around the code generation phase of the SDLC (although the scope is being broadened to cover other stages). Gartner expects growth to continue at a robust pace as the technology continues to improve and mature, and as the market becomes more aware and adept at getting value out of AI-powered software development tools.
Some segments are incorporating these tools smoothly into their revised workflows, while others are tentative or still experimenting. There are different styles of using these tools, for example, for code completion in the context of IDE use, or as a batch process using a command line interface. Reactions among developers who begin using these tools span a spectrum from “this is worthwhile” to “not for me, thanks anyway.” Quality of results varies depending on project requirements, programming language (and associated frameworks like React or Django), developer styles of working, team collaboration, organizational culture and vendor/ecosystem support.
The tools are rapidly evolving in both power and scope, and this will fuel adoption within the slower-moving cohorts over time. There are sufficient shortcomings in the current stage of technology that will provide friction against rapid “hockey stick” adoption over the next two to three years.
Mass: Medium
The mass is medium because while adoption of code assistants is taking place across a range of industries and market segments (such as tech vendors, systems integrators, software development consultancies and internal development teams within enterprises), the impact will be limited in the near term.
Code assistants are useful wherever software is written, maintained, refactored and modernized. This can be in vendor development teams building new products or maintaining existing products. They can also be used in systems integrators and solution builders. Lastly, they can be used within enterprises in many different sectors, including financial services, pharmaceuticals, oil and gas, manufacturing, and many others. Per the saying from investor Marc Andreessen, “Software is eating the world” (meaning software has become an essential part of many industry sectors, including ones that in the past had little to do with it, such as manufacturing). Code assistants are and will continue to be adopted by these sectors.
The impact of code assistants will grow over time, but initially it will be modest, on the order of a 10% to 15% productivity lift for the average software development team in the average organization. The design goals and customer expectations have centered around the code generation phase of the SDLC. This narrow scope puts a ceiling on the potential impact and benefits of code assistants, because writing code is only a small part of what software developers do (depending on estimates, writing code takes up anywhere from 15% to 40% of a developer’s time).
There are many other aspects of the SDLC that are not addressed by code assistant tools. However, the scope of these tools is now broadening to include debugging, documentation, refactoring, testing and code modernization. As organizations and teams become more adept with these tools, and as the tools improve, the impact of using these tools will grow. With diligent and systematic effort, an organization could eventually achieve a 25% to 30% productivity increase over the next two to three years, a significant improvement over the 10% benefit in the current wave of usage centered around code generation.
Recommended Actions
- Plan for low loyalty in your customer base by ensuring positive marketing messaging on upcoming features to maintain relevance and responding directly to the rapidly evolving landscape of competitive threats.
- Anticipate a complex adoption environment of users that will invest in multiple tools to support the SLDC by positioning your tools as beneficial alongside relevant tools that support documentation, testing, code modernization, code review, security audit and other functions.
- Leverage IP from closed-source and open-source models by integrating it into your software while also anticipating competitive threats. Engineers are experimenting with a broad range of general tools, which will continue to impact the competitive landscape.
Gartner Recommended Reading
AI Marketplaces
Analysis By: Annette Zimmermann, Aakanksha Bansal, Eric Goodness
Definition:
AI marketplaces are virtual spaces where product leaders and AI adopters can share, sell or buy a variety of AI assets. These include offerings such as domain-specific generative models, open-source models, governance tools, curated datasets, notebooks and generative AI (GenAI)-enabled applications.
Sample Vendors
Databricks; Dawex; Defined.ai; Deloitte; DXC Technology; Google; Nomad Data; Second; Snowflake; Tata Consultancy Services
Range: 3 to Six Years
The range for AI marketplaces is three to six years as the rapid growth and adoption has only started over the past 12 months and is expected to gain significant momentum in 2024 and 2025.
Based on our case-based research, we estimate the distance to be 18% to 20% of the way to early majority adoption. The number of new entrants in this space has multiplied recently while first movers are frequently adding new capabilities and offerings to address user demand.
AI marketplaces have evolved quickly in the past year because of fast-growing interest in GenAI business applications following the launch of, for example, Anthropic’s Claude, Google Gemini, Meta’s Llama and OpenAI’s GPT-4.
Using AI marketplaces as a source for AI and GenAI solutions offers several advantages driving its adoption:
- Cost reduction through shared acquisition, development and infrastructure
- Accelerated time to value and market via collaborative code/notebook sharing
- Enhanced control with domain-specific models deployed on-premises or in private clouds
- Increased innovation through collaboration across various business units and partners
- Reduced need for extensive data science teams, as AI marketplaces provide curated datasets and additional services, benefiting small and midsize organizations
The rapid evolution of AI marketplaces is driven by growing interest in GenAI business applications, spurred by new foundation models and small language models. The variety of AI assets is increasing as vendors offer data warehousing functionalities, processing, a multitude of different datasets and secure data sharing services. We predict that by 2028, 40% of AI asset purchases such as models and data by enterprises will take place via AI marketplaces. The number and variety of AI marketplaces are growing, with two main themes emerging:
- AI marketplace as a service: Providers offer software, tools, services and infrastructure for running internal or third-party AI marketplaces, typically involving a licensing scheme.
- Data for AI: Innovation is driven by high-quality datasets for GenAI models and solutions.
However, the proliferation of AI marketplaces faces challenges:
- Unclear charging schemas (inconsistent, evolving pricing models and pricing) by independent software vendors (ISVs).
- Issues with software bugs, breaking changes and inadequate documentation.
- Users must assess the ease of use and efficacy of tools and services offered by model hub providers.
- Smaller companies benefit from model hubs for faster innovation due to limited resources compared to larger companies.
- Market education is needed. The demand for high-quality data and data science services is high, spurred by the GenAI hype. Yet many organizations are not even aware of what they need to successfully implement AI-based products and services.
Mass: Very High
The mass of AI marketplaces is very high because a good number of different industries including healthcare, manufacturing, banking, insurance, telecom, and media and retail are already benefiting from AI marketplaces, especially on the data for AI side.
The use of AI marketplaces will significantly impact various market segments and industry verticals operationalizing generative models because:
- Reduced complexity: AI marketplaces simplify the integration of machine learning and GenAI capabilities, providing faster and easier access to state-of-the-art models, saving organizations from the resource-intensive process of developing and tuning individual models.
- Shorter time to value: AI marketplaces promote collaboration and knowledge sharing within the AI community, allowing enterprises to improve existing models, share expertise and develop innovative solutions.
- Ease of model evaluation: Growing demand for user-friendly model evaluation and benchmarking capabilities helps enterprises assess and select the best models for their use cases.
- Faster iterations: The need for rapid experimentation and innovation with generative AI models, such as proofs of concept and domain-specific models, enables companies to explore and develop unique AI-based solutions.
AI marketplaces mark a significant change in how organizations consume AI assets. AI marketplaces are being used to support various domain-specific use cases across vertical markets. Access to data, models, prompt templates and other resources reduce complexity and accelerate time to value.
Healthcare and life science are among the domains with strong interest in AI marketplaces due to their specific requirements. For example, healthcare and life sciences organizations possess large amounts of valuable data that usually falls under strict privacy laws. Hence, it is data that is not easily accessible and shared on the free market. AI marketplaces can ensure this data is shared privately (and anonymized) in a highly secure environment.
Some observed uses of AI marketplaces to support market specific capabilities include:
Manufacturing
- Predictive maintenance: AI predicts equipment failures, reducing downtime and costs.
- Quality control: Computer vision enhances real-time defect identification.
Financial Services
- Fraud detection: AI detects fraudulent activities by analyzing transaction patterns.
- Customer service: Chatbots provide real-time support and personalized advice.
Insurance
- Claims processing: AI automates and expedites claims processing.
- Personalized policies: AI creates tailored insurance products based on customer data.
Retail
- Personalized shopping: AI-driven recommendations enhance customer engagement.
- Inventory management: AI optimizes stock levels and predicts demand.
Communications, media, services
- Content personalization: AI tailors content to individual preferences.
- Customer service automation: AI chatbots provide efficient support.
Transportation and logistics
- Route optimization: AI determines efficient delivery routes.
- Fleet management: AI monitors vehicle health and driver behavior.
Recommended Actions
To effectively productize AI marketplaces, perform broad due diligence:
- Compare market offerings: Evaluate AI marketplaces of both closed- and open-source providers, and the growing offerings of LLMOps providers. Close scrutiny of the created model hub communities and how they engage relating to technical issues, support and usability.
- Engage larger providers: Improve access to state-of-the-art models by partnering with larger providers, like cloud hyperscalers, to create diverse hubs offering both closed- and open-source models.
- Focus on the AI marketplace as a resource for enabling skills: Increase user knowledge and engineering skills for using, refining and fine-tuning off-the-shelf models from AI marketplaces.
- Establish trust through transparency where possible: Quality curated data, model and data provenance when possible are key to sustained use of AI marketplaces.
- Simplify pricing schemes and increase transparency by offering for example “first trial before buy” for data to increase buyer confidence.
Gartner Recommended Reading
Data Center Microgrid
Analysis By: Bob Johnson
Definition:
Data center microgrids are one or more data centers with a local source of electricity supply that can function independently of or in conjunction with a larger regional power grid. These will proliferate as data center operators respond to looming shortages of utility-based electrical power in the quantities needed to continue planned expansions. Fueled by generative AI (GenAI)-driven expansion of both the number and size of data centers, power demands are rapidly outstripping the ability of regional power utilities to bring new generation capacity on line fast enough. One solution is for data center operators to build dedicated electrical power generation and/or distribution facilities (microgrids) that can operate either completely independently or in conjunction with existing power utility suppliers.
Sample Vendors
Bloom Energy; Eaton; General Electric; Helion; Hitachi Energy; NuScale Power; PowerSecure; Siemens
Range: 3 to 6 Years
The range for data center microgrids is three to six years because major data center operators are just beginning to assess the impact of projected shortages in the utility power markets and are evaluating alternatives approaches like microgrids.
While there have been some announcements of innovative microgrid solutions for data center power needs, these are a few years out. For example:
- Amazon Web Services announced an agreement to buy power using an existing data center with direct connection to the Susquehanna Nuclear Power Plant in Pennsylvania (U.S.).
- Microsoft announced an agreement with Constellation Energy to restart the Three Mile Island nuclear power plant to provide dedicated power to its data centers, which should take about five years to complete.
With the increasing size of data centers, implementing dedicated power generation requires a complex one- to two-year permitting process and environmental reviews, which means microgrid construction can’t start immediately.
Another issue is that data centers tend to cluster in tight regional areas, which puts a strain on regional power companies and may stall local developments at existing sites. One alternative is to regionally diversify, but doing so requires additional planning and permitting processes that push out the timelines for data center construction and microgrid adoption.
Data centers had traditionally relied on power utilities to provide the needed power for data center operations, but this is changing. Gartner estimates that total power demands for information and communications technology (ICT) are increasing at a compound annual growth rate of 24% per year, while total power generation capacity is projected to increase at only 3% per year. Data center demands for power are the largest contributor to this trend.
A critical impact of this trend is that regional power utilities serving areas with high concentrations of data centers will begin to limit available power within two years. As a result of this trend, Gartner estimates that by 2028 more than half of all new data center projects will not be able to meet all of their power needs with dedicated grid power. They will use some form of microgrid to ensure reliable operation. The majority of data center microgrids by that time will utilize a combination of on-site power generation and connection to a public utility grid to ensure continuing operations.
Mass: Medium
The mass for data center microgrids is medium because they will primarily be used on new hyperscale data centers in areas where there is insufficient regional power available.
Data center microgrids will be required for the vast majority of new data centers by 2028 as the ability of power utilities to increase their generating capacity becomes inadequate to meet the demands of new data centers. Data center microgrids require support and will affect the power generation, transmission and distribution industries, along with the renewable energy and data center industries. In addition, new regulations are emerging, such as in the EU, that will require renewable power for new data centers.
While there may be adequate solar and wind power for data center operations most of the time, additional power resources will be needed to ensure data center operations on a 24 hours a day, seven days a week level. Microgrids, working with utility-level renewable power, can provide the needed intermittent power generation.
In the near term, data center microgrids will rely on currently available power generation capabilities including fossil fuel, nuclear from existing plants, hydrogen fuel cells and utility-scale batteries for storage combined with dedicated renewable power sources. The objective will be to provide dependable power to ensure continuous and reliable operation for both new and existing data centers. Longer term, new green alternatives will emerge, including small modular nuclear reactors (SMRs), hydrogen fusion and clean hydrogen for fuel cells. These new alternatives will begin to become available by the end of the decade.
Recommended Actions
- Hardware suppliers of equipment for data centers must evaluate their products’ impact on overall data center power and present a roadmap of how they can help address the power problem.
- Data center equipment suppliers should initiate efforts to understand how their products can improve the utilization of microgrid technology to ensure adequate power is available for data center expansion products.
- Microgrid suppliers should work with data center operators to develop new regional data center clusters powered by microgrids.
Gartner Recommended Reading
GraphRAG
Analysis By: Jim Hare, Radu Miclaus, Afraz Jaffri
Definition:
GraphRAG is a technique to improve the accuracy, reliability and explainability of retrieval-augmented generation (RAG) systems. It uses graph structures and graph databases to manage data, whereas traditional RAG relies on embeddings and vector databases for information retrieval. Unlike traditional RAG methods, which primarily rely on linear retrieval and generation processes, GraphRAG introduces the ability to model complex relationships and dependencies between retrieved pieces of information. GraphRAG addresses multiple issues associated with current RAG solutions, such as lack of contextual understanding, limited knowledge representation, scalability challenges and domain specificity. The approach uses graph info to improve the recall and precision of retrieval, eliminating irrelevant information.
Sample Vendors
Amazon Web Services; Fujitsu; Google; Lettria; Microsoft; NebulaGraph; Neo4j; Ontotext; Palantir; Writer
Range: 3 to 6 Years
The range for GraphRAG is three to six years to early majority adoption as enterprises look for ways to improve the accuracy of generative AI (GenAI) solutions that currently rely on vector-only RAG approaches.
GraphRAG architectures created by cloud and application providers are emerging as the next evolution/replacement of vector-only RAG approaches due to the accuracy and performance improvements they deliver. Accuracy is a challenge with GenAI solutions because these models generate responses based on patterns in data rather than verified facts, which can lead to hallucinations or misinformation. Additionally, GenAI lacks inherent mechanisms for validating or cross-referencing its outputs, making it difficult to ensure the generated content is precise, reliable and contextually relevant.
GraphRAG helps ensure the generated content is grounded in verified data and factual relationships, reducing the risk of hallucinations. GraphRAG offerings are being introduced by traditional knowledge graph providers that have created or extended their tools to make it easier to build knowledge graphs (KGs) and integrate them with large language models (LLMs).
GraphRAG alleviates some of the accuracy challenges with GenAI solutions because these models generate responses based on patterns in data rather than verified facts, which can lead to hallucinations or misinformation. Additionally, GenAI lacks inherent mechanisms for validating or cross-referencing its outputs, making it difficult to ensure the generated content is precise, reliable and contextually relevant. GraphRAG helps ensure the generated content is grounded in verified data and factual relationships, reducing the risk of hallucinations.
Drivers for GraphRAG include the need for more accurate results and ability for organizations to access a broader corpus of enterprise data to improve context. Despite these drivers, several inhibitors are limiting the adoption of GraphRAG, such as the complexity of setting up KGs and the high level of expertise required in data and knowledge modeling.
Mass: High
The mass for GraphRAG is high because it can enable RAG-based GenAI applications to retrieve and generate responses that are more contextually relevant and accurate.
GraphRAG will impact a significant number of use cases across industry verticals where delivery of accurate information is critical:
- Enhanced search: Integrating RAG with enterprise KGs can provide employees with relevant, contextually accurate and connected information across internal documents, databases and other resources.
- Automated response generation: RAG systems can use KGs to retrieve relevant information from a company’s knowledge base and generate accurate, context-aware responses to customer inquiries.
- Self-service portals: Enhancing self-service support portals with RAG can provide users with precise answers drawn from structured KGs, improving user experience and reducing support costs.
- Knowledge discovery: Facilitating knowledge discovery within organizations by using RAG to generate insights and summaries based on the structured data in KGs.
GraphRAG is a revolutionary approach that significantly enhances RAG by incorporating graph-based structures to provide more accurate, context-aware decision making. By leveraging graph structures, GraphRAG not only improves the quality of the generated content but also enables more sophisticated reasoning and knowledge integration, setting a new standard in the field of AI-driven content generation.
GraphRAG enhances tasks such as personalized learning, legal document summarization and financial analysis by leveraging interconnected knowledge structures, offering deeper insights and more precise, context-aware responses. This approach is especially impactful in fields and use cases where relationships and connected data are key.
However, implementing GraphRAG requires expertise in graph databases, natural language programming, informal retrieval, data engineering and domain-specific knowledge, which many tech providers lack. It requires efficiently integrating structured and unstructured data, ensuring accurate and relevant retrieval from large KGs, and fine-tuning GenAI models to produce contextually aware outputs, all while managing the performance and costs of the system.
Recommended Actions
- Explore using GraphRAG to address the limitations of current vector-only RAG approaches to provide products with more intelligent and comprehensive search results.
- To design a GraphRAG-based solution, integrate a graph database that organizes domain-specific knowledge, implement retrieval mechanisms to query relevant data efficiently and ensure the generative model can leverage these structured insights to enhance the accuracy and relevance of its responses.
- Provide intuitive and user-friendly interfaces that allow users to interact with knowledge graphs and LLMs. This may involve natural-language interfaces, visual exploration tools or domain-specific applications tailored to specific use cases.
Gartner Recommended Reading
Intelligent Simulation
Analysis By: Alfonso Velosa
Definition:
Intelligent simulation includes simulation applications that leverage AI, GenAI, the Internet of Things (IoT), real-time data and visualization technologies to provide personalized and adaptive simulation capabilities. Unlike traditional simulations that rely on predefined rules and data, intelligent simulations can adapt and learn from their environment, making them more capable of simulating real-world scenarios. Key characteristics for intelligent simulations include: (1) AI-powered decision making, (2) dynamic adaptation to changing contexts or user needs, (3) complex systems modeling across physical/digital process systems and social networks, and (4) scenario planning and assessment of potential outcomes. These scenarios and models are used by leaders to enhance business decisions from supply chain to patient care to equipment operations.
Sample Vendors
Aerogility; Altair; Ansys; Braincube; Cosmo Tech; Native AI; Palantir; Tada Now; visCo
Range
Intelligent simulation is three to six years away from early majority adoption because, while the technologies needed to implement intelligent simulation in applications are on their way toward mainstream adoption, the approach itself faces business process transformation and cultural resistance.
While many enterprises could use intelligent simulation to improve their business decisions and processes, it requires business leaders to invest political capital in driving business change using these new capabilities. Cultural change, from the technician or finance person being asked to change how they manage processes to site leaders being asked to change how they prioritize initiatives, represents one of the biggest hurdles to adoption. It will take at least five years before enough leaders and organizations see examples of improvement and invest appropriately in both technology and culture change efforts.
As an additional barrier, intelligent simulation product leaders often lack a clear GTM strategy. Product leaders often focus too much on the technology stacks for intelligent simulation products, even as the technology stack is immature, lacking off-the-shelf technology products or modules. They fail to invest enough effort in building pricing and value propositions. To further complicate matters, intelligent simulations need to be optimized to specific vertical markets, as a patient care intelligent simulation solution will not provide the same value to an auto manufacturing enterprise as it does to a healthcare organization.
Gartner sees enterprises across all industries and tech providers actively experimenting with intelligent simulation. Product leaders are exploring the improved value they can deliver to enterprises from healthcare to finance to oil and gas. They are also working to capitalize on the enhanced opportunities that GenAI provides — both from a capabilities perspective, and to engage and sell to more senior stakeholders at target end-user enterprises.
To enhance their potential to sell, product leaders are working on solutions for business objectives ranging from sustainability to customer marketing to new monetization models. To support these business objectives, product leaders working on intelligent simulation solutions are leveraging technology stack building block elements that include data fabrics, digital twins, vector graphs, graphRAG and GenAI. The inhibitors for simulation technology advancements center on the lack of integration standards for the different enterprise systems that have the data and context needed to drive intelligent simulation in business scenarios and decisions.
Mass
Mass for intelligent simulation is very high since all industries and business functions may benefit from the approach and it has the potential to change scenario planning and decision processes in multiple industries.
Most enterprises are striving to optimize their decisions amid increasing turbulence in market demand and product requirements. This complexity has intensified since COVID, due to losses in personnel and institutional knowledge, and more frequent changes in customer signals for orders and products. Emerging uses for intelligent simulation include manufacturing plant simulations, asset health predictions, bill of materials simulations on potential bottlenecks, traffic modeling and sustainability analysis.
Leading-edge product leaders and their service partners realize intelligent simulation solutions present opportunities to further embed themselves in their customers’ business processes to create “sticky” revenue. If they can help the supply chain leader run more accurate simulations right before the weekly sales and operations planning meeting, they can help the enterprise better allocate production, meet demand and lower inventory costs. If they can help the head of product or the CMO conduct “interviews” of simulations based on real customers, they can improve the revenue from sales or marketing campaigns.
Intelligent simulations will replace existing human or analog-based processes or existing simulation capabilities because they focus on specific business problems or challenges. Leading intelligent simulation product leaders demonstrate shorter time to value by incorporating business process expertise and simplifying deployments with modern low-code and integration capabilities. These capabilities improve enterprise performance by helping decision makers identify optimal business decisions. They can optimize supply chain decisions, get better views of patient outcomes and increase customer engagement. And they can identify and understand the inputs to their decisions to better understand the risks and rewards.
This means better operational decisions and more productive enterprise teams. For the product leader, this increases the value of the intelligent simulation product and thus of the tech provider, thus driving customer trust and, even better, long-term revenue opportunities.
Recommended Actions
- Advance competitive differentiation by integrating intelligence simulation capabilities and intellectual property modules into all-enterprise software by 2027, with a focus on specific solutions such as improving the operations of oil platforms or sales campaigns or customer onboarding.
- Increase your intelligent simulation product’s near-term revenue potential by focusing on supply chain and on asset-intensive industries such as oil and gas, manufacturing or aviation, where your sales team can demonstrate deep domain expertise and quantitative and qualitative value.
- Accelerate time to revenue by building a clear onboarding and ramp-up strategy for clients, with well- defined simulation-based business projects such as demand scenarios or cost optimization that can scale across the client and supplement their operations with clear value propositions.
Gartner Recommended Reading
Large Action Models
Analysis By: Tom Coshow
Definition:
Large action models (LAMs) are foundation models trained and optimized to identify and generate an action or set of actions that can be used to impact a target environment to meet a goal. LAMs are designed to handle complex sequences of actions in dynamic environments, making them ideal for applications that require real-time decision making and adaptive behavior. AI agents, for example, equipped with LAMs will be able to perform more sophisticated tasks, from autonomous navigation and robotics to intricate workflow automation and strategic planning. This will enable businesses to deploy AI solutions that are not only more efficient but also capable of handling unforeseen challenges and opportunities.
Sample Vendors
Boston Dynamics; Google DeepMind; Microsoft Research; Orby AI; Salesforce
Range: 3 to 6 Years
The range for LAMs is estimated to be three to six years because they require a high level of computation resources and specialized know-how in reinforcement learning. Additionally, very few are currently available for use in production, and builders of agentic AI are currently focused on using LLMs to drive software entities, such as AI agents.
As agentic AI emerges as a viable technique in automation, the adoption of LAMs is on the horizon. These advanced models are set to optimize the implementation of AI agents, offering significant improvements over the currently prevalent large language models (LLMs). While LLMs have been instrumental in driving AI agents by enabling natural language understanding and generation, LAMs promise to take automation to the next level by enhancing planning, problem-solving and task list development. LAMs are at an early stage, with some of the major technology companies working on developing them.
The adoption of LAMs is currently moderate due to several key challenges. First, the development and training of LAMs require significant computational resources and expertise, which can be a barrier for many organizations. Unlike LLMs, which have seen widespread adoption due to their versatility and ease of integration, LAMs demand specialized knowledge in reinforcement learning and real-time decision making. Additionally, the dynamic and unpredictable nature of environments where LAMs operate necessitates training on robust datasets that are not widely available, further complicating their development and deployment.
Mass: High
The mass for this technology is high because we expect large action models to drive impact across many different verticals and business functions.
The impact of LAMs will be high because they will significantly enhance our ability to deploy complex automation solutions across industries. These include:
- Manufacturing and robotics: automating intricate assembly lines and quality control processes, and enabling advanced robotics in warehousing and fulfillment centers
- Healthcare: assisting in robotic surgeries and patient care, and managing complex scheduling and resource allocation in hospitals
- Autonomous vehicles and logistics: enhancing navigation and decision making in self-driving cars, and coordinating complex transportation networks and delivery routes
- Smart cities and energy management: managing urban infrastructure, traffic control and public safety systems, and optimizing energy distribution and waste management
- Customer service: streamlining multistep customer interactions and support workflows
- Finance: automating complex trading strategies and risk management
- Education: tailoring learning content based on individual students’ progress and learning style
- Interaction with digital service: interfaces that adapt in real time to user behavior and preferences, enhancing the navigation of consumer spaces and reducing the need for users to manually work through multiple steps
For early adopters, implementing LAMs could provide a competitive edge, allowing them to offer more advanced and responsive products and services. However, the path to widespread adoption is evolutionary.
The complexity of designing LAMs necessitates a deep understanding of advanced AI techniques, requiring investment in training and skill development. Integrating LAMs into existing IT infrastructure involves upgrading systems and ensuring compatibility with new AI models. Starting with smaller, manageable projects allows organizations to experiment with LAMs, gain practical experience and refine their approach. As the technology matures and becomes more accessible, the pace of adoption is expected to accelerate, driving widespread innovation and efficiency across various industries.
LAMs will be trained to be domain specific as they are creating a specific list of tasks in a given area of expertise. For example, a LAM designed to assist in a claims-processing operation will not work well in the mining industry. However, how LAMs are trained may allow for the same LAM to be retrained for mining using the same architecture and training techniques as the LAM trained for healthcare.
Recommended Actions
- Research and track development: Stay informed on the latest developments in agentic AI, from which new LAMs and related work will emerge. Follow industry research, attend conferences and participate in relevant webinars.
- Invest in skill development: Build a knowledgeable team to successfully develop and deploy LAMs. Allocate resources for training and certification programs focused on advanced AI techniques, such as reinforcement learning and real-time decision making.
- Start with prototyping: Find the limits of LLMs in agentic systems, and gather training data that will support the creation or fine-tuning of LAMs and mitigate risks and build confidence in the technology. Use prototypes to gain practical experience, refine your approach, and demonstrate the potential benefits to stakeholders.
Gartner Recommended Reading
Sustainable AI
Analysis By: Ed Anderson, Aapo Markkanen, Annette Zimmermann
Definition:
Sustainable AI is the use of AI technologies to produce beneficial net outcomes in environmental, social and economic systems while ensuring that detrimental sustainability impacts are mitigated or eliminated. Sustainable AI includes the use of AI for sustainability and the sustainability of AI itself. The approach fully leverages AI technologies to gather, analyze and report sustainability data to assist organizations in optimizing their operations for positive sustainability outcomes. Further, sustainable AI minimizes the use of material resources through the use of renewable energy, energy efficiency, water efficiency and circularity (to reduce or eliminate material waste). Sustainable AI includes fostering the responsible use of AI to ensure that impacts to social systems — including individuals, groups of people, and communities — are positive. As such, the ethical use of AI is included in sustainable AI. Sustainable AI extends to the use of AI technology, including model training, refinement, deployment and consumption. Data management, storage, and networking must also be managed sustainably as foundational elements of AI solutions. Likewise, AI inference through applications and business processes must produce beneficial results across environmental, social and economic systems to be considered sustainable AI.
Sample Vendors
AMD; Clarity AI; Deloitte; Fujitsu; Google; IBM; SAP; Siemens; Windward
Range
The range is three to six years because technology providers are still developing sustainable AI technologies and organizations are still maturing in the ability to use AI to deliver sustainability solutions.
Environmental sustainability remains a top 10 priority of CEOs and senior business executives. Sustainable AI is stifled by the prioritization of other factors that often relegates sustainability investments to a lower-level consideration. Dependence on external parties, including cloud providers and IT service providers, both helps and hinders sustainable AI, depending on the capabilities of the provider.
The leading technology providers have made progress in delivering their technology services, including AI and generative AI (GenAI), in a sustainable manner. For example, cloud providers have stated commitments to reduce greenhouse gas emissions, increase the use of renewable energy and improve energy efficiency. Sustainable AI benefits from these commitments due to the cloud providers’ central role in the technological enablement of AI, although expanding the use of GenAI is certainly increasing the need for more resources, which works against sustainability aspirations.
The use of AI to produce sustainability solutions has so far led to only incremental gains in most deployments — in contrast to the resource-intensive nature of GenAI, in particular. Organizations that use AI are still maturing in their use of the technology (for any purpose). AI adoption also varies based on the maturity of the organization. Focusing on sustainable AI technologies and using AI for sustainability benefits requires organizations to evolve their operational capabilities and to dedicate sufficient investments for sustainability outcomes.
The velocity of sustainable AI varies by region. European countries in particular, with their increasing sustainability reporting requirements and demands for energy efficiency, are incorporating sustainable AI into their broader AI and GenAI strategies. Most other regions are also progressing in their focus on sustainability, but practical factors such as energy scarcity and a range of social and political issues are stifling sustainability initiatives more pronouncedly. Likewise, sustainability commitments vary by industry, with some industries making visible progress, while others — often lower-margin ones — proving slower to embrace sustainability.
Overall, the velocity of sustainable AI is fast. There is a growing number of AI-driven sustainability initiatives, and we expect these to continue to grow in 2025. Moreover, the rapid development and adoption of small language models presents an opportunity for enterprises and product leaders to leverage GenAI models that are much more resource-efficient than generic LLMs. A critical driver is the alignment of cost and sustainability benefits: resource-efficient models are, in general, considerably cheaper as well.
We expect the breakthroughs demonstrated by DeepSeek to accelerate this trend, as with the lower costs and compute requirements the whole industry will move from large generic LLMs to more industry- and domain-specific models. The open-source nature of DeepSeek’s model helps other product leaders to speed up innovation that allows for lower inference costs associated with GenAI models. For example, DeepSeek specifically innovated around “inference-time computing” in which only the most relevant portions of the model are used for each query, therefore helping other companies to adopt scalable models more quickly.
A factor that may decelerate adoption revolves around technology providers’ steep infrastructure investments in the past two years. Through 2023 and 2024, major technology providers, including hyperscale cloud providers, invested billions to expand data center capacity and compute power. These investments represent enough sunk costs to slow down the shift towards more efficient language models.
Mass
The mass of sustainable AI is high because of its reach across most industries and geographic locations around the world.
Steps towards sustainable AI will be taken by companies in most industries to comply with regulatory requirements, to optimize operations, to reduce waste, to mitigate costs and to protect the corporate brand. However, the adoption of sustainable AI will not be uniform. At least over the next three years, there will also be many organizations that want to gain advantage from GenAI without much consideration for either costs or sustainability impacts. Since many factors drive the importance of sustainability, we expect a high degree of variability in the near term.
Organizations across all industries will embrace sustainability for its efficiency benefits, which will also result in cost reductions for many use cases. However, in the case of GenAI, productivity and efficiency benefits will have to be balanced against the cost premium attached to its use cases.
Sustainable AI can enable societies to raise their living standards through the economic benefits of ubiquitous AI applications, while mitigating climate change, protecting the environment and safeguarding people. Failure to achieve such positive net outcomes may lead to a high risk of a social and political backlash against AI as a whole — in addition to the environmental and social harms that unsustainable uses of AI stand to cause.
Sustainable AI will offer transformational capabilities because of its relationship to overall technology modernization initiatives. The pursuit of digital business operating models will encourage the use of technologies that promote efficiency, such as real-time data analysis. Likewise, the pursuit of sustainability will increase the use of modern, digital technologies (such as cloud services, which reduce the need for on-premises servers). The synergistic nature of modernization (including the use of AI) and sustainability will serve to increase the impact of sustainable AI.
Recommended Actions
- Prioritize sustainability in the development, delivery and support of AI solutions by ensuring that sustainability is included as a core tenet of all product and service development initiatives. When working with external vendors or partners (such as cloud providers), ensure they conform to sustainable AI standards.
- Optimize the development and use of AI models by investing in and deploying domain-specific language models that have significantly lower compute requirements.
- Develop sustainability solutions targeted at end-user organizations to assist in designing, implementing and operating AI solutions while adhering to sustainability principles.
Gartner Recommended Reading
Ultralong Context Window Models
Analysis By: George Brocklehurst, Ray Valdes, Eric Goodness
Definition:
Ultralong context window models are advanced large language models (LLMs) capable of processing over a million tokens, designed for complex tasks like in-depth research, code generation and large document analysis. They excel in in-context learning and adapting outputs based on input context, which enhances accuracy and relevance without needing retraining for new tasks.
Sample Vendors
AI21 Labs; Alibaba; Anthropic; Google; Gradient; IBM; Magic.dev; Mistral AI; Shanghai AI Laboratory
Range: 3 to 6 Years
The adoption of ultralong context window models, hindered by high compute needs, is expected to take three to six years, but efficiency innovations could accelerate this timeline.
Ultralong context models revolutionize in-context learning by processing extensive information during inference, allowing adaptation to new tasks without changing parameters. This capability facilitates real-time learning and many-shot learning, especially for low-resource languages, by leveraging numerous examples. By integrating multimodal data, these models enhance LLM flexibility and reduce their reliance on external tools, improving their performance in complex scenarios and quickly adapting them to diverse tasks.
However, ultralong context window models have historically struggled with maintaining accuracy and coherence, often focusing too much on the beginning and end of long inputs while overlooking the middle. Additionally, they have required more computational resources, complicating processing and memory demands. As a result, current adoption of models with context windows of one million tokens or more is primarily for use cases that were previously impossible or impractical, such as analyzing very long documents, understanding complex codebases and processing extended multimodal data.
The growing excitement around advancements in inference time scaling, coupled with recent breakthroughs in ultralong context window models, is set to draw significant attention to these technologies. Innovations announced in early 2025 have advanced many limitations associated with using extremely long context windows, offering several key improvements, including:
- Improved performance: Enhanced accuracy and consistency across a 1-million-token context window, achieved through innovations like dual chunk attention (DCA).
- Faster inference times: Processing inputs multiple times faster, reducing inference time from over 10 minutes to under two for a 1-million-token input.
- Lower computational demands: Cost reductions are realized through decreased GPU memory requirements by employing techniques such as sparse attention, chunked prefill and optimized kernels, which minimize both computational and memory access costs.
Recent developments in reasoning models, the competitive geopolitical landscape of AI and the ongoing vendor model wars are drawing increased attention to ultralong context window models. These innovations, now available as open-source models to the developer community, are set to accelerate adoption and further fuel interest in this area.
Mass: High
The impact of ultralong context window models is high because they enable in-context learning across markets, offering high value in specific domain use cases and resulting in broader mainstream adoption as efficiency improves.
Ultralong context window models enable enhanced data processing and efficiency. In software development, these models improve code synthesis by accessing complete codebases, accelerating development cycles and reducing errors. Their multimodal understanding integrates diverse data sources for holistic insights, crucial for sectors like market research. Additionally, they enhance complex reasoning and planning, offer expert-level insights in niche areas, and reduce inference costs, ultimately boosting productivity and transforming decision-making processes.
Gemini 1.5 Pro and its 10-million-token context window can analyze almost five days of audio recordings (107 hours), more than 10 times the entirety of the the book “War and Peace” (which is 587,287 words long), the entire Flax codebase (which has 41,070 lines of code), or 10.5 hours of video at 1 frame-per-second, providing insights previously unattainable.
Ultralong context window models are having a profound impact in specialized sectors, while offering steady advancements across mainstream applications:
- Specialized sectors: In legal and financial domains, they process extensive documents, such as contracts and financial reports, extracting critical information for compliance and decision making. In healthcare, these models analyze vast medical records and research papers, improving diagnosis accuracy and accelerating treatment development. In software development, they streamline code analysis and documentation, enhancing software quality. In research (such as, oncology, pharmaceuticals and materials science) and academia, they facilitate large dataset analysis and information synthesis, aiding comprehensive insights.
- Mainstream opportunities: Adoption will increase as innovations enhance efficiency and reduce inference times, making these models more accessible. They help by simplifying retrieval-augmented generation (RAG) systems, improving coherence, and enabling new tools and applications. Virtual assistants will benefit by being able to maintain context over extended conversations. Multimodal capabilities allow greater integration of text, images, audio and video, expanding utility. With improved in-context learning, these models adapt to new tasks and tackle complex challenges. When combined with smaller models, they make inference more cost-effective, and when integrated with open-source models, they lower the barriers to entry.
Recommended Actions
- Upgrade existing LLM systems by transitioning to ultralong context window models where RAG systems face challenges like complex queries, high latency, context loss, diverse data integration and unstructured data processing.
- Expand market reach by integrating or developing solutions with open-source models, which offer cost-effectiveness and accessibility, aligning with the growing interest in smaller, self-hosted models.
- Identify untapped opportunities for ultralong context window models in scenarios with complex decision making, cross-departmental integration, historical analysis, detailed profiling, multilingual and multimodal processing, high-frequency streams, and advanced queries.
Gartner Recommended Reading
6 to 8 Years
Active Inference
Analysis By: Eric Goodness
Definition:
Active Inference AI is an approach to artificial intelligence that imitates how the brain minimizes unexpected events from sensory inputs. Active inference is based on the free energy principle, a theoretical framework which combines perception, thinking and action to help systems predict and influence their surroundings. This approach focuses on continual learning, adaptability and real-time interaction. Unlike traditional AI, it processes real-time sensory data, makes transparent decisions and works well in physical environments. Although active inference is a theoretical framework, in practical applications it often uses generative models. However, training those models is different in that they learn through engagement and interaction with their environment, understanding how actions relate to observations and their causes. This is different from other generative AI technology applications, which learn passively from large datasets. Active inference AI is designed to help software, agents and machines make independent decisions in real-world situations without needing a lot of training data.
Sample Vendors
Active Inference Lab; OpenAI; Stanhope AI; VERSES
Range: 6 to 8 Years
The range for active inference is six to eight years from early majority adoption because the prevailing technical and design complexities reside in R&D labs with very few commercial entities dedicated to its commercialization.
Active inference is distinguished by its unique approach to modeling intelligence based on the free energy principle and its focus on minimizing surprise. Active inference includes the following key features, which contribute to its being relatively far from early majority adoption:
- Generative Models: Like generative AI, active inference uses models to understand data. However, active inference emphasizes learning through active engagement with the environment, unlike generative AI, which learns passively from large datasets.
- Active Learning: Active inference systems actively gather information to reduce uncertainty. They perform “experiments” and choose actions that increase knowledge, unlike traditional AI, which relies on existing data.
- Unified Framework: Active inference combines perception, action and planning. It infers hidden causes of sensory data, guides actions to reduce prediction errors and evaluates actions to minimize future surprises. This integrated approach is different from systems that handle these functions separately.
- Embodiment: Active inference involves interaction with the environment through actions, helping agents learn and adapt better. This is different from traditional AI, which doesn’t actively shape its sensory experiences.
- Minimizing Uncertainty: Active inference treats perception, action and learning as processes to minimize the difference between predicted and actual sensory inputs, guiding behavior and optimizing interactions with the world.
Although there’s growing interest and some R&D successes in active inference, only a few startups and labs are focusing on it.
Despite its commercial potential, active inference faces several challenges:
- Computational Complexity and Scalability: Active inference requires complex calculations, especially for updating beliefs and planning. As environments become more complex, these calculations become costly. To address this, efficient algorithms and techniques like variational inference and sampling methods are needed. Research is also exploring distributed active inference and parallel computing to improve scalability.
- Designing Generative Models: Creating accurate generative models for specific tasks is challenging. These models need to reflect the relationships between hidden states, actions and observations, often requiring prior knowledge. In complex environments, learning these models is difficult. Active inference systems must explore their environment, gather data and refine models over time, balancing complexity to avoid oversimplification or excessive intricacy.
- Symbol Grounding: Active inference systems learn by interacting with their environment. Developing ways for these systems to grasp concepts and apply them to new situations is crucial. Early efforts to combine active inference with symbolic AI, knowledge graphs and Semantic Web technologies show promise.
- Handling Unexpected Events: Active inference systems rely on model predictions, but unexpected events or unfamiliar data can be challenging. Developing mechanisms to detect and adapt to new situations is essential. Research is exploring anomaly detection, fallback strategies and active exploration for learning in unfamiliar contexts.
- Commercial Interest and Adoption: While innovation has mainly come from universities and smaller startups, interest from established tech companies is expected to accelerate commercialization and adoption in the next six to eight years.
Mass: High
The mass for active inference is high because the systems enable new approaches to agentic AI based on other systems that learn from experiences with outputs that are explainable.
Active inference will be adopted across most use cases and industries where agent interactions are valued and necessary. The most promising use cases for active inference to yield highly valuable outcomes include:
- Robotics and Autonomous Systems: Helping them adapt to changing environments, and sensing and making decisions in real time, improving tasks like object manipulation and navigation
- Warehouse Robots: Navigating and performing tasks in cluttered spaces
- Autonomous Vehicles: Improving safety and decision making in traffic
- Drones: Assisting in search and rescue, monitoring and inspections
- Smart Cities: Integrating with the Spatial Web to manage urban systems efficiently, adapting to real-time changes in traffic, energy and safety
- Traffic Systems: Optimizing signals and reducing congestion
- Energy Grids: Balancing supply and demand, and integrating renewables
- Public Safety: Anticipating threats and coordinating responses
- Scientific Discovery and Research: Aiding in seeking information and testing hypotheses for use in fields like climate science and social dynamics
- Drug Discovery: Optimizing experiments and predicting effects
- Climate Research: Simulating scenarios and finding interventions
- Social Science: Modeling information spread and predicting trends
- Financial Modeling and Risk Management: Valuable for adapting to changes and predicting financial outcomes, managing portfolios and detecting risks
- Trading Algorithms: Adjusting strategies based on market conditions
- Risk Assessment: Analyzing data and mitigating vulnerabilities
- Fraud Detection: Identifying unusual transactions and patterns
Active inference represents a transformative approach to creating intelligent systems as it is a massive shift from passive AI systems trained on static datasets. It is the transition toward AI that integrates perception, cognition and action (agency coupled with purposeful behavior).
Recommended Actions
- Ensure access to state-of-the-art R&D and successful technology transfer for your product leaders by partnering with universities and private R&D labs at the forefront of active inference systems development.
- Broaden your AI and data science team by hiring (or incubating) research teams with expertise in the intersections of neuroscience and AI to include model embodiment and symbolic AI, explainability and causal inference, and the development of novel generative models able to learn on sensory input.
- Reduce product-market-fit risks for active inference by engaging the prospective buyers that are most likely to benefit from active inference. These could include manufacturers of robotics and automotive, transportation and logistics, advanced users of AI in financial services, or municipal and national governments that have demonstrated willingness to engage in public-private partnerships to deploy advanced, emerging technologies for their citizenry.
Gartner Recommended Reading
Emerging Technologies or Trends Watchlist
The items listed here include technologies and trends that were considered but are not yet included because, in our judgment, it’s too early to evaluate them or they have not yet demonstrated the potential for significant impact on the future of the area. This is not intended to be an exhaustive list; it serves as a view into some of the additional technologies or trends we have identified:
- Chain of thought
- GenAI simulation data
About the Impact Radar
This Emerging Technologies and Trends Impact Radar content analyzes and illustrates two significant aspects of impact — when we expect it to have a significant impact on the market (namely, the range); and how big of an impact it has on relevant markets (specifically, mass). Each emerging technology or trend profile analysis is composed of these two aspects. See Note 1 for a complete description of our approach to this research.
In this document, profiles are organized by range and mass. Impact Radar range starts with the center and moves to the outer rings of the radar. The emerging technology’s position on the impact radar represents when it will cross the chasm from early adopter to early majority. The rings represent one to three years, three to six years and six to eight years from crossing the chasm.
Mass is rated from very high to very low, represented by the size of the bubble on the Impact Radar Graphic. The higher the mass score, the more broadly the Emerging Technology or Trend is predicted to be adopted, and the more revolutionary the innovation is expected to be.
The objective of this research is to guide product leaders on how emerging technologies and trends are evolving and impacting areas of interest. Providers can leverage this knowledge to determine which technologies or trends are most important to the success of their business and when it makes sense to advance their products and services by investing in them. Technology vendors should use this Emerging Technologies and Trends Impact Radar to:
- Identify emerging technologies and trends that are important to the success of their business
- Determine when to act upon those trends and technologies based on business strategy
- Begin formulating a response to the technology or trend’s evolution
Acronym Key and Glossary Terms
| LAM | Large action model |
| LLM | Large language model |
| RAG | Retrieval augmented generation |
| SD | Synthetic data |
Note 1: Research and Methodology for the Emerging Tech Impact Radar
The Emerging Tech Impact Radar content analyzes and illustrates two significant aspects of impact:
- When we expect it to have a significant impact on the market (specifically, range)
- How big an impact it will have on relevant markets (namely, mass)
Analysts evaluate range and mass independently and score them each on a 1-to-5 Likert-type scale:
- For range, this scoring determines in which radar ring the emerging technologies and trends will appear.
- For mass, the score determines the size of the radar point.
In the Emerging Tech Impact Radar, the range estimates the distance (in years) that the technology, technique or trend is from crossing over from early adopter status to early majority adoption. This indicates that the technology is prepared for and progressing toward mass adoption. So at its core, range is an estimation of the rate at which successful customer implementations will accelerate. That acceleration is scored on a 5-point scale, with 1 being very distant (beyond eight years) and 5 being very near (within a year). Each of the five scoring points corresponds to a ring of the Emerging Tech Impact Radar graphic (see Figure 1). Those emerging technologies and trends with a score of 1 (beyond eight years) do not qualify for inclusion on the radar. When formulating scores for range, Gartner analysts consider many factors, including:
- The volume of current successful implementations
- The rate of new successful implementations
- The number of implementations required to move from early adopter to early majority
- The growth of the vendor community
- The growth in venture investment
Mass in the Emerging Tech Impact Radar estimates how substantial an impact the technology or trend will have on existing products and markets. Mass is also scored on a 5-point scale — with 1 being very low impact and 5 being very high impact. Emerging technologies and trends with a score of 1 are not included in the radar. When evaluating mass, Gartner analysts examine the breadth of impact across existing products (specifically, sectors affected) and the extent of the disruption to existing product capabilities. It should be noted that an emerging technology or trend may be expressed in different positions on different Emerging Tech Impact Radars. This occurs when the maturity of emerging technologies and trends varies based on the scope of radar coverage.