Innovation Insight: Database Management Systems for Enterprise AI Agents
1 December 2025 - ID G00840784 - 15 min read
By Xingyu Gu, Henry Cook, and 3 more
Suitable database management systems directly impact the efficiency, scalability, and reliability of AI agents. These DBMSs are far beyond a good vector database. Data management leaders should use this research to understand their DBMS capabilities to sustain the organization’s agentic AI journey.
Overview
Key Findings
- According to Gartner’s forecast analysis, spending on database management systems (DBMSs) with embedded generative AI capabilities is expected to triple by 2028. This growth reflects the increasing importance of modern DBMSs in dynamically capturing data for AI agent development and model training.
- DBMSs serve several essential roles in building enterprise AI agents, including providing support for agent memory, knowledge source, and tool provider for task execution, each of which places distinct functional requirements.
- Open-source, specialized DBMSs are popular for prototyping AI agents due to their flexibility and cost-efficiency, but they are not always a better choice than commercial solutions, especially when scaling AI agent initiatives into productized, mission-critical workloads.
Recommendations
- Understand AI-ready data requirements and DBMS demands for AI agents by collaborating with agent development teams and business stakeholders to align their use cases and value propositions.
- Ensure technology consistency and minimize technical debt by evaluating DBMSs based on how well their capabilities align with the specific requirements for agent memory, knowledge bases, and task execution.
- Before exploring new DBMS solutions, work with your current DBMS partners to determine whether they demonstrate a product innovation ecosystem roadmap of sustaining the enterprise agent engineering framework.
Strategic Planning Assumption
- By 2028, 80% of GenAI business applications will be developed on organizations’ existing data management platforms.
Introduction
Modern DBMSs play a crucial role in managing AI-ready data, impacting the accuracy, performance, security, and maintainability of enterprise AI agents. Yet, their importance is often overlooked by organizations’ AI leaders. Gartner forecasts that spending on database management software equipped with embedded generative AI capabilities will triple, rising from $65 billion in 2025 to $218 billion by 2028 (see Forecast Analysis: GenAI in Database Management Systems). This massive growth is driven by the following three key factors:
- Adoption of AI agents in enterprise environments is only beginning to gain momentum. According to Gartner’s survey of CIOs, 17% claimed that they have adopted agents, while 42% indicated that their organizations will adopt agents within the next year.1
- Organizations will opt to build AI solutions when their use cases evolve from simple to complex, necessitating deep customization and the integration of internal data with AI models (see How to Decide Whether to Build, Buy or Blend Your AI Projects). Build is preferred over buy when off-the-shelf products cannot meet requirements like unique customization, proprietary capabilities, or full control over intellectual property and future development. In this case, evaluating data management technologies, including DBMSs, becomes essential.
- AI models have become commoditized. The success of enterprise AI agents today depends on not only the models’ capabilities but also the organizations’ ability to interact effectively with their internal data. Over 75% of organizations state that AI-ready data remains one of their top five investment areas in the next two to three years.2 DBMSs are a core component for organizations seeking AI-ready data, as they enable unified management of multimodel data and diverse metadata from various sources in a centralized manner.
This note will focus on the kinds of roles DBMSs are playing in building enterprise AI agents and the principles for DBMS selection.
Description
Most DBMS vendors today claim their products are “AI-ready” or “agent-ready,” which creates confusion for product selection. As AI agents require complex workflows — including understanding user requests, connecting them to internal organizational data, integrating with AI models, and executing tasks — no single DBMS can meet every need at this time.
As Figure 1 below describes, DBMSs fulfill three key roles in the functioning of AI agents within enterprise environments.
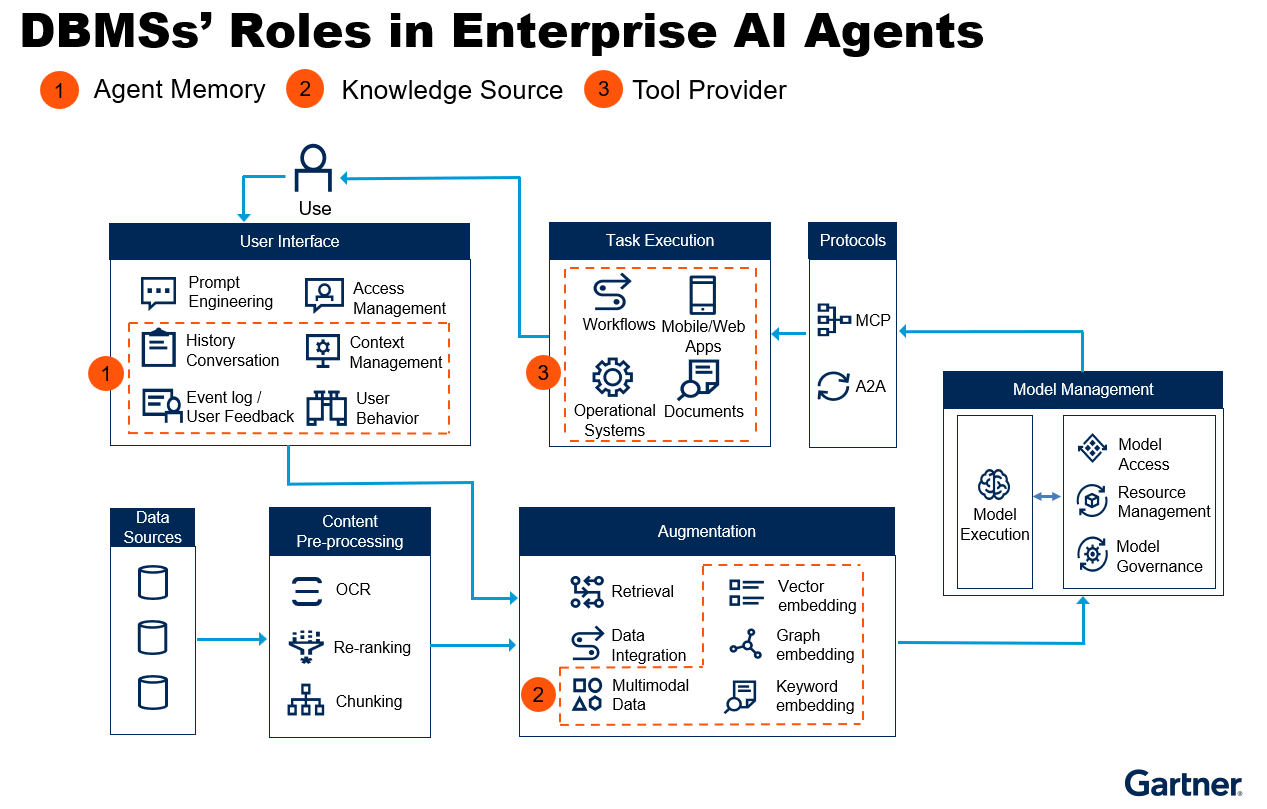
Agent Memory
Agent memory is a critical component that enables agents to store, recall, and utilize information derived from users’ current and past interactions and behaviors. It is a core component of context engineering. By maintaining context, learning from previous actions, and providing personalized or consistent responses over time, agent memory significantly enhances an agent’s ability to deliver adaptive and user-centric experiences. Moreover, agent memory is fundamental to the self-evolution of AI agents, allowing them to continuously improve and refine their performance.
Key elements of agent memory include the storage of user interaction history, the recording of user behavior and feedback for feedback loops, and the integration of identity and access management (IAM) data. These elements collectively support the agent’s ability to understand and respond effectively to users.
To support agent memory, a DBMS must provide several essential capabilities:
- Multimodel data management: Effective agent memory requires the ability to store and manage diverse types of data and metadata, such as interaction history (text), event logs, user feedback, and user behavior information.
- Indexing and search: The DBMS should offer highly accurate embeddings from users’ prompts through advanced hybrid embedding capabilities, ensuring contextually relevant semantic meaning is available for subsequent operations.
- Multitier storage: The DBMS must support multitier storage (i.e., cold, warm, or hot) to facilitate both real-time and historical data processing, thereby ensuring optimal user experience and meeting performance service-level agreements (SLAs) (see Table 1).
Sample Sample Relational and Nonrelational DBMS Products for Enterprise AI Agents
Category | Sample products |
Nonrelational DBMSs | Cosmos DB, MongoDB, Redis, DynamoDB |
Relational DBMSs | Aurora, PolarDB, EDB, Db2, AlloyDB, Spanner, OceanBase, PostgreSQL (OSS) |
Source: Gartner (December 2025)
Knowledge Source
A knowledge source refers to any data repository or system that contains information, which an AI model can reference to produce accurate, relevant, and contextually appropriate outputs. It functions as an internal reference resource for AI agents, enabling LLMs trained on public data to take action based on a company’s internal proprietary data. Examples of knowledge sources include vector databases or data lakehouses that store data preprocessed from SharePoints, intranets, wikis, and other structured or unstructured data sources.
Within enterprise AI agents, knowledge source is typically supported by two types of DBMSs:
- Specialized DBMSs for retrieval: Specialized vector or graph databases derive embedding data from various sources to enable context-aware retrieval, particularly within RAG architectures. By leveraging vector or graph representations, these systems facilitate more precise and relevant information retrieval for AI agents.
- Lakehouse with composable retrieval engines: Lakehouse provides centralized management of multimodel data and is increasingly adopting compute-storage decoupling as a standard capability. This allows users to integrate a variety of engines for data retrieval and search capabilities — including SQL query engines, vector-based retrieval, graph retrieval, and keyword retrieval — within the lakehouse. As Figure 2 below shows, such composability enables the development of hybrid retrieval mechanisms tailored to specific enterprise use cases, thereby enhancing the flexibility and effectiveness of AI-driven knowledge management (see Innovation Insight: Use RAG as a Service to Boost Your AI-Ready Data and Market Guide for Data Lakehouse Platforms).
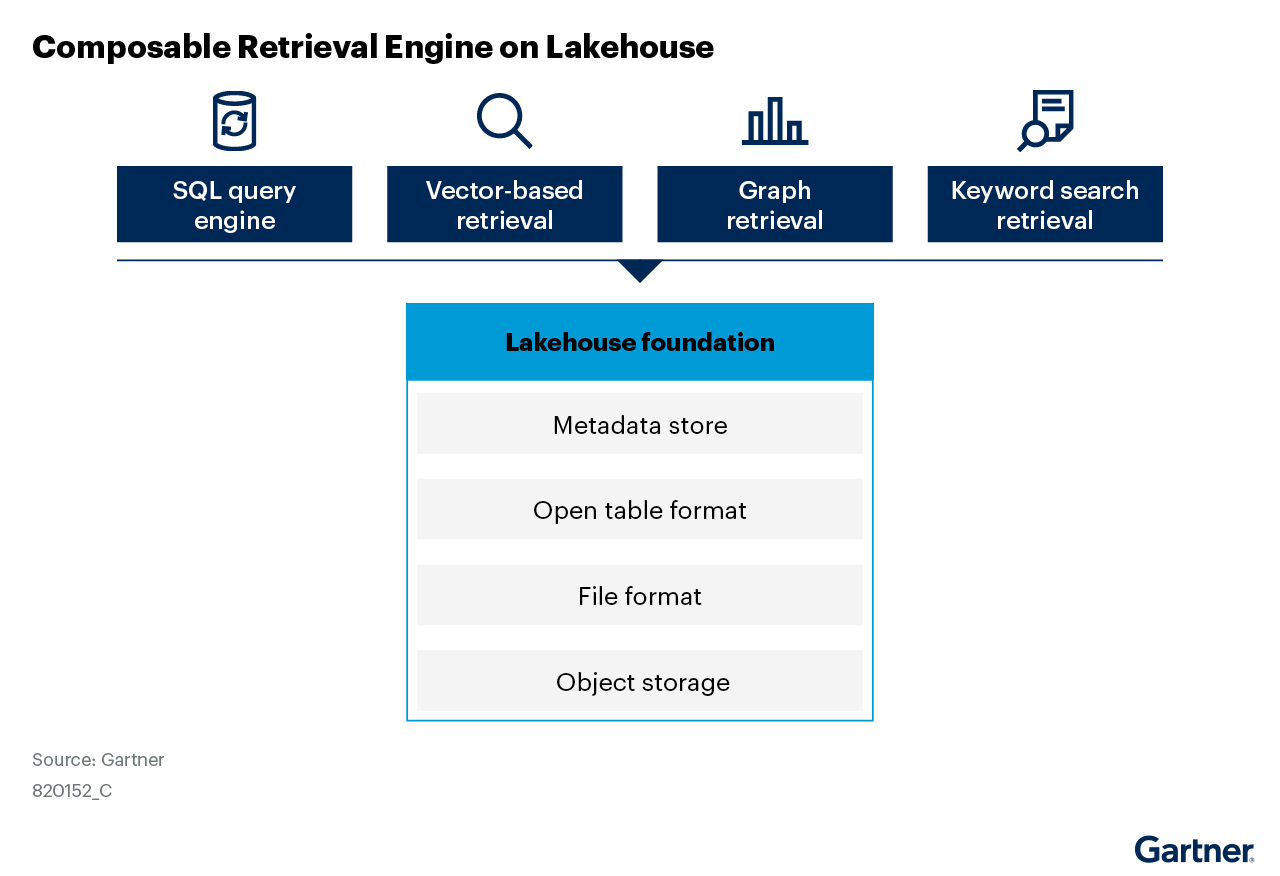
To support knowledge source, a DBMS should provide several essential capabilities:
- Support for embedding storage and retrieval: To efficiently store and retrieve vector, graph, and other embedding data types to enable context-aware information retrieval in AI architectures such as RAG.
- Multimodel data management: To manage diverse data formats — including structured, semistructured, and unstructured data — to serve as the central repository for knowledge needed to augment AI models.
- Compute-storage decoupling: To enable scalable and flexible data processing, which is essential for handling large and complex enterprise datasets.
- Integration with data governance and metadata management solutions: To enable effective management of data access, privacy, compliance related to the knowledge, and the handling of semantic standards, especially when including sensitive enterprise information (see Table 2).
Sample DBMS Products Supporting Knowledge Sources in Enterprise AI Agents
Category | Sample products |
Specialized DBMSs for embedding | Milvus, Pinecone, Neo4j, Elasticsearch |
Lakehouse platforms | Alibaba Cloud AnalyticDB, Amazon SageMaker Lakehouse, Cloudera Platform, Databricks Data Intelligence Platform, Google BigQuery, IBM watsonx.data, Microsoft Fabric, Snowflake, Teradata Vantage |
Source: Gartner (December 2025)
Tool Provider for Task Execution
A fundamental characteristic of an AI agent is its ability to make decisions, take actions, and accomplish objectives within its designated context, rather than merely supplying answers. These tasks directed by AI agents often involve an organization’s internal data, many of which are mission-critical and require stringent standards of consistency, security, and compliance. In this process, enterprise AI agents rely on their DBMSs to provide secure, reliable, authorized, and consistent data operation results.
To support tool provider, a DBMS should provide several essential capabilities:
- Broad API integrations: Utilizing either proprietary protocols or open standards such as MCP to securely and accurately connect with AI agents and interpret their task requests (see Innovation Insight: Model Context Protocol). Typical tasks include data operations (CRUD), performance tuning, and database administration activities.
- Admin and security: The ability to manage instances and resources, monitor operations, track and implement security, ensure high availability and disaster recovery, and perform these and other tasks at an enterprise SLA (see Table 3).
Sample DBMS Products Supporting Task Execution for Enterprise AI Agents
Sample products |
Oracle, Azure SQL, IBM Db2, MongoDB, PolarDB, Amazon Aurora, CockroachDB, EDB, PostgreSQL (OSS), OceanBase |
Source: Gartner (December 2025)
Benefits and Uses
Decision Points of Selection (1): Specialized vs. General-Purpose DBMSs
Specialized DBMSs, such as vector or graph databases, are best suited for enterprise AI agents that require advanced performance, unique data models, or complex queries — particularly for nonrelational data like vector embeddings or intricate graph relationships that general-purpose DBMSs cannot efficiently support.
Recently, multimodel DBMSs have been catching up rapidly on these nonrelational capabilities. A notable example is AI vector search: All DBMS vendors in the Magic Quadrant for Cloud Database Management Systems have incorporated vector search as a standard feature in their flagship products. More than half of them offer distributed vector search to support high performance in environments with large data volume and high concurrency. In Forecast Analysis: Database Management Systems, Worldwide, Gartner predicts that by 2029, RDBMSs will have 82% of non-RDBMS capabilities, up from 67% in 2025. Specialized functions that primary DBMS vendors have incorporated are listed in the table below (see Table 4).
Key Functions of General-Purpose DBMS for AI Agents
Function | Description | Implication for AI agent |
Multimodel DBMS | A multimodel DBMS incorporates several data engines — relational and/or nonrelational (e.g., document, graph, key value, time series, wide column, and vector) — in a single DBMS. | This allows AI agents to process various types of data — such as user prompts, documents, ERP data, system logs, and vectorized data — within a single database. By utilizing standardized object storage and open table formats, multimodel DBMSs can efficiently manage data and metadata from diverse data sources in a centralized manner. |
Composable query engine | A composable query engine integrates various types of query engines — including SQL, graph, vector, and keyword — within a single storage layer. | A lakehouse that can integrate with composable retrieval engines allows hybrid retrieval technologies — such as vector RAG, semantic search, and graphRAG — to be used at the same time. This enhances retrieval accuracy and improves the quality of results produced by AI agents. |
Multitier storage | Multitier storage integrates hard disk, memory, and cache to support both real-time data processing and historical data storage within a single DBMS. Proprietary algorithms are used to categorize ingested data as “hot,” “warm,” or “cold,” and allocate them to the appropriate storage tier. | This enables a DBMS to efficiently store large amounts of data while also supporting near real-time reaction during user interactions, ensuring an optimal user experience. |
Hybrid transaction/analytical processing (HTAP) | An HTAP architecture is enabled by both in-memory computing and the mix of columnar and row-oriented storage to enable search requests on the same data store for transaction processing. It removes the latency associated with moving data from transactional DBMSs to analytical ones. | Operational DBMSs are better suited for serving as agent memory and tool execution in AI agents, while analytical DBMSs are more appropriate for use as a knowledge source. HTAP DBMSs have the potential to combine all these functions into a single platform, reducing technological complexity when building AI agents. Recent vendor acquisitions highlight the potential of this capability.3 |
Source: Gartner (December 2025)
General-purpose DBMSs provide broad compatibility, operational efficiency, cost savings, and streamlined vendor management, helping to minimize future technical debt. Data and analytics leaders should work with agent builders and AI engineering teams to align the organizations’ current and future DBMS engagement strategy, and to prioritize general-purpose DBMSs for governance and simplified management unless specialized capabilities are required.
Evaluating DBMSs for AI agents is a cross-functional effort involving data management, AI engineering, and business units. Data management leaders should work with these groups to decide if they can consolidate their DBMS environment by retiring unused technologies, especially if their current DBMS already supports multiple data models.
Decision Points of Selection (2): OSS vs. Commercial DBMSs
Open-source DBMSs, particularly PostgreSQL, are becoming popular for building AI agents. Recent enhancements to PostgreSQL have expanded its capabilities in this domain, including:
- pgvector (external extension): Enables storage and querying of vector embeddings for similarity search.
- JSON/JSONB functions: Facilitate efficient storage, querying, and manipulation of semistructured data such as features, model outputs, and metadata.
- Fuzzy matching and semantic search: Improve the ability to retrieve relevant data based on approximate or semantic criteria.
- Key-value storage: Supports efficient storage of multimodel data.
- Row-level security and role management: Enhance data protection and access control.
While OSS DBMSs offer several advantages and reduce initial costs, certain limitations become more pronounced as organizations move from proof-of-concept (POC) to production and mission-critical workloads. These limitations include reduced enterprise functionality and limited service and support offerings necessary for meeting enterprise-level SLAs. Furthermore, maintaining and evolving a diverse set of OSS DBMSs and data management tools can require significant operational effort.
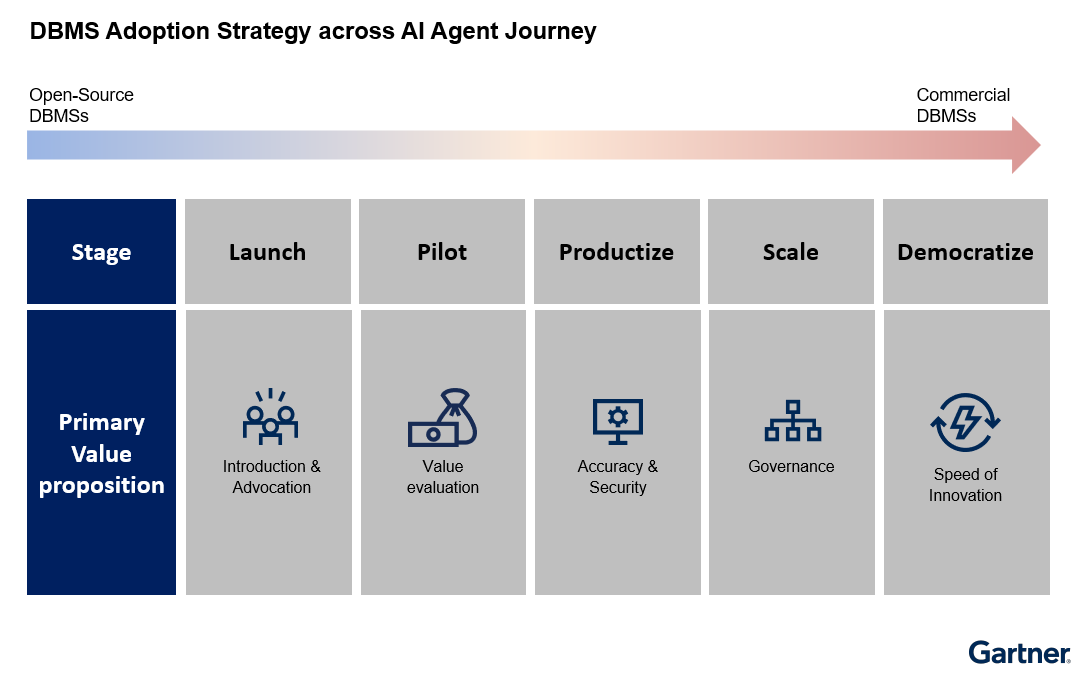
Commercial DBMS solutions provide additional enterprise features such as elasticity, distributed high availability, and security and compliance functions. Vendors also usually provide professional support and a more consistent upgrade path to reduce technical debts. They are generally more recommended when AI agents are productized and scaled in the organization (see Figure 3).
Data management leaders should carefully weigh the pros and cons of commercial versus OSS DBMS options, taking into account their organization’s current stage of AI adoption and the specific value proposition they seek to achieve.
Risks
- Siloed DBMS evaluation without collaboration with the AI engineering team and business units brings risks on technical debts and increased maintenance costs. The primary focus of data management teams in AI agent initiatives is providing AI-ready data, which usually happens when these initiatives are being scaled up to more complex and productized business use cases. In this situation, a lack of collaboration can result in duplication or conflicts with existing solutions in prototypes, leading to complex and costly data environments that are difficult to manage. Collaborative efforts help prevent these challenges and ensure efficient data management.
- DBMS evaluation independently without a broad data ecosystem mindset brings risks on technology silos and increased maintenance challenges. AI projects often involve managing different kinds of data and connecting various data integration, data quality, data security, and analytics tools. A comprehensive data management platform offers the flexibility and scalability to preprocess multimodel data, maintain data quality, and meet regulatory standards. As the data ecosystem evolves, the evaluation criteria for DBMSs should expand beyond purely technical considerations to the manner in which they integrate and collaborate with other data management, analytics, and AI vendors within the broader ecosystem (see Future of Data Management Markets: Converged Data Management Platforms Drive Tool Consolidation).
- Vendor lock-in reduces the organizations’ ability to adapt and negotiate. Using proprietary DBMSs means relying on their features, APIs, and surrounding data management tools, which can create vendor lock-in and limit flexibility in adapting to change solutions or negotiating costs. Data and analytics leaders should assess the openness and ecosystem engagement of target DBMSs, and plan for easy data transfer and flexibility from the start.
Recommendations
- Regularly review and consolidate DBMS environments: Continuously assess your database landscape to identify and retire underutilized or redundant technologies, consolidating systems where appropriate to reduce technical debt and maintenance costs.
- Foster cross-functional collaboration: Work closely with AI engineering, business units, and other stakeholders to ensure technology decisions align with organizational goals and use cases, minimizing duplication and inefficiency.
- Choose OSS or commercial DBMSs based on your needs: Select open-source DBMSs for flexibility and cost savings at the early stages of AI agent initiatives, but consider commercial solutions if your organization requires higher AI-ready data requirements, stronger support, security, and reliability for critical operations.
Representative Providers
Leading Vendors and Their Commercial DBMS Products for AI Agents
Vendors | Commercial products |
Amazon Web Services | Amazon Aurora, DynamoDB, SageMaker Lakehouse |
Alibaba Group | PolarDB, AnalyticDB |
Databricks | Data Intelligence Platform |
EDB | EDB Postgres AI |
Google | Google Spanner, AlloyDB, BigQuery |
IBM | Db2, watsonx.data |
Microsoft | Cosmos DB, Microsoft Fabric |
MongoDB | MongoDB Atlas |
Neo4j | Neo4j AuraDB |
OceanBase | OceanBase |
Oracle | Oracle Autonomous AI Database |
Redis | Redis Cloud |
Zilliz | Zilliz Cloud |
Source: Gartner (December 2025)
Leading Open-Source DBMS Products for AI Agents
Open-source products |
ArangoDB |
Elasticsearch |
Neo4j |
OpenSearch |
PostgreSQL |
Redis |
Source: Gartner (December 2025)
1 2026 Gartner CIO and Technology Executive Survey. This survey was conducted online from 1 May through 30 June 2025 to help CIOs and technology executives benchmark their priorities and investment plans against those of peers worldwide. Qualified respondents led a digital/technology function and were accountable for running or improving/growing a specific area of their enterprise. In total, 2,501 CIOs and technology executives participated, with representation from all geographies, revenue bands and industry sectors (public and private).
2 2024 Gartner Evolution of Data Management as a Dedicated Function Survey. This survey was conducted to establish the characteristics of a successful data management function and understand the future operating model, architecture and investment areas of data management teams. It also sought to identify what makes data management leaders successful in delivering data to business domains, meeting their SLAs and being able to defend their position by showcasing value. The research was conducted online from August through September 2024 among 248 respondents from across the world. Respondents were required to have involvement in, knowledge of and responsibility for implementing the data management side of the D&A strategy at their organizations. Disclaimer: The results of this survey do not represent global findings or the market as a whole, but reflect the sentiments of the respondents and companies surveyed.
3 Databricks and Neon Will Deliver Serverless Postgres for Developers and AI Agents, Databricks;
Crunchy Data Joins Snowflake, Crunchy Data.
Crunchy Data Joins Snowflake, Crunchy Data.