Enhance Generative AI Data Management With Intelligent Storage
24 June 2025 - ID G00829957 - 12 min read
By Chandra Mukhyala
Generative AI applications are consuming and creating vast amounts of unstructured data, which is best-suited for key-value-based rather than traditional file-based storage. Infrastructure platform leaders should use key-value storage and integrated intelligence to improve GenAI costs and performance.
Overview
Impacts
- Generative AI (GenAI) applications are creating large amounts of new unstructured data consisting of text, code and multimedia. In addition, GenAI input prompt, vector and operational data are all contributing to additional demand for new storage.
- Unstructured data platforms storing large amounts of GenAI data require integrated data intelligence, in the form of rich metadata, combined with metadata querying capabilities to further optimize data access efficiency.
- The use of both high-performance file systems and object storage for AI data processing is creating confusion around which solution best supports GenAI workloads.
Recommendations
- Deploy key-value-based object storage with integrated intelligence and multi-protocol access when building new GenAI application data stores to improve on cost and performance.
- Move GenAI data preparation tasks from data analytics applications directly into the storage platform to improve data pipeline efficiency and cost.
- Shift workloads that do not modify source data from existing file storage systems to key-value object stores with multi-protocol access to eliminate the overhead of file systems.
Strategic Planning Assumptions
- By 2029, key-value-based object storage will store 50% of on-premises unstructured data, up from less than 10% in 2025.
- By 2029, global demand for new storage capacity from generative AI will exceed 2 exabytes, up from less than 1 exabyte in 2024.
Introduction
As enterprises begin scaling the number of GenAI applications in production, they will experience emerging demand for large amounts of new storage capacity. Gartner estimates that global demand for new storage capacity from GenAI will increase by 500% by 2040. GenAI by its nature creates new data that didn’t exist before. In addition, the applications also consume large amounts of data as input, such as prompts for inference, vector representation of raw data and the source training data itself.
All of this new data requires new storage capacity, which raises the question: What is the optimal type of storage for this newly generated data from GenAI? Infrastructure platform leaders must select the right type of storage data platform to control costs, boost performance and optimize efficiency for these massive new data volumes. While public cloud applications mostly leverage object storage, unstructured data in on-premises data centers is typically hosted on scale-out network-attached storage (NAS) or distributed file systems, which are not the optimal choices for GenAI workloads.
GenAI applications are demanding from a performance point of view, because they need to process vast amounts of data to generate new content. But much of the processing happens in the compute layer of the infrastructure stack, not at the storage layer. While storage is a critical foundation layer of the infrastructure stack, its primary purpose is to store and feed data at high speeds to the compute layer, not to manipulate the data.
This distinction of not manipulating the source data is critical to understand since it influences the right type of storage to use for GenAI applications. High-performance compute applications typically use parallel or distributed file systems, so infrastructure platform leaders assume the same type of storage is best for GenAI. That is not necessarily true. Key-value-based object storage combined with integrated data intelligence, which adds context and meaning to the underlying data, is the ideal type of storage for GenAI applications (see Figure 1).
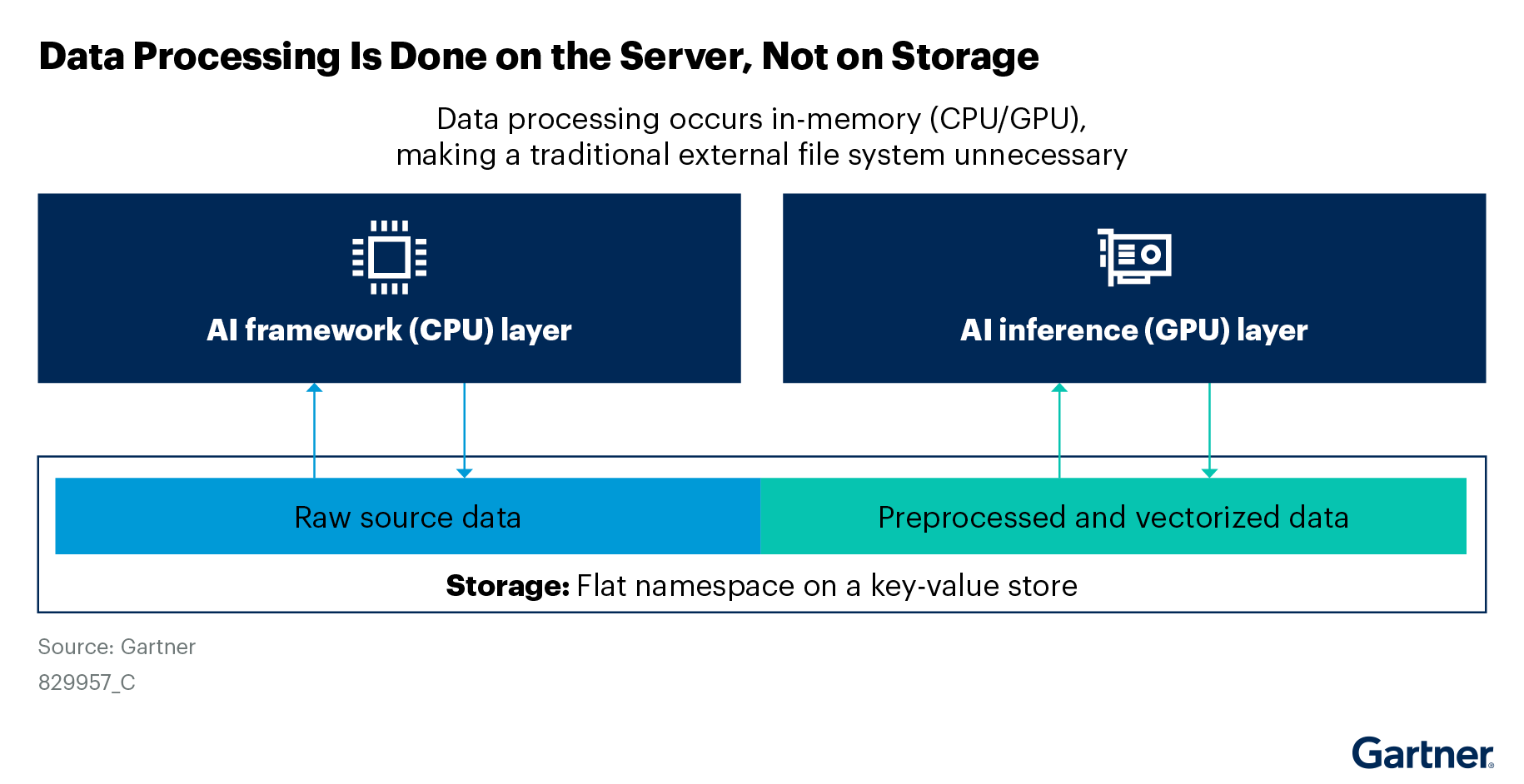
Key-value based object storage is a distinct form of storage for storing unstructured data in a flat namespace versus using a hierarchical file system. In key-value storage, data is stored as an object, and every object has an associated key which has the address of the object and the metadata describing it. This is also known as object storage, but not all object storage products in the market are built on a flat namespace. Some object storage products are built on top of an external file system or block storage, and some others on a Linux or other file system.
Key-value stores do not use any file system: They are based on a flat namespace. A flat namespace is a critical part of the definition and allows scaling of the repository to host hundreds of billions of objects and exabytes of capacity. Modern key-value-based object storage also includes integrated data intelligence.
Integrated data intelligence enables storage systems to add context to unstructured data by processing data to create custom metadata and/or storing the data in a semistructured format. This allows applications to query selected objects and/or select fragments within an object, as opposed to reading entire objects. This capability turns storage systems from passive data repositories into intelligent systems that can retrieve selected unstructured data at a subobject level.
Impacts and Recommendations
GenAI Applications Create Large Amounts of New Unstructured Data Which Add to Storage Demand
Organizations will see increased demand for unstructured data storage capacity to store new data types. These include:
- Generated content (outputs): GenAI applications will create completely new unstructured data that didn’t exist before, consisting of text, software code, image, audio and video files. In addition, GenAI can be used to create synthetic data, which is artificially created data, that mimics real-world data for training AI models.
- Input and training data artifacts: This includes prompts used in inferencing, datasets for fine-tuning, and embeddings and vector representations, all of which can consume more capacity than the underlying source data.
- AI model and operational artifacts: This includes model weights and checkpoints, log files from training and inference, audit logs and model configuration files, among other data.
- Archive of AI data: Regulatory and business requirements to retain AI data for long periods.
Figure 2 below shows a scenario for the potential demand in increased storage capacity from the combination of the above factors. This is an estimate to show the shape of the growth curve and the contributors of the demand. Petabytes of capacity is only an estimate.
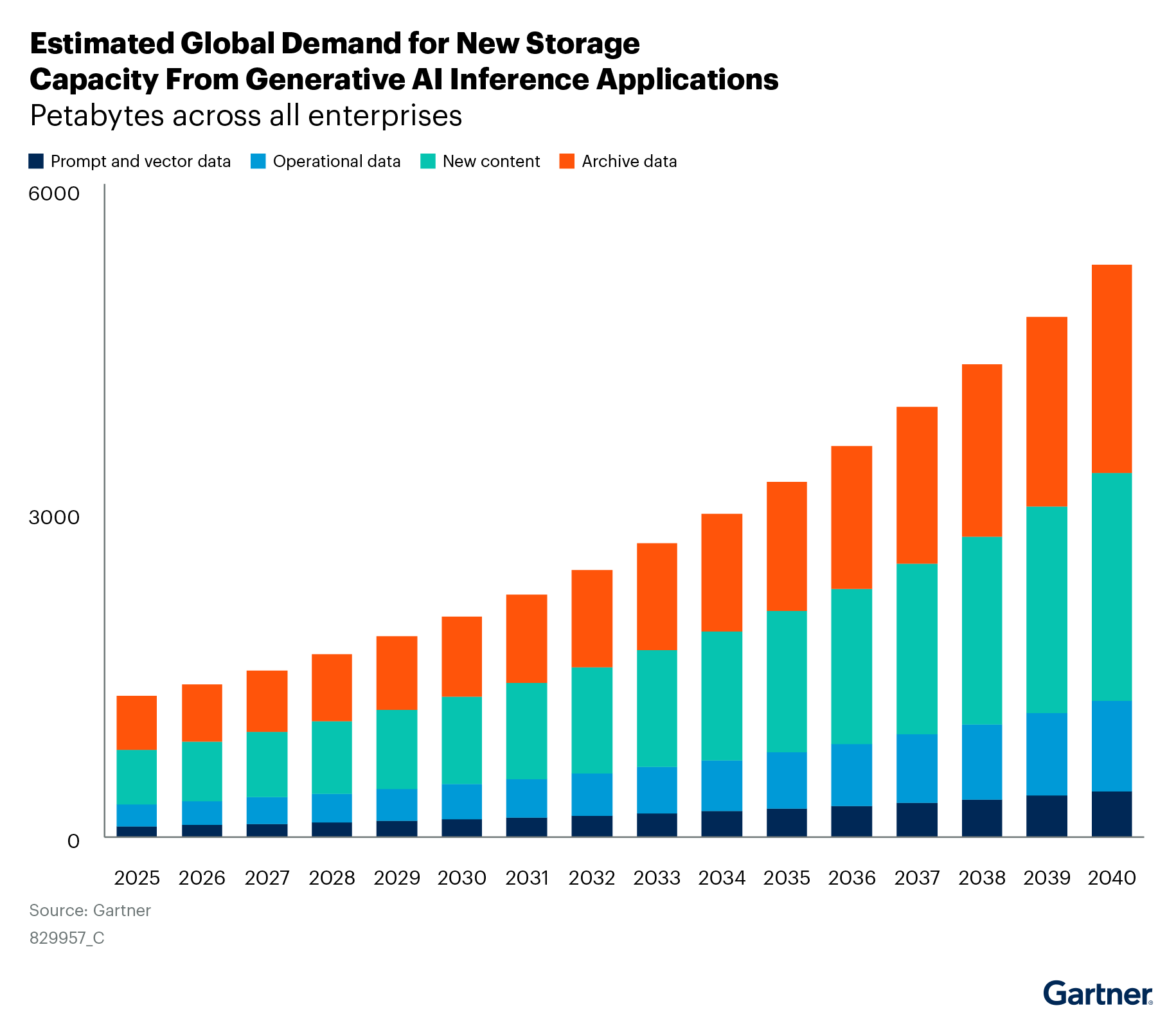
All this data did not exist before organizations adopted GenAI, and some of this new data may have to be retained for long periods. In addition, a lot of this new data will not be active data, but must still be retained. While the new storage capacity demand for an organization will depend on their AI ambitions, it is clear that organizations must prepare for this growth by selecting the right type of storage for this new data to improve cost and performance efficiency.
GenAI Is Processed on the Server Not on the Storage System
The graphics processing unit (GPU) servers where the large language models (LLMs) are running don’t always access the raw source data from the storage systems directly. Instead, they access the data from intermediate storage which hosts the vectors representing the source data. That intermediate storage is typically an internal nonvolatile memory express solid-state drive (NVMe SSD) within the GPU server.
The data preprocessing tasks which clean, filter and normalize the data are performed by AI frameworks, such as Apache Spark. And the Spark servers or AI framework tools don’t process the data on storage arrays, they process it in memory. The preprocessing servers also transform the normalized data into vectors. They read large blobs of data in megabytes, process in memory and write back the large blob consisting of the vector data. This does not require any file locking or manipulation of data on the storage array.
Since it is the machines reading and writing the data, there is no need for a hierarchical structure, which can add latency when traversing through billions of objects. From a storage perspective, GenAI writes blobs of data and reads it back, but does not manipulate the underlying data. Given these reasons, key-value-pair-based storage implemented as a flat namespace is the ideal way to host the underlying unstructured data.
Larger GenAI Context Windows Need Key-Value Storage
Newer versions of LLMs are supporting larger context windows requiring large GPU memory to store the context information in the form of a key-value cache. When key-value pairs need to be evicted off the cache, they get offloaded from GPU memory to CPU memory. External storage can serve as another tier of persistent cache for storing those key-value pairs.
When an inference request comes in that refers to context from a previous request, these key-value pairs will need to be read back into the GPU server at very high speed in order to not increase latency of inference requests. Modern object storage offerings implemented as key-value storage on a flat namespace is the optimal type of storage to provide the high throughput demanded by the key-value cache in the GPU servers.
Recommendations
- Deploy key-value-based object storage with integrated intelligence and multi-protocol access when building new data stores for GenAI applications to improve cost and performance. All phases of GenAI applications, whether for model training, fine-tuning or RAG-based inference will benefit from key-value-based object storage. While modern distributed or parallel file systems can scale just like a key-value-based flat namespace to hundreds of billions of objects, they are not necessary and can add complexity in both day-to-day operations and troubleshooting. The complexity comes from the inherent overhead in-file system required to manage byte range file locking, among other aspects. This is removed with key-value-based storage accessed via a stateless protocol like S3. Examples of such offerings are Pure Storage’s FlashBlade and DDN’s Infinia.
For RAG use-cases, if existing data is already on a distributed file system, it is not necessary to move that data to separate key-value storage, but if new storage has to be deployed, use that as an opportunity to shift to key-value-based storage.
Unstructured Data Platforms Storing Large Amounts of GenAI Data Require Integrated Data Intelligence
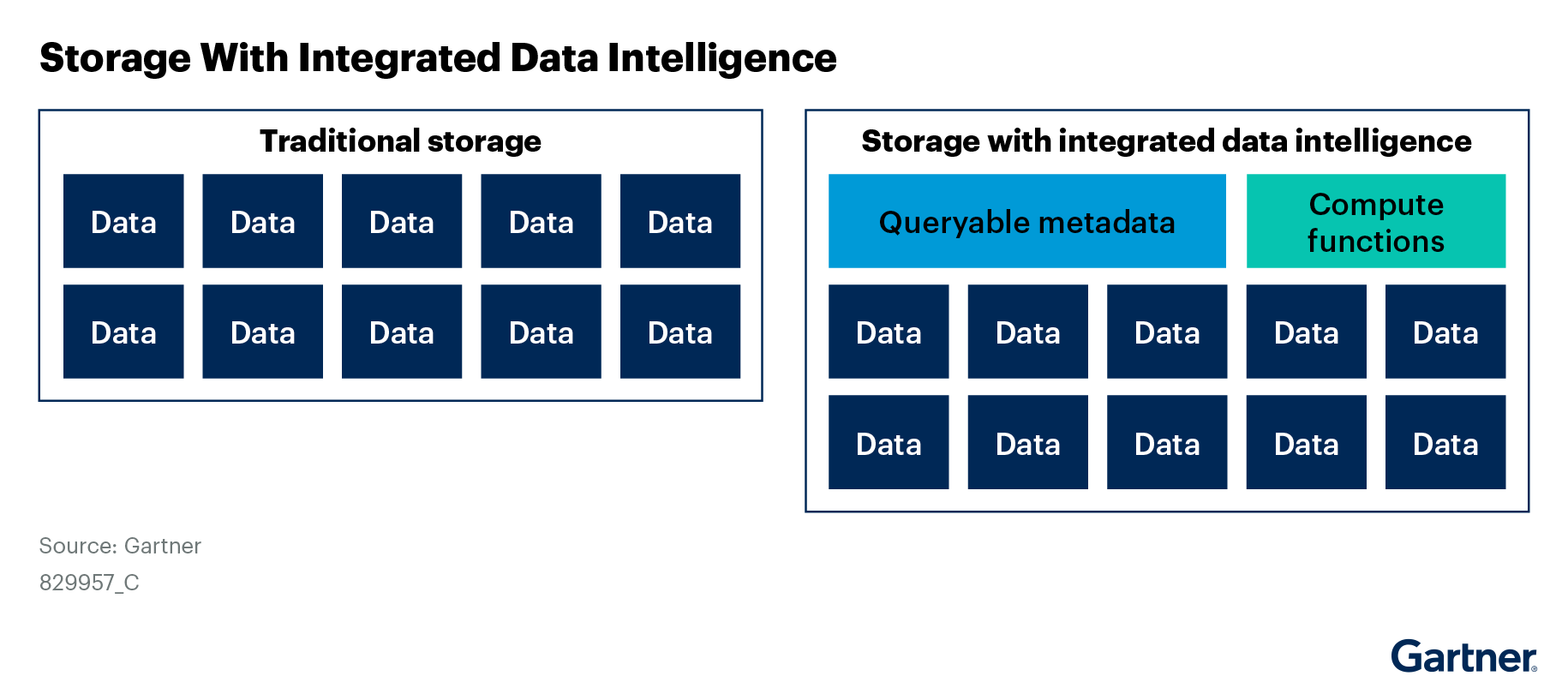
Before data can be consumed by any AI application, the underlying source data will need to be preprocessed. But when starting with hundreds of terabytes or petabytes of unstructured data involving billions of objects, there needs to be an intelligent way to find the relevant data quickly from the source data. Traditional approaches for finding the relevant subset of the data involve copying the data to a separate data analytics platform, which analyzes the data first and provides a means to query subsets of that data. However, the process of copying the data to a separate data lake is inefficient and expensive due to the need for added storage capacity.
Accelerating Data Discovery With Integrated Intelligence
Modern object storage products offer an innovation called integrated data intelligence, which is highly efficient at finding the relevant objects from hundreds of billions of objects stored in a key-value store. This is typically done by adding custom metadata to objects by running microservices on the objects. The microservice itself can be an AI inference application, or a custom microservice which generates special labels or custom metadata to quickly identify selected objects.
Examples of such offerings are the VAST Data Platform, from VAST Data and HPE’s Alletra Storage MP X10000. In addition, modern object stores create an index of the enhanced metadata, which allows querying the metadata in a SQL-like query language to select relevant objects from among billions of objects stored.
Figure 3 summarizes the difference between traditional storage and integrated data intelligence.
Recommendation
- Move GenAI data preparation tasks from data analytics applications directly into the storage platform to improve data pipeline efficiency and cost. Modern key-value-based object storage systems provide various ways to process the underlying object to extract context and insights that can be used to enhance the metadata. Leverage such capabilities to minimize copying data from the storage layer to a separate data analytics perform. This will not only result in the efficiency of the AI pipeline but also reduce the total cost of the infrastructure.
Use of Both High-Performance File Systems and Key-Value-Based Object Storage Is Creating Confusion
Hierarchical file-system-based storage is suboptimal for GenAI applications. This is because GenAI workloads don’t manipulate source data or rely on granular POSIX file semantics features such as byte-range file locking.
Key-Value Object Storage Advantages Over Hierarchical File Systems
Using key-value-based object storage implemented as a flat namespace, versus scale-out hierarchical file-system-based storage provides the following benefits for AI inference and training use cases:
- Massive scale to host and serve hundreds of billions of objects
- Simpler operations and troubleshooting from the stateless nature of object access protocols such as S3
- High throughput read and writes of blob data, especially when the access is implemented over RDMA
When to Stick to Hierarchical File-System-Based Storage
There are two broad scenarios when using file-system-based storage is best:
- File systems are the right choice for applications that frequently modify the data, especially granular edits in large files. Transactional applications that perform frequent read/write operations within a file or object, and/or applications that depend on byte-range locking of files for file sharing and collaboration are best suited for file systems. Inadvertently putting true file-based workloads on key-value stores can lead to severe performance and scalability problems.
- File systems are also a better option when the total amount of data is small enough that a single or a couple of storage servers can host all the data. Key-value-based object storage products are typically implemented as distributed systems using erasure coding techniques to deal with rebuilding data lost from disk or other hardware failures. Such systems typically require a minimum of three or four nodes to form the initial cluster necessitating a minimum capacity requirement. For small capacity deployments when the data can fit within a server or a server with attached disk shelves, a key-value store can be overkill.
Examples of distributed or scale-out file-system-based storage products are Dell’s PowerScale and Qumulo’s Cloud Data Fabric offerings.
Recommendation
- Shift workloads that do not manipulate data from existing file-based storage to key-value-based object stores with multi-protocol access. Many legacy applications are not necessarily transactional and may not require file locking but depend on hierarchical structure and file-level security for user authentication. Such applications can still be based on key-value stores with file-based access protocols such as NFS and SMB. A key-value store that supports multi-protocol-access object interfaces, such as S3, and file interfaces will satisfy a broad set of unstructured-data use cases. This limits file-based systems to the niche use cases of transactional applications requiring frequent I/O or user-collaboration.
- Gartner client inquiries
- Vendor briefings
- Practitioner interviews