Innovation Insight for GenAI Infrastructure
10 July 2025 - ID G00828480 - 20 min read
By Chirag Dekate, Sushovan Mukhopadhyay
IT infrastructures and processes will strain under the compute-intensive demands of generative AI workloads, across on-premises, cloud and edge. Heads of I&O must augment existing IT infrastructures with AI infrastructure environments while carefully planning investments to align with business value.
Overview
Key Findings
- Architecting AI infrastructures requires a multilayered approach, from the physical foundation of silicon and cooling to the abstract logic of models and orchestration. Each layer presents critical choices with long-term implications for performance, cost and strategic flexibility.
- A failed AI initiative begins not with code, but with underestimating its physical demands, leading to cascading, costly consequences.
- Successful AI deployments escape “pilot purgatory” by linking infrastructure investment to a committed business case, while purely exploratory “science projects” devolve into costly, stranded assets.
Recommendations
- Derisk AI capital spending. Use cloud pilots to validate workload requirements and prove ROI before committing to on-premises infrastructure.
- Build an AI-ready data center by first building the foundation of power, cooling and rack density required to support deployments of graphics processing units (GPUs), AI accelerators, specialized networking and storage necessary for your AI scale.
- Prevent AI operational silos by integrating specialized skills into your core operations team and platform management into your existing automation and monitoring tools.
Strategic Planning Assumptions
By 2027, the power and cooling budget for on-premises AI at 100% of large enterprises will eclipse their entire IT hardware capital expenditure.
By 2029, the top 25% of large-cap enterprises that master AI factories will control over 75% of their respective markets, creating AI-driven oligopolies.
By 2029, 70% of large enterprises failing to effectively utilize AI factories will cease to exist.
By 2029, 70% of large enterprises failing to effectively utilize AI factories will cease to exist.
Introduction
With AI now a C-suite imperative, the head of I&O’s mandate is no longer just to operate infrastructure, but to translate business strategy into production-grade AI services (see 2025 CIO Agenda: Global Data and 2025 CEO Survey: AI Opportunities to Delayer Middle Management). To achieve this, the head of I&O must now run the company’s “AI factory,” a strategic shift that makes static capacity planning obsolete. Inside this factory, a single prompt triggers unpredictable, cascading workloads from API calls to vector queries and GPU steps.
This factory floor operates on unpredictable, cascading workloads, demanding a shift from static planning to dynamic orchestration that can navigate the dual risks of crippling underprovisioning and costly overprovisioning (see Note 1). The head of I&O’s role has transformed into architecting this intelligent fabric, resolving volatile inputs, from geopolitics and energy costs to supply chain and legal mandates, into a single, resilient platform strategy that dictates the critical build-or-lease decisions across the enterprise. The defining challenge of the AI era is to deliver a coherent platform strategy across on-prem, cloud and edge that resolves these competing pressures into a single, resilient infrastructure.
I&O must shift from planning for predictable peaks to absorbing the unpredictable, cascading computational bursts driven by agentic AI and retrieval-augmented generation (RAG).
The pressure on the head of I&O to deliver a resilient and modern AI infrastructure foundation is immense, and unfolding across three fronts:
- Heads of I&O must prevent AI infrastructure from becoming a silo. I&O’s mandate is not just to deploy compute clusters, but to build a unified data and management fabric that integrates the AI environment with the enterprise’s distributed data sources, security tools and application platforms.
- To master the new economics of AI, I&O leaders must enforce a strict financial governance framework (see CIOs Can Use IT Score for I&O to Improve Execution Capabilities). They must also justify massive capital investments by modeling the complete total cost of ownership (TCO), from facility retrofits and high-speed fabrics to multiyear energy costs, against the projected business returns. No build-out gets funded without a proven financial case.
- Heads of I&O must treat the acquisition of AI infrastructure hardware and the skills to operate it as a strategic risk. A resilient deployment strategy is paramount, treating the physical location of each AI cluster as an immovable, long-term commitment supported by rigorous analysis of component scarcity, export controls and data sovereignty laws.
Description
Architecting for AI infrastructure requires a multilayered approach, from the physical foundation of silicon and cooling to the abstract logic of models and orchestration. Each layer presents critical choices with long-term implications for performance, cost and strategic flexibility (see Figure 1).
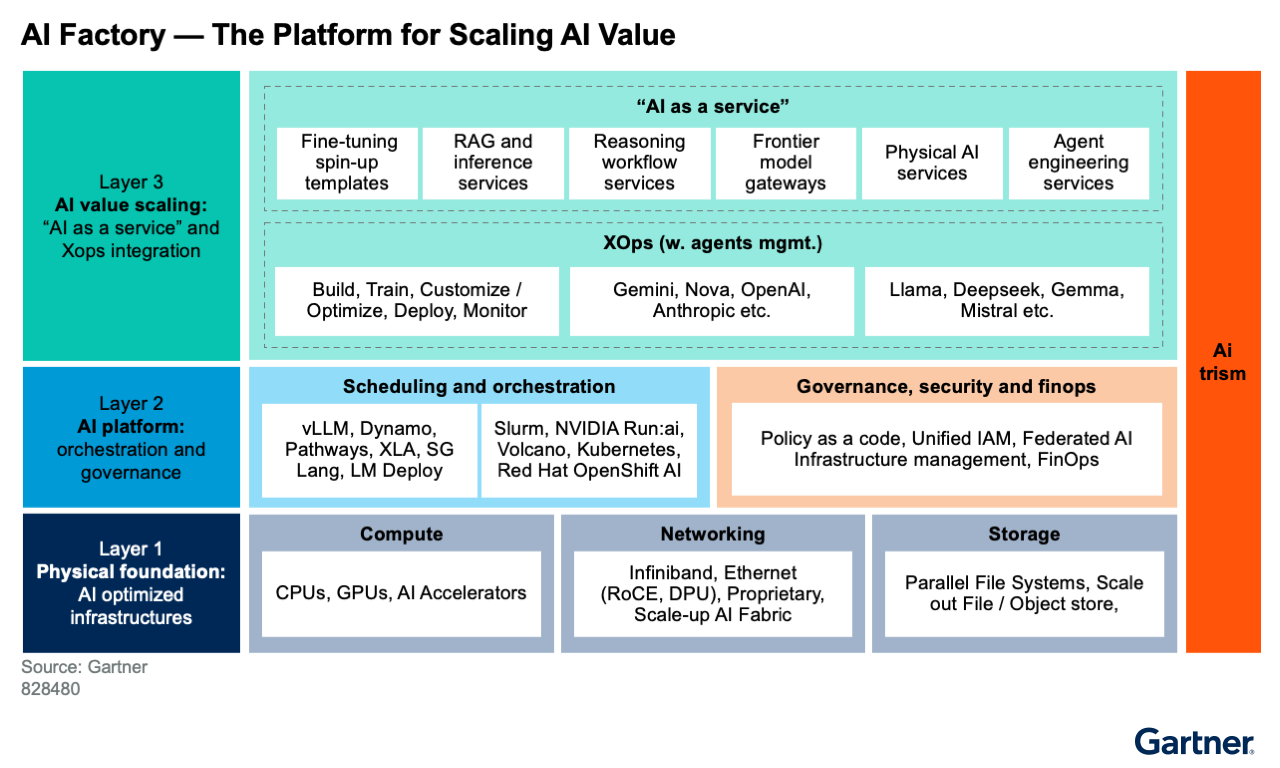
Layer 1: The Physical Foundation — AI-Optimized Infrastructures
The first foundational layer that heads of I&O must develop is a sophisticated AI infrastructure foundation. This requires shifting from a traditional IT infrastructure mindset to a diversified portfolio of AI-optimized stacks deliberately designed to optimize the total cost of ownership and performance. The core elements are detailed below.
Compute Accelerators
Stop seeking a single “best” chip and instead architect a diverse accelerator portfolio, matching the unique economic and performance profile of each option to a specific business case. This strategic calculus requires balancing on-prem options, from incumbent GPUs with their mature software moat to purpose-built application-specific integrated circuits (ASICs) with their transformative efficiency, against the TCO-versus-lock-in trade-off of cloud-native silicon. The final portfolio must be resilient, leveraging colocation for managed access to high-density facilities and sovereign accelerators where geopolitical assurance outweighs raw performance. Your accelerator portfolio strategy should align with these core delivery modalities:
- On-premises options
- Incumbent general-purpose GPUs: Deploy for maximum R&D and product velocity and diverse workloads, where attracting talent via a mature software ecosystem is critical.
- Challenger general-purpose GPUs: Target for massive, single-model training, where novel memory architectures can reduce infrastructure complexity and latency.
- AI accelerators: Use to slash TCO and power consumption for high-volume, static inference workloads like recommendation engines.
- Cloud and hosted options
- Hyperscaler-native silicon: Leverage for massive-scale inference and, when relevant for training, to optimize TCO when already strategically committed to a single hyperscaler’s platform.
- Certified colocation providers: Utilize to gain hardware control and meet data residency needs without the capital expenditure of a full data center retrofit.
High-Performance Networking
Choosing the AI factory’s network architecture is a critical decision with lasting financial and performance implications, forcing a strategic choice that transcends raw bandwidth: the simplicity of vertically integrated networks versus the flexibility of open standards. Heads of I&O must master the architectural trade-offs across on-prem, cloud and hosted deployments, addressing two distinct domains: the scale-out fabric connecting systems and the scale-up fabric connecting accelerators within a system, with options tailored to specific use cases (see Key Networking Practices to Support AI Workloads in the Data Center and What Are “Scale-Up” AI Fabrics and Why Should I Care?):
- On-premises options
- Scale-out:
- Lossless proprietary fabrics (such as InfiniBand): Deploy to minimize job completion time in large-scale training clusters where performance is the primary driver, accepting ecosystem dependency for operational simplicity, low latency and performance.
- Open-standard Ethernet (such as RDMA over Converged Ethernet [RoCEv2] and Ultra Ethernet Consortium [UEC-enhanced]): Implement to maintain vendor diversity and leverage existing talent, accepting a higher initial tuning burden (especially for emerging UEC-like standards) for long-term flexibility and cost control (see Critical Capabilities for Data Center Switching).
- Data processing unit (DPU)-augmented Ethernet: Use to offload network and security tasks from host CPUs, maximizing compute cycles for the primary AI workload, especially in multitenant environments.
- Scale-up:
- High-speed proprietary interconnects (such as NVIDIA’s NVLink): Use to train and inference the largest foundation models, where multiple accelerators must function as a single, unified processor with maximum bandwidth.
- Open-standard interconnects (such as UALink): Architect for future-state flexibility, derisking long-term strategy by preventing lock-in to a single vendor’s accelerator ecosystem.
- Cloud and hosted options
- Scale-out:
- Cloud-native fabrics (such as Amazon Web Services [AWS] Elastic Fabric Adapter [EFA] and Google Jupiter): The back-end fabric follows the accelerator, even in the cloud. Leverage cloud-native fabrics for hyperscaler silicon like tensor processing units (TPUs) and AWS’ Trainium, but expect to use InfiniBand for large-scale NVIDIA GPU clusters, tying your fabric choice directly to the accelerator ecosystem.
- All of the scale-up and scale-out options of on-prem are also available selectively in the cloud environments.
- Scale-out and scale-up in colocation:
- Utilize to gain control of on-prem hardware without the massive capital expenditure (capex) and time required for a full data center retrofit, ideal for regulated industries.
Storage Infrastructure Designed for AI
Traditional, capacity-optimized storage architectures fail to meet generative AI’s (GenAI’s) performance demands. The modern imperative is to architect a multitiered data fabric balanced for one purpose: maximizing data throughput to eliminate the accelerator starvation that cripples AI workloads. I&O’s role is to build this cohesive data services factory, not just a data lake. Your AI storage strategy should be focused on creating a data pipeline that is integrated with an AI workflow and optimized for specific workloads (see Top Storage Recommendations to Support Generative AI):
- On-premises
- High-throughput parallel file systems: Deploy as the training all-flash “hot tier” to deliver maximum throughput, keeping expensive GPU and ASIC clusters fully saturated with data by eliminating storage bottlenecks.
- All-flash distributed file systems and/or object storage platforms: Use as the core data lake for data preparation and mixed I/O workloads, engineered to handle billions of small files with high performance.
- Specialized AI data integrated platforms: Implement for MLOps-driven environments where data governance, versioning and workflow automation are critical for reproducibility and compliance.
- Cloud and hosted options
- Cloud-native high-performance storage: Leverage for cloud-based training, providing a managed, high-throughput file system that integrates seamlessly with a hyperscaler’s compute services.
- Cloud object storage as the foundation: Architect as the cost-effective, massively scalable persistence layer, serving as the gravity center for your entire hybrid AI data fabric.
Layer 2: AI Platform Orchestration and Governance
The second foundational layer that heads of I&O must develop is the platform and orchestration stack that transforms raw compute into a consumable, multitenant service. This requires shifting from deploying siloed applications to architecting a unified operating system for your AI factory, exposing supercomputing resources as a shareable, governable platform. The core elements are detailed below.
The Elastic Resource Orchestration Core
Architect a platform that transforms heterogeneous hardware into a fungible shared (multitenant) resource pool designed to manage the volatile demands of GenAI. Heads of I&O must build this cohesive AI factory operating system, enabling the dynamic, shared orchestration of both the development and deployment of AI products and agents to maximize the ROI on expensive GPU and ASIC investments.
Foundational control plane
- Cloud-native orchestration (such as Kubernetes): Use as the universal control plane across all environments (including on-prem, cloud and edge). This provides the standard, portable API for managing all containerized GenAI workloads and is the foundation upon which all other tools are built.
Specialized workload scheduling and orchestration
- Advanced AI orchestrators (such as those with NVIDIA Run:ai-like features): Layer on top of your Kubernetes foundation to enable dynamic sharing of accelerator clusters. This is critical for maximizing utilization by using queuing and fractionalization to run mixed training and inference workloads, a capability you can deploy in both your on-prem data centers and cloud instances.
- High-performance computing (HPC) schedulers (such as SchedMD’s Slurm): Integrate within your Kubernetes environment to provide raw throughput for massive, tightly coupled foundation model training. This allows you to run traditional HPC-style workloads on any infrastructure, whether it’s your own bare-metal hardware or a fleet of powerful cloud virtual machines (VMs).
Application-layer runtimes and engines
- Advanced inference engines (such as vLLM, SGLang, NVIDIA Dynamo and Google’s Pathways): Mandate these runtimes on your chosen infrastructure to slash the cost-per-token for production inference. Whether running on-prem for data privacy or in the cloud for scale, their novel memory techniques dramatically increase GPU throughput for the high-concurrency RAG and conversational AI applications that define modern GenAI.
Platform Governance, Security and FinOps
This part of the layer is the engine that transforms I&O into a strategic business unit by creating a transparent, auditable and financially internal service. Through this platform, the I&O mandate is to master the interplay of risk, cost and performance, enabling the enterprise to innovate faster and more safely.
Security, governance and risk management
- Policy-as-code enforcement: The key is to enforce identical, auditable security policies across your entire hybrid estate. This means a single security posture can automatically prevent a noncompliant container from running, whether it’s on an on-prem, cloud-based or hosted AI cluster, eliminating manual, location-specific reviews.
- Unified identity and access management: This becomes the system of record for attributing every action to an identity (human or machine), regardless of where the compute occurs. This unbreakable chain of custody is essential for debugging a hybrid agentic workflow or proving data residency during an audit, even when a job uses both on-prem and cloud resources.
Platform engineering
- Federated cluster management: The nonobvious goal is to enable strategic, cross-platform workload execution. A researcher should be able to submit a massive training job that starts on the on-prem Slurm cluster and, when resources are saturated, automatically bursts the overflow to a managed Kubernetes service in the public cloud, all managed as a single, seamless workflow.
- Holistic observability and tracing: This is no longer for debugging a single application; it’s for securing the entire, distributed AI supply chain. A unified observability stack must trace a problematic AI output back through a cloud-hosted inference API to the specific on-prem AI cluster where the model was last fine-tuned and to the data source it was trained on.
FinOps
- AI FinOps and cost governance: This evolves from cost control into profit and loss (P&L) management for the entire hybrid AI factory. The platform must provide a single, unified view of costs, showing a business unit a single bill that combines the amortized cost of its on-prem GPU usage with the consumption-based cost of its cloud-based inference calls, enabling true, all-in ROI calculations for AI projects.
Layer 3: Powering AI as a Service
The head of I&O’s mandate is to transform the AI platform from a black box into an efficient, audit-ready and financially transparent internal market for AI services. These services should empower AI developers to seamlessly spin up templated AI inference design patterns and agentic environments that align with enterprise policy guidelines. The core parts are detailed below.
XOps for Applied AI
Enable AI developer productivity surface, abstracting infrastructure complexity to deliver a standardized, self-service assembly line for accelerating AI from idea to production. The XOps strategy should be aligned to the AI infrastructure platform with layers that service the entire development life cycle (see Demystify the Ops Landscape to Scale AI Initiatives: A Gartner Trend Insight Report).
On-premises and hybrid options
- Self-service portals and tooling: Deploy as the AI factory’s unified front door, giving data scientists self-service access to compute and tooling to boost productivity and reduce I&O’s operational burden.
- Automated pipeline and workflow engines: Use as the assembly line for model development, automating the MLOps life cycle to enforce governance, ensure reproducibility and accelerate innovation.
- Distributed AI runtimes: Deploy as the core scaling engine to run a single training job across a massive accelerator grid, essential for efficiently training foundation models.
Cloud and hosted options
- Production model serving and management: Leverage Kubernetes-native tools to manage production deployment, enabling sophisticated traffic management like canary rollouts and A/B testing for safe, monitored rollouts at scale.
- Fully managed MLOps platforms: Adopt a hyperscaler’s end-to-end platform for the fastest time to market. This low-friction, integrated solution is ideal for teams focused on models over infrastructure, at the cost of deep platform commitment.
Focus on the “As-a-Service” Outcome
To improve consumption, heads of I&O must architect a federated control plane as a strategic clearinghouse, using a “single pane of glass” to guide teams through the trade-offs between on-prem, open-weight models and liability-protected, cloud-exclusive frontier models. This strategy is delivered via a catalog of on-demand services that safely abstract this complex choice:
- On-premises and hybrid cloud service offerings
- On-demand training environments: Use platform blueprints to offer self-service, on-prem training environments for open-weight models. This gives teams the freedom to fine-tune models on sensitive corporate data with maximum privacy and control.
- Internal RAG and inference services: Offer one-click templates that deploy open-weight models for internal RAG or inference. This is ideal for cost-effective, high-volume tasks where the data is private and the enterprise is willing to assume full liability for the model’s output.
- Cloud and hosted enablement
- Frontier model gateway: For external-facing applications, use the federated platform to provide secure, audited access to cloud-exclusive frontier models (such as from Google, OpenAI and Anthropic). This is the only path to leverage provider-backed liability protection and intellectual property (IP) indemnification, a critical requirement for managing enterprise risk.
- AI agent and reasoning workflows: Abstract the complexity of agentic workflows by creating templates that chain together multiple services. A single request from a developer could deploy a powerful, liability-protected reasoning model in the cloud for complex planning, while simultaneously calling a cost-effective, on-prem task model for data processing, all managed and orchestrated through the central platform.
Benefits and Uses
Deploying AI infrastructure requires a strategic alignment of workloads, environments and risk tolerance. There is no one-size-fits-all solution; the optimal architecture is a function of specific business, regulatory and technical requirements.
Environment Scenarios: Mapping Workloads to Deployment Models
Here is how each deployment model serves the AI factory:
- On-premises AI — The IP factory
- On-premises infrastructure is the secure IP factory, providing a deeply integrated environment to fine-tune open-weight models on sensitive data, creating a defensible advantage with maximum control and privacy.
- Public cloud — The frontier access point
- AI infrastructure in the public cloud is more of a volatile capacity market, not a utility. The primary promise of infinite elasticity is currently broken for high-end AI workloads. The cloud’s strategic benefit, therefore, is not elasticity but exclusive access — to liability-protected frontier models and a global, low-latency distribution network for deploying high-risk, external-facing agents.
- GPU-as-a-service — The innovation sandbox
- Specialized GPU clouds are the AI factory’s tactical innovation sandbox, providing extreme agility for high-risk experimentation. I&O’s role is to govern this shadow IT, allowing teams to test ideas, then migrating validated pilots back to the enterprise platform.
- Edge AI: The real-world action layer
- The edge is the AI factory’s action layer, closing the loop between digital insights and real-world outcomes. Deploying models on a centrally managed fleet enables real-time automation and personalized experiences by processing data at its point of origin, unlocking value otherwise lost to latency (see How to Choose the Right Edge AI Deployment Approach).
Risks
The head of I&O’s mandate for AI has inverted. The role is no longer managing technical assets, but governing a portfolio of strategic risks, from vendor alliances and energy markets to geopolitical restrictions, that manifest as infrastructure. The key risks are detailed below:
- Vendor lock-in — Design for failure
- Lock-in is now a multilayer dependency. Treat hardware ecosystems as risky strategic alliances and, more critically, treat external model APIs as an assumed point of failure. The mandate is to architect multiprovider gateways from day one, designing for their eventual degradation or discontinuation.
- Cost volatility — From budgeting to real-time trading
- Traditional financial planning is obsolete. I&O must now operate like a commodity trader for hardware and an energy trader for power allocation, as grid stability, not price, is the new primary constraint. FinOps becomes the real-time control plane to automatically throttle runaway jobs and prevent catastrophic cost overruns (see Control Cloud Costs With a FinOps Approach and Cost Optimization Strategies).
- Regulatory exposure — Engineer for fluidity
- Stop architecting for static compliance. The global regulatory landscape is fragmenting, so the mandate is to engineer a policy-driven data fabric that treats regulatory change, like new data residency laws, as a planned operational update, not a crisis that requires a platform rewrite (see The Cybersecurity Leader’s Playbook: Navigating the EU AI Act).
- Integration complexity — The velocity killer
- The “Franken-system,” a brittle architecture of stitched-together tools, is not technical debt; it’s a direct throttle on business velocity (see Supply Chain Executive Report: Closing the AI Expectations-Reality Gap). I&O must justify a platform-centric model by quantifying how this integration complexity degrades the latency of revenue-generating applications and delays product launches.
- Facility constraints — Density is the new metric
- Standard data center metrics are now dangerously misleading. The primary constraint is rack power density, which renders most existing floor space unusable. The critical path for any AI expansion is no longer construction but securing a multiyear power contract, making energy procurement the foundational first step in capacity planning.
- Operational talent gap — The root of pilot purgatory
- The inability to scale AI is not a data science gap, but an I&O operations gap. The mandate is to break internal silos and cultivate a new class of “tri-brid” expert, merging three previously separate domains into one role: data center facilities, high-performance computing and cloud-native DevOps (see Survey Shows How Generative AI Puts Organizational AI Maturity to the Test).
Recommendations
An I&O leader’s mandate is no longer tactical provisioning but strategic architecture. The following imperatives are designed to build a resilient, economically optimized and governable AI factory, moving I&O from a cost center to a center of strategic value for the enterprise:
- Mandate a universal Kubernetes control plane: The nonobvious goal is not just orchestration, but creating vendor leverage. By decoupling applications from specific hardware, you enable workload arbitrage across on-prem and multiple clouds, breaking the dependency on any single infrastructure provider.
- Implement a core-and-flex capacity model: This is about using operating expenditure (opex) to derisk capex. Establish a baseline of on-prem or dedicated cloud capacity for predictable workloads, then use the public cloud’s elasticity as a tactical, opex-funded buffer to absorb experimental demand without overprovisioning expensive capital assets.
- Fund pilot projects on nondominant hardware: True supply chain resilience requires creating operational alternatives before a crisis, not just technical ones. Mandate pilots on at least one alternative accelerator platform and open-weight model family to build institutional knowledge and derisk your dependence on a single market leader.
- Launch a centralized AI center of excellence (COE): The primary function of a COE is not just to set standards, but to actively hunt down and eliminate redundant shadow AI projects. It acts as an internal consultancy to enforce the reference architecture, preventing the creation of disparate, high-risk and costly silos.
- Embed FinOps and GreenOps into the development life cycle: This reframes cost and power consumption as primary architectural design constraints, not after-the-fact operational issues. Enforce fiscal and environmental accountability by making automated cost and energy impact assessments a mandatory gateway for every AI project.
- Mandate a procurement preference for open standards: This is how you derisk the future hardware stack. Requiring that new networking and interconnect hardware adhere to open specifications (like Ultra Ethernet and UALink) prevents a single vendor from controlling your architectural destiny, future TCO and ability to innovate.
Representative Providers
Alibaba, Amazon, AMD, Arista Networks, Microsoft Azure, Baidu, Cisco Systems, DDN, Dell, F5, Fujitsu Group, Google, Hammerspace, HPE, HPE (Juniper Networks), Huawei, IBM, Intel, Lenovo, NetApp, NVIDIA, Rafay Systems, Riverbed, Supermicro, Tencent, Together AI, TrueFoundary, VAST Data, WEKA.
Vendor briefings and client inquiries
Note 1: Sizing AI Workloads: Illustrative Guidance
Understanding the resource requirements of different AI workloads is crucial for effective capacity planning and cost management.
- Avoid foundational model training: This is a megawatt-scale, hyperscaler-level endeavor, not an enterprise IT project. The I&O mandate is to actively block these requests and redirect resources toward viable fine-tuning initiatives to prevent catastrophic, nonstarter capital expenditure.
- Mandate a “performance-per-watt” precision standard: The choice between 16-bit precision and an optimized 8-bit (FP8) or quantized format can reduce the TCO by a factor of more than four. I&O must mandate modern techniques like hardware-accelerated FP8 and quantization-aware training (QAT) to ensure the entire AI factory is economically viable at scale.
- Prioritize the data plane for RAG performance: For RAG, user-facing performance is dictated by the speed of the data retrieval fabric (the vector database and storage system), not the GPU. Investing in a low-latency data plane yields far greater performance gains than overprovisioning compute.
- Recognize agentic AI’s unpredictable bottlenecks: The performance of complex, multiagent systems is rarely limited by just the GPU. The true bottlenecks are often CPU for orchestration, system memory for context and network latency to external APIs, requiring a holistic approach to infrastructure design.