Rethink Enterprise Search to Power AI Assistants and Agents
9 April 2025 - ID G00825644 - 17 min read
By Stephen Emmott
Despite the advent of AI assistants and agents, employees struggle to find information for their work. Enterprise applications leaders need to rethink enterprise search as supporting rather than competing with AI assistants and agents.
Overview
Key Findings
- The insight employees need to make decisions and act depends on information that resides in many and varied repositories within the organization.
- Information is hard to find due to fragmented and underdeveloped search and retrieval capabilities.
- Synthesis of information by retrieval-augmented generation (RAG)-based generative AI assistants and agents underperforms when scaled across enterprise data.
- The sources of information — primarily the content of files — are rarely managed to support retrieval and synthesis, resulting in the abundance of redundant, obsolete or trivial (ROT) content versus accurate, pertinent and trusted (APT) content.
Recommendations
- Automate the retrieval and synthesis of information by providing assistants and agents powered by enterprise search.
- Selectively optimize existing capabilities for the retrieval and synthesis of information by auditing and reconfiguring the search and synthesis touchpoints already within your application portfolio, especially before introducing new application capabilities.
- Rationalize underlying services by taking a strategic approach to the retrieval and synthesis of information and facilitating the proliferation of touchpoints to form a cohesive portfolio of capabilities.
- Institute content governance for all data sources to manage content and optimize the retrieval and synthesis of information.
Strategic Planning Assumption
By 2028, employees will be informed through proactive synthesis rather than reactive retrieval of information 80% of the time.
Introduction
According to Gartner’s 2024 Digital Worker Survey,1 a third of employees (34%) say it is a struggle to find information sometimes or more frequently (see Note 1). Half of employees (49%) use everyday AI tools or applications for work, including Microsoft 365 Copilot and Google Gemini; these employees rank “help finding information or data to do my work” as the No. 1 purpose for using these tools. Yet, a third of these tool users (36%) say they sometimes or more frequently struggle to find information. Everyday AI is not delivering to expectations, in large part due to obstacles associated with leveraging organizational data.
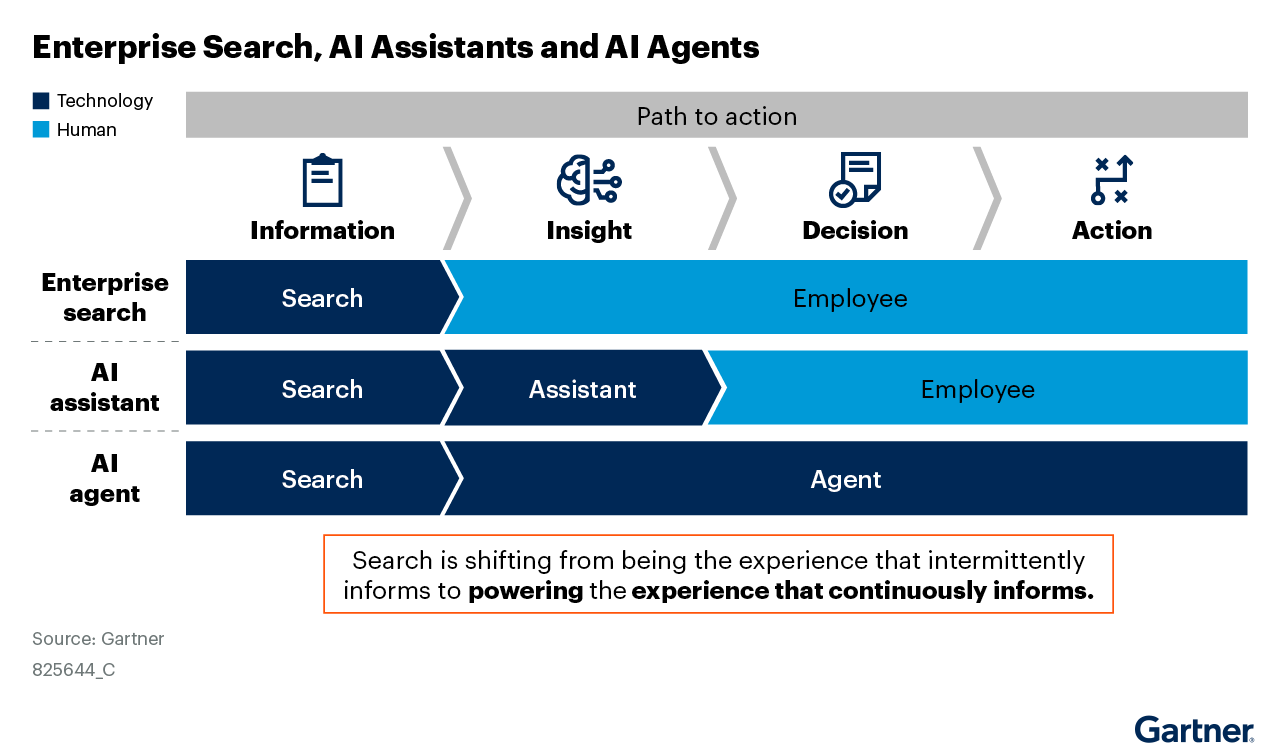
Search is shifting from being the experience that intermittently informs to powering the experience that continuously informs.
So, how should search, assistants and agents be provided to ensure that employees have the information they need to decide and act? Employees need insight and therefore information, not tools and techniques. And they need this where and when their work is taking place. Semantic search is now attainable using vectorization, and language can be synthesized using generative AI. Consequently, search — the indexing and query-based retrieval of data — is shifting from being the experience to powering the experience. (See Figure 1, which illustrates the fundamental role search plays as integral to assistants and agents.) Search augments assistants, with employees deciding and either acting or delegating action to automation technologies. Going further, agents have the upper potential to decide as well as act.
Analysis
Automate Information for Insight
Employees need insight to make decisions and act. Insight — deep and accurate understanding — depends on knowledge plus information. But given the pace of change, there’s too much to know and what is known may be irrelevant or no longer valid. Consequently, information has become the greater part of insight in today’s organization. Information augments knowledge by reshaping the mind, improving our ability to comprehend present circumstances.
With the advent of generative AI, it has now become possible to not only retrieve, but also synthesize information. RAG-based AI assistants and agents enable relevant fragments of existing information to be retrieved and resynthesized into new information, whether interactively as part of a conversation, or proactively based on user behavior and activity.
In the context of organizational data, synthesis of accurate information depends — for the main part — not on the model(s) used but upon the retrieval of relevant data from multiple repositories, each of which serves other purposes. These repositories and the data they contain are rarely managed to support retrieval and synthesis beyond the primary application. While impressive demonstrations abound, and experiences are substantially improved, this still falls short of need when scaled for use across enterprise data, due to the same issues that blight traditional search.
Without retrieval of accurate, pertinent and trusted data, the answer is likely to be wrong no matter how coherent and plausible the response. Positioning employees so they are informed in their business moments, with the information needed in that context, means thinking of information not as an artifact, but as a process — moreover, one that is automated so the employee does not have to perform the retrieval and synthesis themselves.
The state to which enterprise applications leaders should be working is one where information is approached as the process of informing within the context of applications: automated retrieval and synthesis of content to provide insight in the context of business moments.
To attain this state, enterprise applications leaders should:
- Reposition enterprise search as the means by which existing data is retrieved to support other applications and touchpoints, notably AI assistants and agents, that synthesize information. This shifts enterprise search from being the experience to powering the experience.
- Focus on the provision and delivery of assistants and agents supported by enterprise search, rather than enterprise search per se, to support information as an automated process integral to applications.
Optimize Existing Touchpoints and Their Underlying Services
Organizations provide myriad touchpoints for search by default rather than by intention. As Table 1 illustrates, search (and synthesis) is provided both as dedicated applications as well as within other applications, whether installed locally on employee devices or hosted elsewhere.
Touchpoints and Services for Search & Synthesis
Search & Synthesis in Apps | Search & Synthesis as Apps |
|
|
Note: These are examples; the lists are not exhaustive. | |
Source: Gartner (April 2025)
Taken together, the number of touchpoints to search available to the employee extends to double figures. Included within this are the new touchpoints that go beyond search by providing not just the retrieval but also synthesis of information (i.e., assistants and agents such as Microsoft 365 Copilot and Google Gemini). Each touchpoint is powered by a search service, which is sometimes dedicated to the touchpoint (e.g., Salesforce’s Einstein Search) and sometimes shared (e.g., Coveo). This means that multiple, separate indexes and configurations apply across touchpoints. Any given data asset may be indexed by one, multiple or none of these search services. The way in which the relevance of a query/prompt is assessed against indexed content will vary from service to service, meaning each touchpoint is likely to respond to the same query/prompt in different ways and therefore with different results (see Note 2).
Finding the information that employees need starts with deciding where to search — which of the many touchpoints to use. This requires effort and time to conduct one or more searches to gather and assimilate information. The path of least resistance is to use only the nearest and easiest touchpoint. More importantly, each touchpoint may not deliver all, or even any, of the information that is actually available in the source repositories. Data that is indexed by these technologies may be indexed two or more times. Furthermore, some data will not be indexed by any of the technologies, silently omitting it from retrieval and synthesis and therefore rendering it unavailable to employees. Employees will be unaware that the information received from touchpoints is neither definitive nor comprehensive, nor that the experience will vary across touchpoints.
The state to which enterprise applications leaders should be working toward is the delivery of information where it is needed to support decision and action in the flow of work. Wherever they find themselves in the enterprise applications portfolio, employees must at best have immediate access to the information they need; at worst, they must at least see signposting to reach the touchpoint(s) through which they can access the right information. Whichever touchpoint they use needs to leverage the index containing the data that is appropriate to the information needed from that touchpoint, retrieving all relevant information.
To attain this state:
- Audit all touchpoints to search and synthesis by using the categories search & synthesis in applications and search & synthesis as applications. Include within this audit the employee groups each touchpoint serves and the touchpoint’s underlying service(s).
- Develop personas for key employee groups in terms of value to your organization and which depend most on retrieval and synthesis. Focus on the top three groups, such as R&D engineers, sales agents, brokers, lawyers, physicians, lecturers, etc. You can add more personas later, but focus on three at any given time (see Ignition Guide to Creating Employee Personas).
- Prioritize your touchpoints to search and synthesize by using the audit cross-referenced with your top three personas to identify the touchpoints that matter most (i.e., those touchpoints that are most important to the employees who have the most to gain).
- Optimize the performance of prioritized touchpoints by reconfiguring them and their underlying services using the product’s own administrative interface. Focus on the repositories and data they index, relevance of results, and signposting to other touchpoints as appropriate.
- Help employees utilize the touchpoints available to them for best effect by issuing contextual guidance within the touchpoints themselves. This could be a capability of the touchpoint’s product (e.g., using suggestions or other contextual links), engineered as a built add-on (e.g., developing existing UI templates) or added through the overlay of a digital adoption platform (see Market Guide for Digital Adoption Platforms).
Rationalize Underlying Services
Having multiple touchpoints for search and synthesis served by many search services results in a complex portfolio of technologies serving overlapping purposes. Few if any touchpoints are typically managed. In-application search-and-synthesis touchpoints are often left to the supplier, which is typically the application leader, the vendor or a solution provider. In contrast, there may be a dedicated person or team aligned to touchpoints as applications. But the majority of touchpoints being in-application means many teams and individuals for whom the touchpoints are just one of many capabilities. This leads to a siloed approach and the diffusion of responsibility.
Multiple touchpoints and therefore multiple search services mean overlap in terms of indexes and usage. This results in unnecessary costs, both direct and indirect. Direct can include license/subscription, compute and storage. Indirect can include staff time spent maintaining wrong decisions due to incorrect information and missed opportunities due to lack of information. In addition, dependence on a range of underlying technologies and configurations means that the way in which queries/prompts are evaluated varies, resulting in a need for different skills and experience to maintain and optimize these technologies.
The state to which enterprise applications leaders should be working is optimum touchpoints to information provided through maximum applications with minimum services. This points to an ideal of one underlying service serving all touchpoints, whether delivered as applications or in applications. But this is unrealistic in practice because application portfolios have many hundreds of applications from almost as many vendors, few of which fully interoperate in the ways required to attain the ideal, even from the same vendor.
Trade-offs are therefore necessary to ensure information is delivered from underlying technologies that are rationalized. For instance, enterprise applications vendors are now providing their own agents in the context of their applications, such as CRM, in ways that prohibit use in other vendors’ applications yet require the vendor’s underlying services for retrieval. This is an obstacle to consolidation. So, until circumstances change, it is necessary to signpost and advise users. For example, include a comment such as, “Insight gleaned via this touchpoint will relate only to this application’s data. For more comprehensive answers, use [application + link] touchpoint.”
To attain this state:
- Establish responsibility for all search and synthesis technologies by assigning them to one person in the enterprise applications team. That person will ideally already be centered on as-application touchpoints and services, if you have them, with responsibility then extended to in-application technologies.
- Consolidate to as few vendors and technologies as possible while permitting multiple touchpoints in or near the applications where work is carried out by starting with as-application services before extending to in-application services.
- Reduce cost after portfolio consolidation by rationalizing the underlying search and synthesis services and associated technologies (see 7 Steps to Rationalize Your Application Portfolio).
Institute Content Governance
Ensuring that employees are continually informed relies upon having APT data to retrieve and synthesize. While there are exceptions, data in this context typically means the content of files such as documents, videos, images and sound recordings that themselves reside in applications (SharePoint, Google Drive, OpenText, etc.). For that reason, it is often referred to as “content” rather than data.
Ownership is clear with respect to the content of the files: It is owned by individuals and their business units (of which IT is one). So too with the applications: They are owned by IT. What is not clear is who owns the files within which content exists. IT will consider them owned by business units and individual employees. But individual employees and their business units can and will either claim or renounce ownership depending on the circumstances. When claimed, ownership of files is distributed across many individuals and their business units. When rejected, the files are abandoned until an issue arises, at which point ownership defaults to IT as owners of the application within which the files are stored. In truth, an organization’s files have a complex and shifting matrix of ownership, accruing the ultimate consequence of shared ownership over time: neglect.
The impact of neglect includes files that contain ROT content, leading to multiple versions of files, duplicated files within and across multiple applications, or both. Furthermore, security permissions set to defaults can result in access for those who are unauthorized or denial for those who are, loss of content due to inappropriate deletion, and too few files being systematically and purposefully deleted or retained. For retrieval and synthesis, this is a significant problem because given multiple versions with duplicates, the authoritative version cannot be discerned without purposeful analysis of the files and their content.
The state to which enterprise applications leaders should be working is one where content is APT, not ROT. At any point, the content of files and records held within applications should be easily auditable, and the right content retrievable for use. Ideally, this leads to the establishment of an information governance/management framework to assess, manage and optimize the use of information across the enterprise applications portfolio. Related to this is the systematic use of metadata, both in terms of development and attribution (see Note 3).
To attain this state:
- Establish policy for the governance of files across all applications in the enterprise applications portfolio by working with your CIO and CDAO.
- Manage the organizations’ files in accordance with the established policy by identifying one role or team in IT with the relevant skills and authority, if one is not already in existence — such as information governance or information management. Generally speaking, this is usually missing and only the CDAO and their team have the data management skills and implicit remit required, but this may vary for your organization.
- Enable files to be managed (and retrieved) without having to inspect their content by systematically attributing metadata to them. Use automated attribution with manual oversight.
- Manage files to reduce ROT in favor of APT by conducting systematic audits and aligned maintenance work. Include deletion or archiving of files and reviews of file permissions to ensure they are appropriate for the files’ content, ideally in the context of an information management framework.
1 2024 Gartner Digital Worker Survey. This survey sought to understand workers’ technological and workplace experience and sentiments. The research was conducted online from April through July 2024 among 5,141 respondents, who were from the U.S. (n = 1,121), Australia (n = 1,086), India (n = 996), the U.K. (n = 973) and China (n = 965). Participants were screened for full-time employment in organizations with 100 or more employees and were required to use digital technology for work purposes. Ages ranged from 18 through 74 years old, with quotas and weighting applied for age, gender, region and income, so that results were representative of countries’ working populations. We defined “digital technology” as including any combination of technological devices (such as laptops, smartphones and tablets), applications, and web services that people use for communication, information or productivity. Disclaimer: Results of this survey do not represent global findings or the market as a whole, but reflect the sentiments of the respondents and companies surveyed. Year-on-year comparison is conducted for the set of countries that remain consistent across the years being analyzed. The United States, United Kingdom, China and India are the countries included in this comparison.
2 2022 Gartner Digital Worker Survey. This survey sought to understand workers’ technological and workplace experience and sentiments. The research was conducted online from September through November 2022 among 4,861 respondents from the U.S. (n = 1,564), China (n = 1,167), the U.K. (n = 1,072) and India (n = 1,058). Participants were screened for full-time employment in organizations with 100 or more employees and were required to use digital technology for work purposes. Ages ranged from 18 through 74 years old, with quotas and weighting applied for age, gender, region and income, so that results are representative of working country populations. We defined “digital technology” as including any combination of technological devices (such as laptops, smartphones and tablets), applications, and web services that people use for communication, information or productivity. Disclaimer: Results of this survey do not represent global findings or the market as a whole, but reflect the sentiments of the respondents and companies surveyed.
Note 1: The Struggle to Find Information
The struggle to find information has eased since we last ran the same survey in 2022,2 when the number was nearly half (47%). This improvement coincides with the growth of everyday AI tools and applications, especially assistants such as Microsoft Copilot and Google Gemini, in the workplace. The 2022 survey was completed before the launch of ChatGPT. The 20241 survey revealed that everyday AI tools or applications are used by 49% of respondents for work purposes.
Note 2: Search Experiences Vary
Such touchpoints and their underlying services are rarely adapted, developed and configured by employers to match the needs of their employees in the context of their work. Typically, touchpoints are provided in the default state offered by vendors, or with minimal configuration to address the essential needs of the employers’ principal provider (IT, vendors or solution providers) rather than the consumer of information (employees). For instance, the employer’s essential needs include deciding which repositories should be indexed, ensuring compliance with legal and regulatory constraints, ensuring corporate visual appearance, and ensuring integration of enterprise applications.
Note 3: Metadata
The content of files and the purposes that content serves are often difficult to discern from the files themselves. While the filename and location are indicative, they are not reliable. Instead, the content of the file must be analyzed and assessed anew each time it is considered for use, which is costly whether done by human or machine. To limit this, metadata is used to describe the file and its content, thereby aiding its use without having to inspect its content. This could include many parameters such as owner (e.g., Emile Wing), business unit (e.g., Accounts Payable), creation/modification date/time, file type (e.g., PDF), content type (e.g., Policy), classification (e.g., Confidential), PII (e.g., true), and so on.
Once attributed, metadata aids the management of files but also their retrieval as well as the synthesis of their content. For example, when searching for the policy relating to an HR matter, restricting the search using just two metadata values — policy documents and latest operational version — greatly improves relevance relative to keywords alone.
Despite its advantages, metadata is rarely used systemically by organizations due to the difficulty associated with establishing and attributing it to files. Without metadata, files become much more difficult to manage and retrieve, which compounds and is compounded further by increasing levels of ROT.