Innovation Insight: Beyond Process Mining and Analysis — The Future Is Process Intelligence
23 September 2025 - ID G00840603 - 11 min read
By Tushar Srivastava, David Sugden, and 1 more
A fragmented understanding of processes is a hidden drag on digital transformation, process automation, and GenAI ambitions. Process intelligence unifies modeling, design, mining, and monitoring, enabling you to visualize workflows, identify inefficiencies, and act on data-driven recommendations for improvement.
Overview
Key Findings
- Enterprises often rely on subjective opinions of stakeholders to create an operating model for their business processes. In times of uncertainty and disruptions, this flawed understanding makes decision-making difficult and unreliable when meeting customer needs and expectations or identifying cost-cutting opportunities.
- Customer attrition and an inability to improve the customer experience often stem from enterprises lacking visibility and consistent, up-to-date documentation of their business processes. Without this clarity, organizations struggle to understand how they deliver value to customers and miss opportunities for meaningful improvement.
- Many enterprises remain stuck in a reactive cycle, addressing process issues only after problems arise. This lack of proactive, continuous improvement leads to slower responses to market changes and missed opportunities for innovation and competitive advantage.
Recommendations
- Leverage process intelligence tools and their data-driven techniques, such as process and task mining, to objectively assess your current operating model. Use these insights to simulate and document a target (“to be”) operating model for your processes across various scenarios.
- Implement automation and GenAI-based agents to drive faster decision-making and improve customer experience by leveraging process intelligence tools that provide visibility, standardized documentation, and actionable insights, giving you the foundation for effective, data-driven transformation.
- Prioritize continuous monitoring and improvement by leveraging process intelligence. This proactive approach enables you to anticipate challenges, adapt quickly to change, and foster a culture of innovation.
Introduction
Enterprises today face new complexities in identifying and addressing process inefficiencies.
- Organizationally, they struggle to maintain real-time, unified process knowledge and ensure consistent, actionable documentation amid rapid change.
- Technologically, they contend with data overload, fragmented systems, and the challenge of scaling automation and AI-driven discovery beyond pilot phases.
Limited process visibility and unmanaged data (especially unstructured) hold back digital transformation, automation, and agentic ambitions, allowing inefficiencies to go unnoticed with traditional discovery methods.
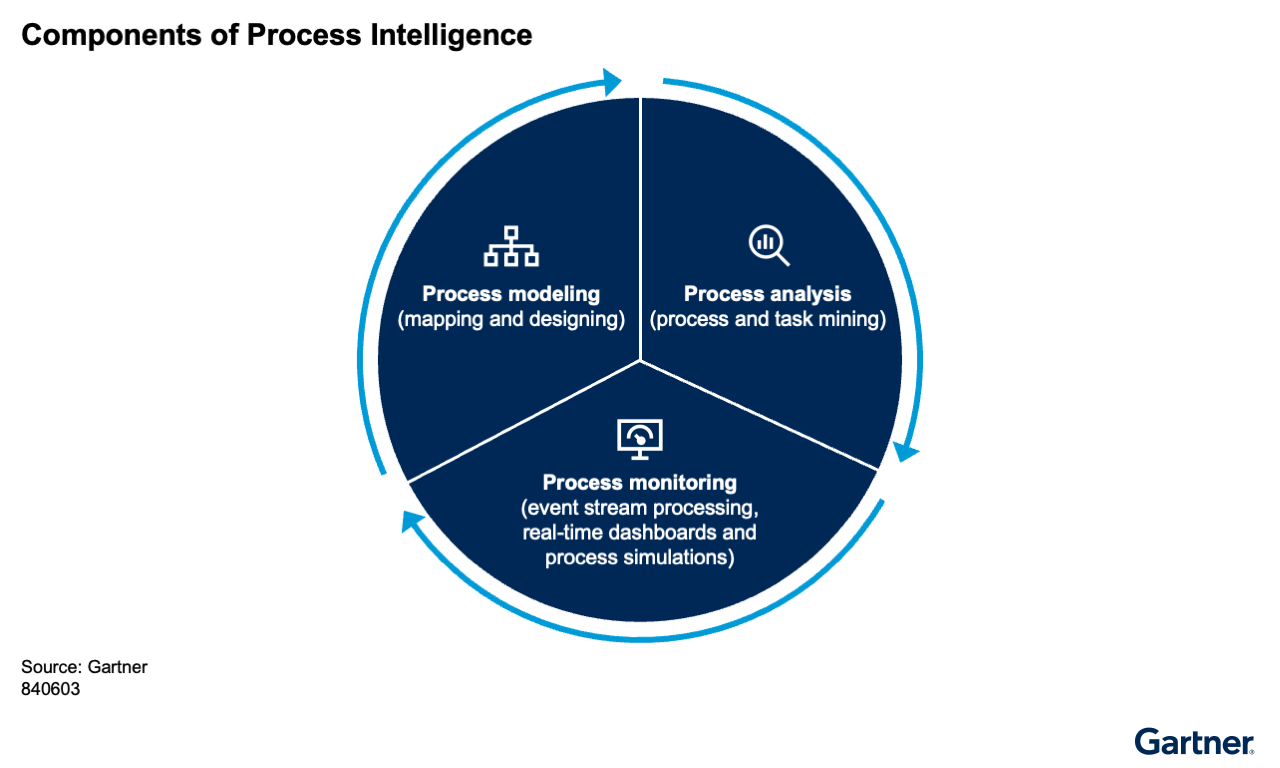
Process intelligence addresses these challenges by combining traditional and data-driven discovery methods within a single platform (see Figure 1). It leverages standardized (e.g., BPMN-based) process documentation to establish consistency, and then enriches those models with process and task mining insights for regular updates. The approach, which is layered with simulations, KPI analysis, and tracking, along with real-time monitoring help to uncover hidden variations and edge cases, delivering an end-to-end view and driving continuous process improvement.
Description
Process intelligence platforms combine development and runtime software tools to analyze, model, and monitor business processes. They offer capabilities such as process mapping and mining, in-depth analysis, real-time alerting, SLA and threshold-based tracking, anomaly detection, performance dashboards, and interactive decision support by providing data about current processes and their conditions.
What Are the Components of Process Intelligence?
We have identified three major components of process intelligence, with each having its own subcomponents.
Process Analysis
- Process mining. Process mining offers analysis of processes by extracting event data from information systems. This includes automated process discovery, conformance checking, social network/organizational mining, automated construction of simulation models, model extension, model repair, case prediction, and history-based recommendations. Process mining offers advanced process analytics, process improvement detection, and process improvement recommendations.(see Magic Quadrant for Process Mining Platforms)
- Task mining. Task mining is a combination of techniques to infer useful information from low-level event data available in UI logs derived from the underlying operating system or through observing application UI interactions. This data comes from individual users or cohorts through screen recordings, keystrokes, mouse clicks, and data entries. Task mining helps an enterprise identify inefficiencies and automation opportunities, increase worker productivity, and enhance the employee experience.(see Market Guide for Task Mining)
- KPI analysis. These capabilities include descriptive and predictive models, dashboards, simulation, and scenario testing, enabling operational decision support.
Process Modeling
- Contextual models. These models include business architecture landscape viewpoints that address stakeholder concerns by providing context, events, rules, and requirements using multiple views tailored to different roles (see Market Guide for Enterprise Business Process Analysis Tools)
- Customer journey mapping and experience design. This capability provides a way to model and analyze client interactions.
- Modeling and analysis of business operations. These operating models capture how capabilities and other resources are deployed to deliver value to the organization’s stakeholders and provide a link to day-to-day operations (see Market Guide for Digital Twin of an Organization Platforms).
- Decision models. This capability also includes possible integration with decision model execution tools such as rule engines (see Market Guide for Decision Intelligence Platforms).
Process Monitoring
- Real-time dashboards and KPI tracking. This capability can visualize process performance metrics (e.g., cycle time, throughput, error rates) as they happen and enable drill-down into specific steps, cases, or time periods.
- Automated alerts and notifications. This capability offers integrated observability and can trigger alerts when predefined thresholds or SLA violations occur. It also routes notifications to responsible stakeholders via email, SMS, or collaboration platforms.
- Exception and root cause analysis. This capability can automatically detect deviations or bottlenecks in running processes and provide diagnostic insights (e.g., variant comparisons, conformance checks) to help identify and remediate underlying issues.
- Event stream processing. By ingesting and correlating multiple real-time data streams against your process models, this capability identifies meaningful patterns and deviations as they occur, and can automatically trigger corrective actions, alerts, or adaptations within workflows.
Benefits and Uses
Process intelligence is an evolution for enterprise applications leaders, shifting them from reactive, siloed analysis to proactive, data-driven business model adaptation. Invest in this technology for process visibility, surface automation, and AI opportunities.
What Are the Benefits of Using Process Intelligence?
Identifying Interdependencies of Processes and Tasks
By extracting event data and visualizing every step, enterprises can connect multiple threads of processes and their accompanying tasks at the granular level. For instance, from customer onboarding through claims settlement for an insurer, end users gain the clarity they need to close the gap between strategy and execution.
This leads to:
- Improving customer experience
- Adjusting processes to customers’ needs without inconveniencing the customers
- Identifying and analyzing bottlenecks’ root causes
- Identifying automation opportunities (see Market Guide for Business Process Automation Tools)
- Discovering agentic workflow opportunities
- Enforcing governance and regulatory requirements through continuous conformance checks and flagging SLA breaches before they impact customers
- Accelerating transformation
- Testing business continuity scenarios
The insights from the above execution-driven analysis feed directly into process models, maps, documentation, and process standard operating procedure (SOP) documents.
The benefits are twofold:
- Preventing costs caused by making decisions on incorrect documentation and out-of-date artifacts for future IT modernizations, ERP transformation, or process automation initiatives
- Jump-starting process modeling, target operating model creation, collaboration, and business handoffs for organizations that start without baseline process models, covering over half the effort needed to define and document workflows upfront
Process intelligence is already essential to specific AI initiatives such as predictive maintenance, generative process design, and intelligent document processing, because these applications rely on accurate, end-to-end process context and real-time monitoring. Without a grounded, data-driven view of how work actually happens, AI models often underperform or produce misleading recommendations. Process intelligence ensures that AI programs can learn from reliable inputs and drive genuine business impact by delivering clean event data, uncovering hidden variations, and continuously validating process models.
For example, insurers use process intelligence to accelerate claims and underwriting workflows. At the same time, banks leverage predictive and prescriptive analytics, real-time dashboards, and audit and compliance monitoring to track loan‐approval SLAs and flag governance risks. Manufacturers, meanwhile, employ process-based simulations and scenario testing to model “what‐if” supply chain changes and optimize production schedules.
What Are the Use Cases of Process Intelligence?
The process intelligence market can be segmented into five use cases. Figure 2 illustrates the key use cases as well as key capabilities.
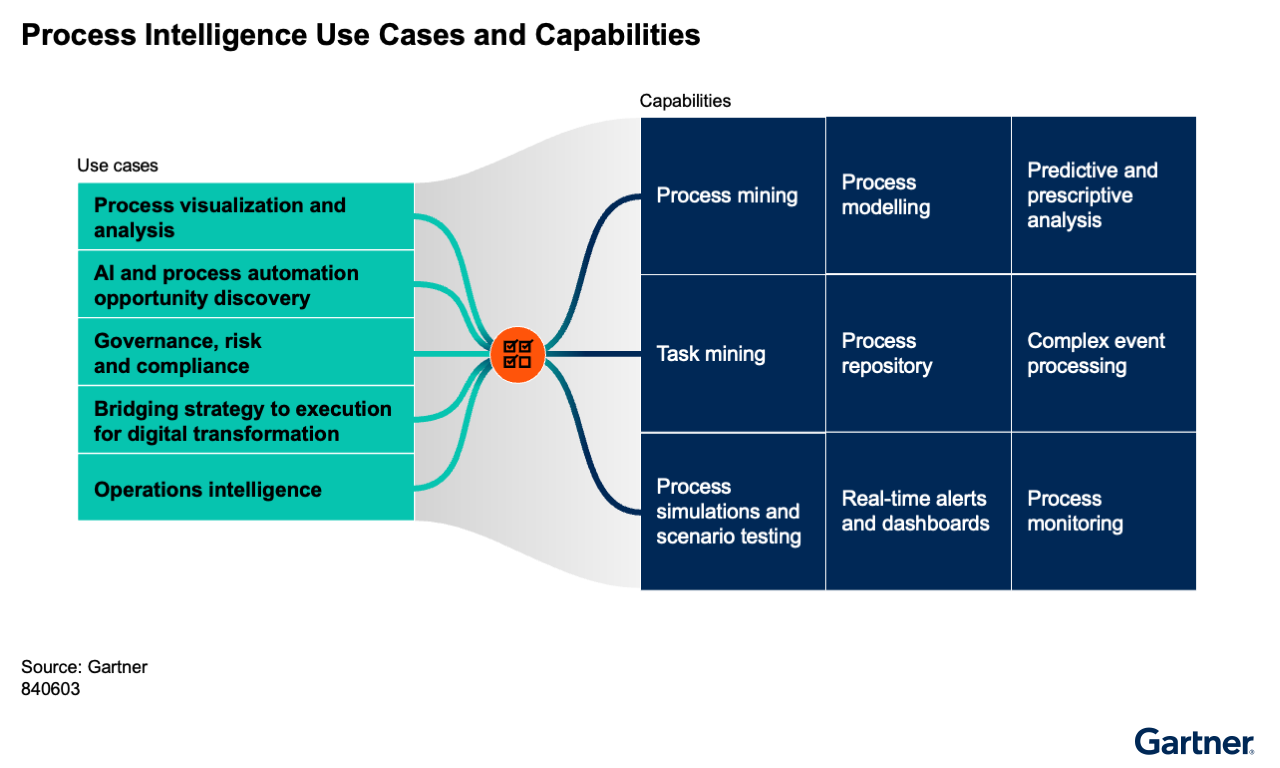
Process Visualization and Analysis
This use case is essential for enterprises that want to visualize their processes by extracting event logs from multiple IT systems to reconstruct business process flows. Through visual modeling and mapping, they compare actual execution against designed models and compliance rules, identifying deviations, bottlenecks, and nonconformant steps for targeted improvements and audit readiness.
AI and Process Automation Opportunity Discovery
By analyzing task and process-level data, the platform can pinpoint repetitive, rule-based activities and manual handoffs ideal for task and/or process automation or AI augmentation and help discover and design an agentic workflow. This use case delivers prioritized opportunity lists with estimated ROI, assisting enterprises in accelerating automation initiatives and maximizing efficiency.
Governance, Risk, and Compliance
Continuous monitoring of process executions against regulatory requirements and internal policies ensures real-time compliance visibility. Automated audits, conformance checks, and risk scoring highlight policy violations and control weaknesses, empowering stakeholders to mitigate risks, enforce governance standards, and maintain audit trails.
Bridging Strategy to Execution for Digital Transformation
This use case closes the gap between strategic planning and daily operations by providing data-driven actions. For example, once leadership sets a target customer-satisfaction score, process intelligence tracks metrics such as response times and handoff delays and alerts teams to corrective steps. If market data signals a demand surge, the platform simulates impacts across manufacturing and logistics, recommends adjustments, and updates roadmaps. Organizations ensure every decision directly supports customer outcomes by linking objectives like cost-to-serve reductions or quality improvements to live performance indicators and actionable triggers.
Operations Intelligence
Operational teams leveraging real-time dashboards, SLA tracking, and anomaly detection continuously monitor live process performance. Alerts surface imminent issues such as delays or exceptions, while historical and predictive analytics guide rapid root cause analysis, enabling swift corrective actions and sustained efficiency gains.
Risks
Table 1 outlines significant process intelligence risks and corresponding mitigation strategies.
Process Intelligence Risks and Their Mitigation Strategies
Risk | Mitigation |
Poor data quality and event logging. Poor data quality and inconsistent event logging can undermine process mining efforts, often yielding no actionable insights until logs are cleaned and standardized. Organizations must first understand and document their processes to generate reliable event data, then invest significant effort in normalizing and enriching logs before any modeling or mining can deliver real value. | Validate and normalize source-system logs by ensuring each event log includes at least a unique case or transaction identifier to correlate related events, accurate timestamps for sequencing, and relevant activity names or codes. Run small proofs of concept on these enriched logs to confirm data fidelity and build trust in the data before full deployment. |
Misaligned expectations between process owners and IT. Misaligned expectations between process owners and IT can lead to noisy, irrelevant models that fail to deliver actionable insights. IT may provision data pipelines, event-log integrations, modeling frameworks, and runtime environments, but without the business actively refining scope, filtering variants, and setting success criteria, mined and modeled processes yield low-value outputs. Embedding process intelligence requires creating a process-centric mindset across the organization — defining clear roles and responsibilities, adopting shared methodologies and frameworks, and establishing joint governance — to ensure IT and business teams collaborate effectively from start to finish. | Establish a collaborative cadence from day one to co-define the processes to be analyzed, agree on key performance metrics, and iterate on initial discovery results so that process owners validate, prune, and refine the models before deeper analytics or automation recommendations begin. |
Misconfigured process models and simulations. Incorrect process modeling or scenario testing assumptions can produce misleading what-if outcomes, skewing process documentation. | Start with simple subprocess models, validate against real execution data, and iteratively refine simulation parameters based on feedback. |
Overreliance on predictive and prescriptive analytics. Blind trust in AI-driven prescriptions without human oversight risks suboptimal or noncompliant process changes. | Embed governance checkpoints in decision workflows, require manual signoff for high-risk recommendations, and monitor outcome accuracy. |
Scope creep in governance and compliance modules. Attempting full end-to-end GRC enforcement from Day 1 can delay value realization and complicate tool configuration. | Phase in audit and compliance monitoring by targeting critical controls such as segregation of duties checks, approval workflows for high-value transactions, and data-access restrictions. Then, incrementally expand your process repository and SOPs to support broader GRC capabilities. |
Invalid or misleading metrics. Tracking the wrong KPIs or setting vague goals, such as “automation,” without defined benefits, generates false positives and negatives, skews priorities, and erodes stakeholder trust. | Organizations must establish clear, outcome-based objectives (reducing error rates, accelerating specific activities, or increasing process consistency) before selecting metrics or processes to automate. Continually aligning these well-defined goals ensures that process engineering and automation efforts deliver measurable business value. |
Source: Gartner
Recommendations
- Integrate process modeling and mining into a continuous two-way feedback loop. This forms the foundation of process intelligence, enabling enterprises to optimize operations using real execution data.
- Define transparent governance within a shared repository for roles, ownership, risks, and policies.
- Regularly validate models against real execution data, refine blueprints based on insights, and foster cross-functional collaboration to drive continuous improvement.
- Adopt a unified, data-driven strategy that uses process intelligence for continuous process monitoring, advanced analytics, and process simulations to deliver tangible outcomes. This helps you to react faster to customer and market trends, pinpoint automation and optimization opportunities, enable predictive maintenance, and stress-test business continuity scenarios.
- Business process owners and IT team members should form a single, integrated team rather than maintain a superficial collaboration to define scope, validate data quality, and iteratively refine process models from the outset. This approach ensures generated insights remain actionable and aligned with business needs, reducing the risk of misaligned expectations.
- Process Mining Book, Fluxicon.
- The Process Mining Manifesto, IEEE Task Force on Process Mining.
- V. Leno, M. Dumas, M. La Rosa, F.M. Maggi, and A. Polyvyanyy, “Automated Discovery of Data Transformations for Robotic Process Automation.”
- V. Leno, A. Polyvyanyy, M. Dumas, M. La Rosa, and F.M. Maggi, “Robotic Process Mining: Vision and Challenges.”
- W. van der Aalst, “Process Mining, Data Science in Action,” Springer Verlag, 2016.