Critical Capabilities for Observability Platforms
8 July 2025 - ID G00822673 - 40 min read
By Matt Crossley, Gregg Siegfried, and 3 more
Observability platforms provide visibility into system health and performance to optimize business outcomes. As their capabilities evolve to address cost concerns and advances in AI, heads of I&O should use this research to evaluate which vendors best meet their needs.
Overview
Key Findings
- Observability platforms have expanded their scope beyond traditional application health and performance monitoring. By ingesting and analyzing data related to cost, user experience and business performance, these platforms deliver insights to a broader range of stakeholders beyond IT operations and site reliability engineering (SRE) teams.
- Observability platforms are increasingly leveraging AI, including generative AI (GenAI), to evolve from tools focused on telemetry interrogation to solutions that surface intelligent, human-readable insights. This shift enhances the accessibility of data-driven insights across technical and nontechnical stakeholders.
- The cost of observability platforms is under scrutiny. Organizations that have already invested in these solutions often experience substantial, sometimes uncontrolled, cost increases. For those entering the market, accurate cost forecasting and budget adherence are front of mind during the vendor evaluation process.
- Heads of infrastructure and operations (I&O) in both public and private sector organizations are tasked with adhering to policies relating to data sovereignty, security and regulatory governance. This has potential implications for critical, commercially sensitive or personally identifiable information collected by observability platforms.
- Capabilities powered by large language models (LLMs) are rapidly being integrated into applications that support both business-critical internal processes and customer-facing digital experiences via mobile apps and websites. This technological shift introduces new challenges, not only in terms of application performance and cost but also in managing the risks associated with LLMs, such as bias, model drift, toxicity and hallucinations.
Recommendations
- Maximize the return on observability investments by fully understanding and leveraging the platform’s extended capabilities. Align IT deliverables with strategic business objectives by using insights from observability platforms to support cost optimization, enhance business performance and improve customer experience.
- Drive productivity gains, minimize the business impact of performance issues and enhance customer experience by investing in observability platforms that go beyond observing systems. Prioritize solutions that deliver actionable insights, support intelligent decision making and enable automated responses to operational challenges.
- Maintain observability cost control and ensure predictability by assessing observability platforms for their licensing models, telemetry management capabilities, product usage visibility, access controls and cost allocation insights.
- Fulfill regional regulatory requirements on data management by evaluating observability platform vendors based on their ability to host the platform or its data plane within an appropriate geographic region or location. Additionally, assess capabilities for data obfuscation and other features that support adherence to local data protection legislation.
- Enable strategic enterprisewide adoption of LLM and generative AI technologies by evaluating observability platforms on their ability to deliver insights into LLM performance, cost and token usage and potentially harmful outcomes.
What You Need to Know
This document was revised on 10 July 2025. The document you are viewing is the corrected version. For more information, see the Corrections page on gartner.com.
As businesses become increasingly digitalized, mobile and web applications have become the primary, if not the only, touchpoints between customers and enterprises. These applications are now critical drivers of business outcomes, influencing everything from revenue generation to customer satisfaction and engagement. Ensuring the resilient and reliable operation of these already complex and distributed applications has become even more challenging thanks to the addition of generative AI-based features. These features need monitoring not only for performance but also to avoid the inherent risks associated with LLMs.
For heads of infrastructure and operations, observability platforms are essential tools that provide deep visibility into the behavior of complex, distributed IT systems. Their core function is to help I&O teams proactively monitor, analyze and optimize application health and performance. Modern observability platforms correlate technical telemetry with business objectives and leverage AI to enable teams to detect anomalies, reduce downtime and make data-driven decisions that directly impact business outcomes and operational efficiency.
This research focuses on the competitiveness of observability platform products with respect to key functional dimensions rather than the overall strengths and weaknesses of the vendors themselves. This analysis complements Magic Quadrant for Observability Platforms, which defines the market and highlights a broad set of factors, including corporate viability, vision, marketing and the geographic focus of the vendors offering these products. We recommend that organizations use this research in conjunction with the Magic Quadrant, inquiries with Gartner analysts and other Gartner research to define their requirements and select the observability platform that best matches their needs.
Analysis
Critical Capabilities Use-Case Graphics
Vendors
Amazon Web Services
The Amazon Web Services (AWS) observability products evaluated in this research comprise Amazon CloudWatch as well as other AWS components including AWS X-Ray, Amazon OpenSearch Service for log analysis and Amazon Managed Service for Prometheus and Grafana. Collectively, these services support end-to-end observability and cloud operations. Amazon CloudWatch Investigations was launched in June and has integrations with Amazon CloudWatch. It will provide the ability to rapidly diagnose, troubleshoot and remediate operational issues.
In this evaluation, AWS was above average for nearly all critical capabilities. In particular, AWS demonstrated high levels of capability for LLM observability, which showed strong integration with core AWS services such as Bedrock and SageMaker. Additionally, AWS console provides a number of tools and techniques like AWS Budgets and Cost Explorer for managing observability costs.
AWS’ solution is well-suited for those who are experimenting with or implementing AI engineering for deploying generative AI, as well as for the software engineering and platform operations use cases. It is also well-suited to organizations with an AWS-centric cloud strategy.
Apica
The Apica Ascent observability platform comprises Fleet (collector/agent management), Flow (telemetry pipeline), Lake (telemetry-optimized storage) and Observe (visualization, analysis and alerting). Ascent can be consumed via SaaS, as evaluated in this research, or on a self-hosted basis.
Ascent’s fleet management capabilities are vendor-neutral, based on the open source Open Agent Management Protocol (OpAMP). Fleet is able to manage the installation and configuration of a variety of open-source agents, including the OpenTelemetry (OTel) Collector, Fluent Bit, Grafana Alloy and the Datadog agent. This contributed to some of its highest ratings in the ingest, optimize, store telemetry and observability cost control capabilities. Apica’s highest-rated critical capability was LLM observability, thanks to its out-of-the-box dashboards, which included the ability to monitor LLM token usage, cost, AI performance and guardrail measures.
This led to Apica’s highest scores in the AI engineering, platform operations and cost optimization use cases. Apica Ascent is evolving rapidly and is best suited for heterogeneous organizations that need to manage a variety of agents and those that require the telemetry normalization offered by the native telemetry pipeline.
BMC Helix
The BMC Helix Observability & AIOps suite’s capabilities include observability, asset discovery and service operations. This replaces the previous bundle of products called BMC Helix Operations Management. It can operate either as a full IT operations management (ITOM) solution alongside BMC Helix ITSM or integrated into the customer’s own tools portfolio.
BMC Helix’s platform rated below average across most critical capabilities. However, a notable highlight was in interoperability, where it gained its highest rating. The platform is very well integrated into BMC’s Helix ITSM, a compelling feature for those using both products. Beyond that, BMC Helix recognizes that its observability suite will likely exist in an ecosystem. It also supports ingestion of data from other vendors’ products including infrastructure and network monitoring and integrated development environment (IDE) tools.
BMC Helix views its observability platform as an “automation broker,” encouraging integrations that support automation. Examples include integration with continuous integration/continuous delivery (CI/CD) pipeline solutions to automate response in DevOps workflows, integration with collaboration tools and integration with automation and orchestration platforms supporting infrastructure as code. This flexibility contributed to an above average rating in the automated response capability.
BMC Helix is best suited to the platform operations use case, particularly when integrated into the BMC Helix ITSM platform.
Chronosphere
Chronosphere’s solution comprises the Chronosphere Observability Platform and the Chronosphere Telemetry Pipeline. It supports open-source standards such as Prometheus and OpenTelemetry and includes telemetry data governance capabilities. It also includes increasingly advanced capabilities such as differential diagnosis (DDx), which supports guided troubleshooting and cause analysis and service-level objective (SLO) management.
Chronosphere has included ingestion-time control of telemetry since its early, time-series-only days and has broadened this control to support traces and logs as well. The company has taken a partnership approach to expanding its capabilities, establishing relationships with others for capabilities such as digital experience monitoring, continuous profiling and OTel autoinstrumentation. This strategy allows Chronosphere to focus its energy on core observability platform capabilities and augment its platform with the features that are most important to its customer base. Capabilities delivered via partnership are brought in house when they become core to the platform, such as with the recently announced Logs 2.0 product.
Chronosphere’s offering rated above the mean for all critical capabilities. Its highest use-case scores were for cost optimization, site reliability engineering and platform operations.
Coralogix
The Coralogix observability and security platform includes application, digital experience and log monitoring as well as security capabilities such as security information and event management (SIEM) and security posture management (SPM). The product is built on a streaming data lake architecture that supports tiered telemetry storage and allows customers to use their own object storage as the archive tier.
A notable feature of Coralogix is its flow alerts, which allow customers to define a sequence of events and a time horizon and be alerted when this sequence takes place. The Coralogix TCO Optimizer is a policy engine that allows customers to define storage and retention parameters for traces and logs. This contributed to its strong observability cost control rating.
The Coralogix ratings were above average for most critical capabilities and its highest scores were in observability cost control and LLM observability.
As a result, Coralogix is well-suited for the AI engineering and cost optimization use cases.
Datadog
Datadog’s observability platform offers a unified solution that integrates infrastructure monitoring, application performance monitoring, log management, and digital experience monitoring. It consistently rates among the top products across all critical capabilities.
It rated highly for LLM Observability due to enhancements in deep analytics of large language model workloads. This includes trace-level granularity and features like hallucination detection and cost-based alerting. Its Watchdog AI helps identify root causes of performance issues, while Bits AI, Datadog’s generative AI-based assistant, provides guided workflows and delivers recommendations, resulting in a high rating in the generate actionable insights capability.
Datadog rated highest of all products in interoperability thanks to mature integrations such as telemetry ingestion from Simple Network Management Protocol (SNMP) and NetFlow, connections with other monitoring platforms, bidirectional ITSM integrations, collaboration tools like Slack and support for IDE environments for code debugging.
Datadog is suitable for all observability use cases, most notably site reliability engineering, platform operations and software engineering.
Dynatrace
Dynatrace’s observability platform comprises multiple components, including Infrastructure and Application Observability, Application Security and Threat Observability, Automations, Digital Experience and Business Observability. Built around the Grail data lakehouse, Dynatrace leverages its Davis AI engine to deliver insights to multiple personas across a variety of verticals.
Dynatrace rated among the top products across all critical capabilities. Particularly impressive is Dynatrace’s generative AI capability, Davis CoPilot. It is extremely well-integrated into the product, assisting the user with AI-augmented decision making and guided workflows. It is especially well-suited to users new to the platform or with less technical expertise. This contributed to Dynatrace receiving the highest rating for the generate actionable insights capability.
It also achieved the highest rating across all products for the user experience and business analysis capability with its wizard-based SLO creation, ability to monitor business workflows and use of Davis AI to troubleshoot end-user performance issues.
Dynatrace is well-suited to all observability platform use cases, particularly those focused on business insights, site reliability engineering and cost optimization.
Elastic
Elastic’s Observability platform is based on the Elastic Search AI Platform and sits in a portfolio alongside the vendor’s search and security offerings. Elastic Observability can be delivered via SaaS, self-hosted or hosted on Elastic Cloud, which is available on all the major cloud service providers.
Elastic has continued to evolve in its ability to provide insights into the health and performance of applications and user experience using various forms of telemetry to include business insights. It has become stronger in ingestion capabilities, broadening the onboarding of various data types and improving interoperability support. The integration of AI across the tool as a whole helps with getting to the root cause of issues and simplifying the user experience.
Elastic Observability’s rating was above the mean for all critical capabilities. Its highest use-case scores were in business insights, software engineering and software reliability engineering. Elastic’s solution received its highest use-case scores for business insights.
Grafana Labs
Grafana Labs’ observability platform comprises Grafana Cloud, which includes ingestion, storage, analysis and visualization of metrics, logs, traces and profiles, as well as capabilities such as digital experience monitoring and automated incident response. The company also manages open-source upstream distributions of many of its products, such as Loki, Grafana, Tempo and Mimir, sometimes known as the LGTM stack. In 2024, Grafana Cloud’s Adaptive Metrics cost control mechanism was joined by its Adaptive Logs offering.
Grafana Cloud rated above the mean for all critical capabilities. Its highest rating was for observability cost control. Grafana’s adaptive telemetry innovations, as well as administrative controls such as billing visualizations and forecasting, as well as their fleet management capabilities contributed to this rating.
The Grafana Labs observability platform is well-suited for most of the use cases that were evaluated here, with particularly strong performance in platform operations and software engineering.
Honeycomb
Honeycomb’s observability platform is built around analyzing high-cardinality telemetry and embracing open standards. The product is typically targeted toward engineering teams seeking real-time insights through exploratory observability.
One of Honeycomb’s strengths is its BubbleUp anomaly detection feature. It provides users with rapid visual insight into telemetry of interest, aiding, for example, root cause analysis. The ease with which an engineer can navigate the UI to interrogate data contributes to its high rating in the exploration of telemetry capability. Its flexibility in ingest, optimize, store telemetry for multiple use cases resulted in its highest rating in that capability. Its ability to analyze LLM cost, performance, sentiment and coherence in the context of application observability resulted in a high rating for LLM observability also.
Honeycomb is first and foremost a tool for analyzing telemetry, and as such features designed to take automated action based on surfaced insights have not been prioritized, resulting in it achieving its lowest rating for the automated response capability.
This combination of capability ratings makes Honeycomb best suited for the site reliability engineering, AI engineering and business insights use cases.
IBM
The IBM Instana Observability platform is available as SaaS or as a self-hosted solution, and it supports application performance and infrastructure monitoring. IBM Instana monitors a broad selection of applications, including containerized environments and microservices as well as supporting IBM Mainframe z/OS.
IBM Instana rated at or above average for more than half of the eight critical capabilities, including user experience and business analysis, and automated response, which received the highest ratings.
A key strength for the user experience and business analysis critical capability was Instana’s SLO management and its ability to retrospectively evaluate performance and potential SLO breaches.
However, troubleshooting along the user journey could be more robust. Alert channel capabilities and the tool’s ability to bind automation actions to alert policies were an important part of its automated response rating.
IBM Instana is best suited for the business insights and cost optimization use cases.
ITRS
ITRS’s observability platform, ITRS Analytics, is built on Geneos (application performance monitoring), Opsview (infrastructure monitoring) and Uptrends (digital experience monitoring) and is delivered as either a SaaS or self-managed solution. Although targeted across verticals, ITRS’s specialty is the high-volume transaction systems of financial services.
ITRS’s observability platform is rated below average in all critical capabilities. Its strongest rating was in ingest, optimize, store telemetry, being able to go beyond standard telemetry ingestion to include sustainability metrics, business metrics and financial transaction data. ITRS is in the process of consolidating its portfolio into a common, data-lake-based architecture that is more akin to other participants in this research. This may have potentially delayed its incorporation of stronger AI-based features, leading to a low rating for the generate actionable insights capability. ITRS is also notable for its lack of capabilities to support LLM observability.
ITRS has a targeted specialty and therefore is strongest in use cases within financial services.
LogicMonitor
LogicMonitor’s collector-based LM Envision platform delivers hybrid observability. It ingests metrics, logs, traces and events across cloud, on-premises, SaaS and containerized environments. It also features GenAI-powered root cause analysis, alert clustering and AI infrastructure observability, including Nvidia GPU and OpenAI monitoring.
Built on a robust foundation of infrastructure and network monitoring, LogicMonitor’s observability platform has expanded to include monitoring of cloud-hosted workloads and business-centric observability. LogicMonitor’s ratings were below average in all critical capabilities. Its highest rating was for ingest, optimize, store telemetry. In addition to ingesting standard infrastructure telemetry, LogicMonitor can display and forecast metrics on power consumption, green energy and cloud spend.
LogicMonitor is best suited for site reliability engineering, platform operations and software engineering use cases.
Microsoft
Microsoft’s observability platform product is Microsoft Azure Monitor. It is part of the larger set of cloud-based products under Microsoft Azure and is offered only as SaaS.
Azure Monitor is optimized for monitoring Microsoft Azure workloads and is also well-integrated into other Azure-native products, such as Azure Network Watcher and Azure Managed Grafana as well as Sentinel and Defender for security. Microsoft recently enhanced Application Insights with AI/machine learning (ML)-based code optimizations.
Azure Monitor scored at or above average for seven of eight critical capabilities. Its strongest capabilities were for exploration of telemetry and observability cost control. The former is supported by an intuitive ability to correlate logs, metrics and traces for root cause analysis, and deep integration with Azure DevOps (ADO) to evaluate the impact of defective releases. Azure Monitor’s cost control features benefit from the mature cost management framework available in Azure.
Its strongest use cases were in AI engineering and cost optimization.
New Relic
New Relic’s intelligent observability platform covers application performance monitoring (APM), AI monitoring, digital experience monitoring (DEM), infrastructure and security monitoring, and log management. It received high ratings across nearly all critical capabilities.
A standout strength is its usage overview functionality, which allows users to analyze data ingestion and compute usage over time, then drill down into specific use cases. Combined with features like telemetry retention controls, live log archiving and pipeline and fleet management, this earned New Relic its highest rating in the observability cost control critical capability.
Its LLM observability capability is also noteworthy, offering intuitive workflows for diagnosing performance issues in LLM requests and enabling comparisons across models based on cost and token usage.
Overall, New Relic is well-suited for most use cases, with particular strengths in site reliability engineering and AI engineering.
Oracle
Oracle Cloud’s Observability and Management (O&M) platform is offered as part of Oracle Cloud Infrastructure (OCI). It supports on-premises, hybrid and multicloud infrastructure, application, log, database and SQL monitoring.
As a hyperscaler cloud provider, Oracle has mature features for measuring cost; this extends to observability cost, making it easy to see usage and forecast cost across different services. This contributed to one of its highest ratings in the observability cost control capability.
O&M rated less favorably in the generate actionable insights capability due to its relatively late implementation of a generative AI-based assistant; this is something it plans to rectify when it releases an observability assistant in late 2025. Automated response was among Oracle’s lowest-rated capabilities due to limited features that support automating incident response and remediation actions. Oracle has plans to bolster this capability in its short-term incident management roadmap.
While this evaluation concludes that Oracle O&M does not excel in any of the six defined use cases, it is well-suited for I&O teams heavily invested in Oracle OCI, Oracle Fusion or E-Business Suite applications or Oracle Database, and seeking an observability platform which caters to multicloud and hybrid workloads.
ScienceLogic
ScienceLogic’s platform comprises four products: SL1 for observability, PowerFlow for agentic automation, RestorePoint for security and network compliance and Skylar AI for unsupervised learning and reasoning. Of note is the Skylar AI integration, which enhances probable cause analysis, event intelligence and enables intelligent automated operations. SL1 provides robust integration with ServiceNow, enabling automated configuration item (CI) updates in the CMDB and efficient incident workflow management while its PowerFlow framework provides guided connectivity to external systems.
The critical capabilities scores show that ScienceLogic’s overall rating was marginally below average, and it scored slightly above average for LLM observability, indicating a generally solid performance in all areas.
Its balanced score makes ScienceLogic well-suited to all use cases for enterprises needing comprehensive monitoring across complex multivendor environments, although it may fall short in advanced interactive analytics compared to some of its more mature competitors.
SolarWinds
SolarWinds offers a broad portfolio of monitoring and observability tools increasingly consolidated under its SolarWinds Observability Platform. Its traditional strengths in infrastructure and network monitoring are augmented with APM, log management, database monitoring and DEM capabilities, targeting hybrid IT and cloud-native environments.
SolarWinds’ platform rated below average across all critical capabilities with a notable gap in features catering to LLM observability.
Despite lower ratings across the evaluated use cases, SolarWinds remains a viable option for organizations prioritizing infrastructure and database monitoring. Furthermore, SolarWinds is well-suited to those requiring a flexible self-managed and SaaS deployment model, or when implemented as part of the broader SolarWinds suite, including for example, ITSM and network configuration management.
Splunk
In 2024, Cisco finalized its acquisition of Splunk, marking a strategic shift from the Cisco Observability Platform to Splunk Observability. Following the acquisition, Cisco initiated a roadmap aimed at unifying key products, including Splunk Observability Cloud, AppDynamics, IT Service Intelligence (ITSI) and ThousandEyes (not part of the Splunk portfolio), into a cohesive integrated solution.
However, this evaluation highlighted that full integration is still a work in progress. The need to navigate between separate tools detracted from the overall user experience and impacted Splunk’s ratings in the critical capabilities. In addition, the limited features for monitoring large language model workloads and observability costs were particularly notable. This led to its lowest ratings being in the LLM observability and observability cost control capabilities.
Splunk earned its highest rating in the user experience and business analysis capability, thanks to features such as a mature service-level objective implementation and customer journey mapping. These strengths make Splunk a good candidate for the business insights use case.
Splunk’s broader portfolio, which spans SIEM, log analytics and network monitoring, adds to its appeal for enterprises seeking a comprehensive single-vendor solution that extends beyond observability.
Sumo Logic
Sumo Logic’s observability strategy is built around its distinctive strength in large-scale log analytics. However, in this evaluation the platform underperformed, receiving below-average ratings across all critical capabilities. Most notably, it lacked dedicated features for LLM observability, resulting in its lowest rating for that capability.
A key strength lies in its support for open standard interfaces and tools such as OpenTelemetry, Telegraf and Fluent Bit, which positively influenced its score in the ingest, optimize, store telemetry capability.
Sumo Logic’s potential in generating actionable insight critical capability is beginning to emerge thanks to the recent introduction of its Mo Copilot feature. While mostly limited to a query assistant, the company has made AI-driven investigation and expanded generative AI capabilities a central focus of its product roadmap.
Despite these developments, Sumo Logic did not demonstrate a strong alignment with any specific observability use case based on the critical capabilities ratings. That said, it remains a compelling option for I&O teams prioritizing scalable log analytics, particularly those looking to unify observability and security, given its integrated SIEM and security offerings.
Context
Observability platforms have undergone a significant evolution from their origins in application performance monitoring. Initially designed to address the dual challenges of increasingly complex distributed application architectures and the business demand for accelerated development cycles, they have continued to evolve in response to these persistent pressures.
Modern observability solutions empower I&O teams to maintain system reliability and performance amid a growing influx of telemetry data across increasingly complex hybrid cloud environments. This has been possible due to incremental advances in AI and machine learning. For heads of I&O, observability extends beyond IT resilience serving as a bridge to the business and demonstrating how performant IT systems directly influence business outcomes and customer experience.
What was a gradual evolution of AI and machine learning became both an opportunity and a threat with the more rapid proliferation of first generative, and now agentic, AI. LLM-powered capabilities embedded within observability platforms promise substantial productivity gains and potentially an even more disruptive impact on SRE teams and I&O at large. The use of LLMs in customer-facing applications represents a new challenge for I&O — in addition to delivering reliability and performance, end users must be shielded from bias, toxicity and hallucinations.
Naturally, these capabilities come at a cost. Observability platforms often operate under subscription-based licensing models tied to the ingestion of seemingly endless telemetry, resulting in a cost which, if left unchecked, can increase at a rate greater than that of the systems being observed. Since the last iteration of this research, cost control has emerged as a critical capability. Existing and prospective customers now prioritize platforms that offer transparency, governance and predictability in observability-related spending.
Market Definition
Gartner defines observability platforms as products used to understand the health, performance and behavior of applications, services and infrastructure. They do this by ingesting telemetry (operational data) from a variety of sources including, but not limited to, logs, metrics, events and traces. Observability platforms enable analysis of the ingested telemetry, either via human operator or machine intelligence, to determine changes in system behavior that impact end-user experience, such as outages or performance degradation. This allows early, and even preemptive, problem remediation. Observability platforms are used by IT operations, site reliability engineers, cloud and platform teams, application developers and product owners.
Modern businesses rely heavily on critical digital applications and services, which are revenue-generating, client-facing and important to the efficient operation of the business. Outages, performance degradation and unreliability directly impact top-line revenue, client sentiment and brand perception.
Observability platforms are used by organizations to understand and improve the availability, performance and resilience of these critical applications and services. Investment in and successful deployment of observability platforms leads to revenue loss avoidance and enables faster product development cycles and improvements in brand perception.
Example use-case scenarios or business problems addressed by observability platforms include:
- IT operations: IT operations teams responsible for live production environments are tasked with ensuring that applications and services are available, responsive and performant at all times — and especially during periods of high demand. Observability platforms allow these teams to be alerted when issues are detected, and make it possible to interrogate the data to identify the underlying cause.
- Platform engineering: Platform engineers’ use of observability platforms resembles that of IT operations as well as software development. Observability platforms help these teams ensure that production environments consistently meet service-level objectives, in addition to supporting data-driven continuous improvement and platform evolution.
- Software development: Development teams use observability platforms as an integrated part of the CI/CD pipeline, providing rapid feedback on code deployments. This enables faster delivery of new features, as well as improved product resilience.
- Business analyst: Business analysts may use observability platforms to understand and analyze key business metrics. These metrics are often specific to the organization and client (for example., a retailer measuring the cost of abandoned shopping carts and average customer spend).
Mandatory Features
At a minimum, observability platforms must:
- Ingest, store and analyze operational telemetry feeds, including (but not limited to) metrics, event, log and trace data.
- Identify and analyze changes in application, service and infrastructure behavior to determine the causes of outages, performance degradation and quantify their impact on end-user experience.
- Enrich telemetry by providing contextualization, such as topological dependency or service mapping.
- Support the modeling or mapping of relationships between monitored services and their role in business transactions.
- Collect telemetry from public cloud providers (for example, Amazon Web Services, Microsoft Azure and Oracle Cloud Infrastructure).
- Support interactive exploration and analysis of multiple telemetry types (including traces, metrics and logs) to generate insights about user and application behavior.
Common Features
The common features for this market include:
- Monitoring of digital experience of applications and services delivered via browser, mobile app and API.
- Integration with other operations, service management and software development technologies, such as IT service management (ITSM), configuration management database (CMDB), event and incident response management, orchestration and automation, and DevOps tools.
- Providing insights through the use of advanced analytics and machine learning that are otherwise not possible or feasible to derive through manual interrogation and analysis of data.
- Automated discovery and mapping of related infrastructure, network and application components and services.
- Cost management that supports measuring and optimizing application workload cost, as well as measuring and optimizing observability platform utilization or spend.
- Business process and activity monitoring reflecting user journeys such as login to check-out, funnel analysis to track conversion rates, customer onboarding or loan application.
- AI observability capabilities including the ability to analyze the performance, cost, capacity and compliance of large language models and associated generative AI workloads.
- Automation capabilities that support initiating changes to application and infrastructure code and configuration to optimize workload cost, capacity or performance, or to take corrective action to remediate failure or degradation.
- Application security functionality, such as the identification of known vulnerabilities in monitored applications and the ability to block attempts to exploit them.
Product/Service Trends
Observability platforms are products that ingest telemetry (operational data) from a variety of sources, including but not limited to, logs, metrics, events and traces. They are principally used to understand the health, performance and behavior of applications, services and infrastructure. Observability platforms enable their users to solve difficult issues in diverse and complex application architectures whether on-premises, in the cloud or hybrid.
As a minimum, observability platforms supplement telemetry data with two important contexts. Firstly, a service or topology map which identifies the various components of the application or systems, how they are related and their dependencies. The second is a business service or end-user context; rather than focusing solely on the performance of IT, observability platforms do so with an understanding of the impact on a specific business service and/or the experience of the user accessing the service.
Beyond the primary use case of understanding the behavior of complex systems, observability platforms have evolved to collect additional types of data to assist adjacent functions such as security, FinOps and business performance. As such, observability platforms are increasingly seen as data lakes and analytics platforms for operational intelligence. This has expanded the typical user groups for these platforms beyond SRE and DevOps teams.
More recently, with advancements in large language models, observability platforms are able to more readily surface actionable insights and make intelligent decisions, guiding users on their operational response or next-step action. Such advances are anticipated to have a substantial impact on traditional SRE and I&O operations teams.
Gartner has established eight critical capabilities in the context of six use cases that differentiate the most popular tools in this market:
- Ingest, optimize, store telemetry
- Interoperability
- Exploration of telemetry
- Generate actionable insights
- User experience and business analysis
- Observability cost control
- Automated response
- LLM observability
The six use cases are:
- Site reliability engineering
- Platform operations
- Software engineering
- Business insights
- Cost optimization
- AI engineering
Critical Capabilities Definition
Ingest, Optimize, Store Telemetry
Ingest, optimize, store telemetry refers to an observability platform’s ability to ingest multiple sources of telemetry, including but not limited to metrics, events, logs and traces.
In addition to using proprietary agents and collectors, engineers are progressively adopting standardized and automated telemetry collection methods such as OpenTelemetry. Furthermore, features like monitoring as code and the ability to manage high cardinality telemetry throughout its life cycle are essential to stay in control of telemetry complexity, volume and cost. As observability use cases continue to evolve, platforms need to be capable of ingesting data for use cases that go beyond traditional health and performance monitoring.
Interoperability
Interoperability refers to the extent to which the platform supports integrations with other systems and tools involved in the development, deployment and operations of IT systems.
Observability platforms do not exist in a vacuum. They must be capable of operating as part of an integrated portfolio of tools covering multiple disciplines, including software development, CI/CD pipelines, IT service management, communication and collaboration, automation and orchestration, and security incident and event management. A well-integrated observability platform removes toil and facilitates process optimization and acceleration.
Exploration of Telemetry
Exploration of telemetry provides a skilled platform user with ad hoc access to raw telemetry in a manner that supports iterative, hypothesis-driven and exploratory analysis and facilitates the discovery and classification of user and workload behavior.
A central tenet of observability is that a system’s behavior be understood by the data it emits. Observability platforms should provide the capability to explore this data contextualized with service mapping, business service and end-user experience. Such exploration provides insights related to, for example, probable cause analysis, user experience and business service impact.
Observability Cost Control
Observability cost control capabilities are designed to facilitate the understanding, management and optimization of the cost of observability.
The increasing complexity, velocity and volume of telemetry ingested, analyzed and stored by observability platforms create a challenge for controlling, forecasting and optimizing observability spend. Telemetry lifecycle management, cost optimization, cost allocation, telemetry usage analytics and access controls all provide important mechanisms for teams to ensure they optimize the cost of observability today and remain in control as use cases grow.
LLM Observability
LLM observability is the ability to monitor, understand and analyze the behavior and performance of large language models and their workloads in real time or during their development.
As business-critical application workloads become reliant on LLMs for both customer-facing services and internal processes, so does the need to monitor their performance. LLM observability complements application and infrastructure observability with insights specific to LLMs. These include usage, performance, cost, token utilization, latency, drift, toxicity and hallucination. This provides IT operations teams, SREs and AI engineering teams with a better understanding and control of their behavior, performance and outputs.
Generate Actionable Insights
Advanced analytics, AI and machine learning are able to deliver guided analysis, surface issues and provide actionable insights about workload behavior that may be predictive or causal.
While observability is founded on the ability to interrogate data to understand system behavior, the increasing complexity of distributed systems and volume of telemetry collected mean that this is no longer possible through manual endeavor alone. Utilizing advanced analytics capabilities, including AI and ML, is an essential component of observability. This results in generated insights, surfacing of “unknown unknowns,” probable cause determination, accelerated mean time to repair (MTTR) and increased productivity through the automation of processes and remediation.
User Experience & Business Analysis
User experience and business analysis is the identification and analysis of key business performance indicators, user experience, customer journeys and user behavior.
Combining end-user experience with back-end application and infrastructure telemetry is a vital component of full end-to-end observability. Observability platforms are able to emulate end-user behavior from multiple locations and device types through synthetic transactions while real-user monitoring evaluates the experience of both individual users and groups of users. Observability platforms go beyond system health to provide insights into the performance of key business services, transactions and objectives. Techniques such as funnel analysis and customer journey mapping provide insights into customer behavior, abandonment, conversions and even the financial value of transactions.
Automated Response
Automated response is the ability of the platform to react to configured, ingested or detected events by triggering actions, including remediation using internal or external automation frameworks.
Automated process and remediation capabilities reduce time to resolution while improving quality and productivity. For example, software developers can automate the rollback of new features following anomaly detection via integration with DevOps tool chains. Attempts to exploit a known vulnerability can be automatically blocked or infrastructure changes can be made via third-party orchestration or infrastructure-as-code platforms.
Use Cases
Site Reliability Engineering
Site reliability engineering is support for improving reliability and resilience for products that need to deliver customer value at speed and at scale while managing risk.
Site reliability engineers work with the product owner to understand operational requirements and define service-level objectives. Site reliability engineers work with product or platform teams to design and continuously optimize systems that meet defined SLOs. SREs are the traditional target audience of application performance monitoring and observability tools.
These teams must rapidly assess the quality and performance of recent releases of often business-critical applications with an emphasis on expedient diagnosis and remediation. This requires that the observability platform is able to ingest multiple forms of telemetry from across the application stack combined with a service map that facilitates fast interrogation of the data to understand application behavior. This should be augmented by AI/ML capabilities that can surface anomalies and contribute to probable root cause identification.
Platform Operations
Platform operations support the immediate and longitudinal understanding of the health and performance of platforms.
One of the key drivers of investment in observability platforms is to cater to the transformation from traditional application architectures to applications built using microservices, packaged in containers and deployed across flexible infrastructure. Typically, the containers are orchestrated using Kubernetes, and the line between the application and the intelligent infrastructure becomes blurred. This is especially true as cloud-native applications are isolated or abstracted from server, OS and even traditional network dependencies. These architectures are of enormous value to the business in terms of cost and agility, and they present new challenges to monitoring tools, such as the short lifetime of containers, which is often only a few seconds.
Software Engineering
Software engineering is engagement in the development, creation, validation, securing, deployment and maintenance of applications.
Software Engineering utilizes observability platforms throughout the development and deployment cycle. Buyers in this category value method-level code visibility, including the ability to compare and profile code in production environments. Furthermore, feedback on customer experience provides input into development prioritization, and synthetic transactions automate functional testing.
Cost Optimization
Cost optimizations is using telemetry analysis and insights to understand and optimize both workload and observability cost.
While not replacing a dedicated FinOps function, products in this market that excel at this use case provide cost, capacity and performance optimization capabilities to SREs and platform operations teams. Macroeconomic conditions have led to increased focus on cost and performance in a number of areas. Observability platform users with responsibility to optimize cost appreciate capabilities related to forecasting and optimization of cloud-hosted workloads, including insightful recommendations for capacity adjustments.
The cost of observability itself is also under scrutiny, with observability platform owners seeking capabilities to gain control of the cost of collecting and analyzing increasing volumes of telemetry.
Business Insights
Business insights are essential to those responsible for managing the delivery of services to end users who are aligned with the business function.
Typically, application owners are interested in nontechnical insights that provide both quantitative and qualitative measures of business service performance and customer journeys.
Insights available to these users have evolved from APM tools presenting IT telemetry in a way that is meaningful to the business via service-level objectives. Observability platforms now provide insights directly on sales, revenue, customer experience and other metrics related to strategic business outcomes, such as sustainability.
Buyers in this group value real-time business insights provided by a flexible data platform, comprehensive dashboarding capabilities and an intuitive user experience enhanced by a natural language interface.
AI Engineering
AI engineering is engaging in the delivery of and support for AI and GenAI solutions at scale.
AI engineering enables organizations to establish and grow high-value portfolios of AI solutions consistently and securely. In doing so, they rely on capabilities that enable them to monitor and observe the performance of AI and LLM models both during development and once in production. This may include LLM and AI model drift, bias and hallucination in production, token usage and the associated cost of LLM models as well as the comparative performance and cost across models. Just as application tracing enables observability of requests across a complex distributed application, prompt tracing provides similar transparency across increasingly complex and augmented prompts.
Vendors Added and Dropped
We review and adjust our inclusion criteria for Critical Capabilities as markets change. As a result of these adjustments, the mix of vendors in any Critical Capability may change over time. A vendor’s appearance in a Critical Capability one year and not the next does not necessarily indicate that we have changed our opinion of that vendor. It may be a reflection of a change in the market and, therefore, changed inclusion criteria, or of a change of focus by that vendor.
Added
The following vendors met the inclusion criteria and have been added to this Critical Capabilities research:
- Apica
- Coralogix
- ITRS
- Sciencelogic
- SolarWinds
Dropped
- Logz.io
- ServiceNow
Inclusion Criteria
Gartner’s Critical Capabilities research identifies and then analyzes the most relevant providers and their products in a market. By default, Gartner uses an upper limit of 20 providers to support the identification of the most relevant providers in a market. On certain occasions, the upper limit may be extended when the intended research value to clients might otherwise be diminished.
The inclusion criteria represent the specific attributes that analysts believe are necessary for inclusion in this research:
- Observability platform offerings must offer native support for all mandatory capabilities and a majority of the common capabilities described in Gartner’s market definition.
- Observability platform offerings must be delivered via SaaS. Vendors may also provide self-hosted alternatives for clients that require them, but the self-hosted options are outside the scope of this research.
Weighting for Critical Capabilities in Use Cases
| Critical Capabilities | Site Reliability Engineering | Platform Operations | Software Engineering | Cost Optimization | Business Insights | AI Engineering |
|---|---|---|---|---|---|---|
Ingest, Optimize, Store Telemetry | 20% | 5% | 0% | 20% | 10% | 5% |
Interoperability | 10% | 35% | 25% | 0% | 0% | 0% |
Exploration of Telemetry | 25% | 10% | 5% | 15% | 0% | 5% |
Observability Cost Control | 5% | 0% | 0% | 45% | 0% | 0% |
LLM Observability | 0% | 0% | 0% | 0% | 0% | 80% |
Generate Actionable Insights | 5% | 25% | 30% | 20% | 15% | 5% |
User Experience & Business Analysis | 10% | 0% | 10% | 0% | 75% | 5% |
Automated Response | 25% | 25% | 30% | 0% | 0% | 0% |
As of 28 June 2025 | ||||||
Source: Gartner (July 2025)
This methodology requires analysts to identify the critical capabilities for a class of products/services. Each capability is then weighted in terms of its relative importance for specific product/service use cases.
Critical Capabilities Rating
Each of the products/services has been evaluated on the critical capabilities on a scale of 1 to 5. A score of 1 equals Poor (most or all defined requirements are not achieved), while 5 equals Outstanding (significantly exceeds requirements).
Product/Service Rating on Critical Capabilities
| Critical Capabilities | Amazon Web Services | Apica | BMC Helix | Chronosphere | Coralogix | Datadog | Dynatrace | Elastic | Grafana Labs | Honeycomb | IBM | ITRS | LogicMonitor | Microsoft | New Relic | Oracle | ScienceLogic | SolarWinds | Splunk | Sumo Logic |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Ingest, Optimize, Store Telemetry | 3.4 | 3.1 | 3.5 | 4.1 | 3.8 | 4.3 | 4.3 | 4.0 | 4.1 | 4.1 | 3.5 | 3.1 | 3.5 | 3.6 | 3.8 | 3.1 | 3.2 | 3.6 | 3.4 | 3.2 |
Interoperability | 3.7 | 2.6 | 3.6 | 4.0 | 3.3 | 4.4 | 4.2 | 3.9 | 4.1 | 3.1 | 3.6 | 2.8 | 2.8 | 3.4 | 3.7 | 2.6 | 2.9 | 2.5 | 2.9 | 2.4 |
Exploration of Telemetry | 3.6 | 2.9 | 3.2 | 3.9 | 3.9 | 4.2 | 4.3 | 3.8 | 4.1 | 3.9 | 3.5 | 2.2 | 3.0 | 3.7 | 3.7 | 3.2 | 3.2 | 2.7 | 3.3 | 2.4 |
Observability Cost Control | 3.8 | 3.4 | 3.2 | 4.3 | 4.3 | 4.2 | 4.3 | 3.9 | 4.3 | 3.5 | 3.2 | 2.6 | 3.1 | 3.7 | 4.1 | 3.6 | 3.3 | 2.4 | 3.0 | 2.5 |
LLM Observability | 4.1 | 3.6 | 3.2 | 3.3 | 4.3 | 4.2 | 4.3 | 3.9 | 3.9 | 3.9 | 3.0 | 1.0 | 2.7 | 3.6 | 4.0 | 3.4 | 3.4 | 1.3 | 2.8 | 1.3 |
Generate Actionable Insights | 3.6 | 2.9 | 3.2 | 3.9 | 3.7 | 4.3 | 4.4 | 4.0 | 4.2 | 3.5 | 3.4 | 2.2 | 3.0 | 3.3 | 3.6 | 2.9 | 3.1 | 2.9 | 3.2 | 2.1 |
User Experience & Business Analysis | 3.4 | 2.1 | 2.8 | 3.8 | 3.4 | 4.3 | 4.3 | 4.1 | 4.1 | 3.9 | 3.7 | 2.4 | 2.8 | 3.5 | 3.4 | 2.9 | 3.0 | 2.8 | 3.6 | 2.5 |
Automated Response | 3.7 | 2.5 | 3.4 | 3.9 | 3.4 | 4.2 | 4.3 | 3.9 | 4.2 | 3.1 | 3.5 | 2.9 | 2.9 | 3.4 | 3.6 | 2.3 | 3.2 | 2.7 | 3.3 | 2.5 |
As of 28 June 2025 | ||||||||||||||||||||
Source: Gartner (July 2025)
Table 3 shows the product/service scores for each use case. The scores, which are generated by multiplying the use-case weightings by the product/service ratings, summarize how well the critical capabilities are met for each use case.
Product Score in Use Cases
| Use Cases | Amazon Web Services | Apica | BMC Helix | Chronosphere | Coralogix | Datadog | Dynatrace | Elastic | Grafana Labs | Honeycomb | IBM | ITRS | LogicMonitor | Microsoft | New Relic | Oracle | ScienceLogic | SolarWinds | Splunk | Sumo Logic |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
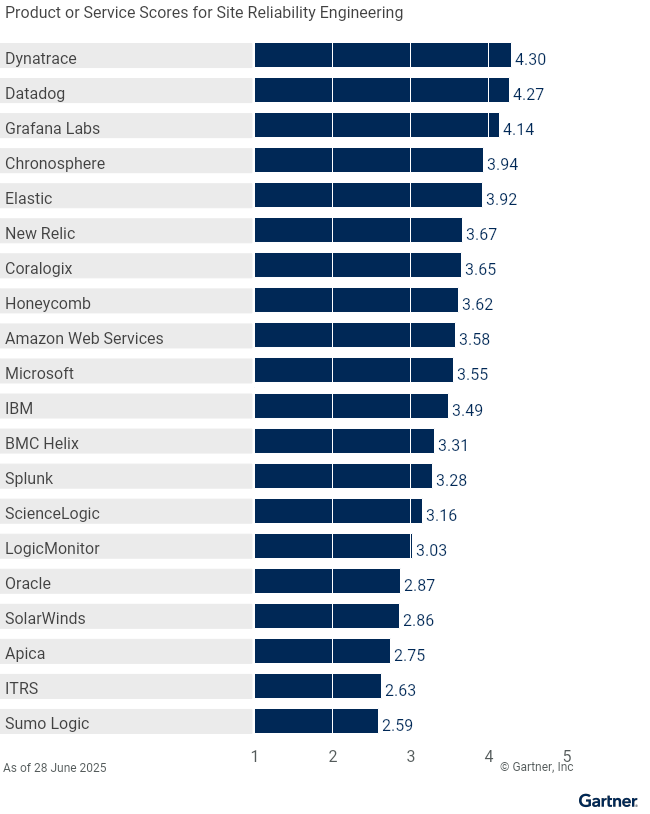
Site Reliability Engineering | 3.58 | 2.75 | 3.31 | 3.94 | 3.65 | 4.27 | 4.30 | 3.92 | 4.14 | 3.62 | 3.49 | 2.63 | 3.03 | 3.55 | 3.67 | 2.87 | 3.16 | 2.86 | 3.28 | 2.59 |
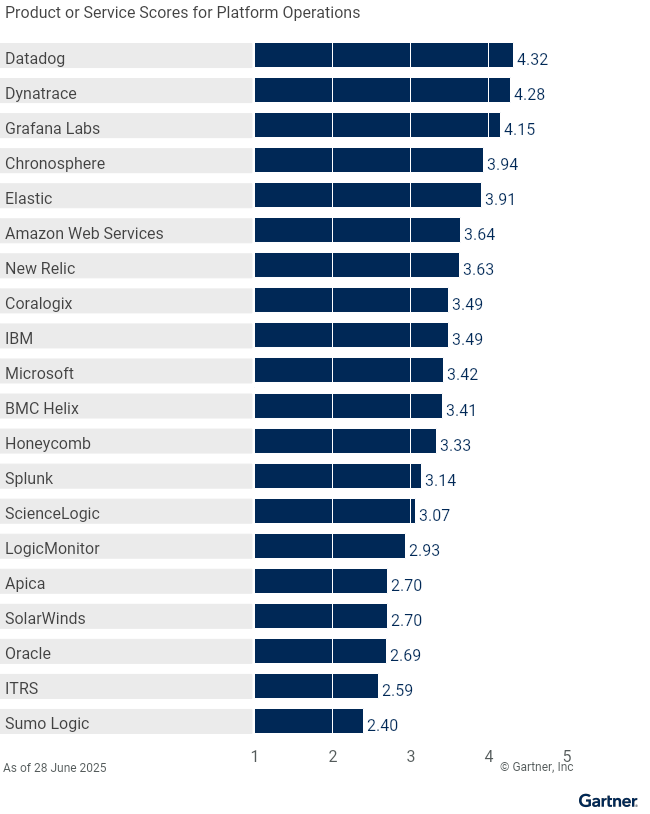
Platform Operations | 3.64 | 2.70 | 3.41 | 3.94 | 3.49 | 4.32 | 4.28 | 3.91 | 4.15 | 3.33 | 3.49 | 2.59 | 2.93 | 3.42 | 3.63 | 2.69 | 3.07 | 2.70 | 3.14 | 2.40 |
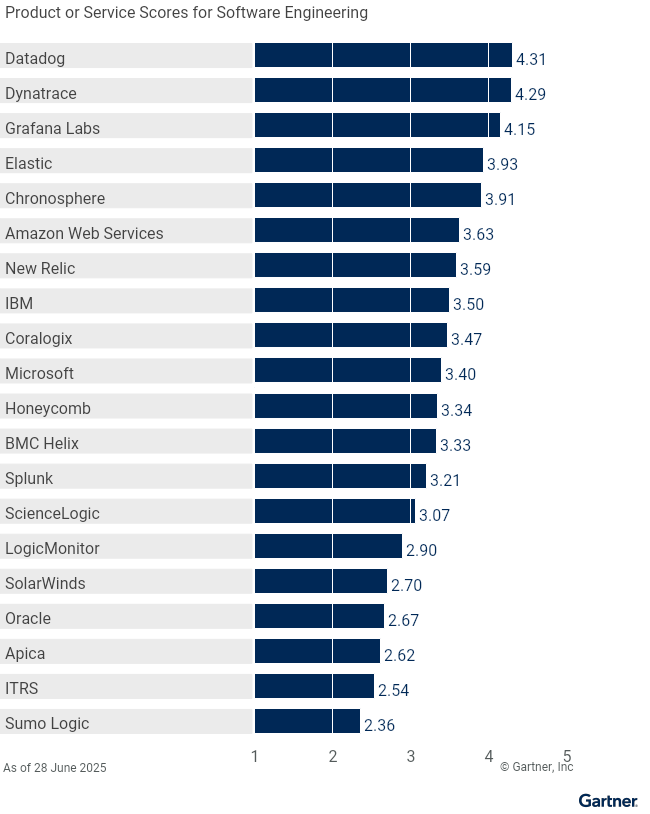
Software Engineering | 3.63 | 2.62 | 3.33 | 3.91 | 3.47 | 4.31 | 4.29 | 3.93 | 4.15 | 3.34 | 3.50 | 2.54 | 2.90 | 3.40 | 3.59 | 2.67 | 3.07 | 2.70 | 3.21 | 2.36 |
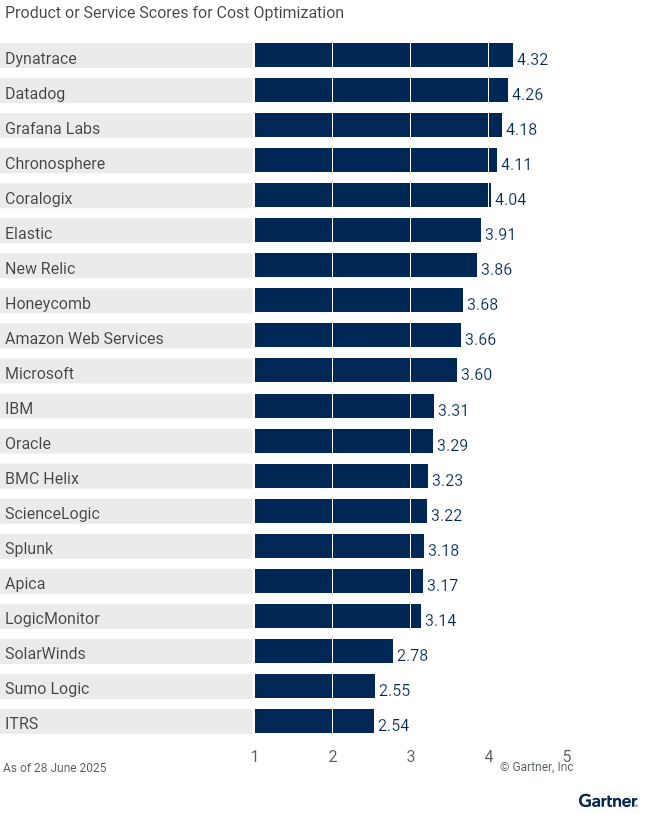
Cost Optimization | 3.66 | 3.17 | 3.23 | 4.11 | 4.04 | 4.26 | 4.32 | 3.91 | 4.18 | 3.68 | 3.31 | 2.54 | 3.14 | 3.60 | 3.86 | 3.29 | 3.22 | 2.78 | 3.18 | 2.55 |
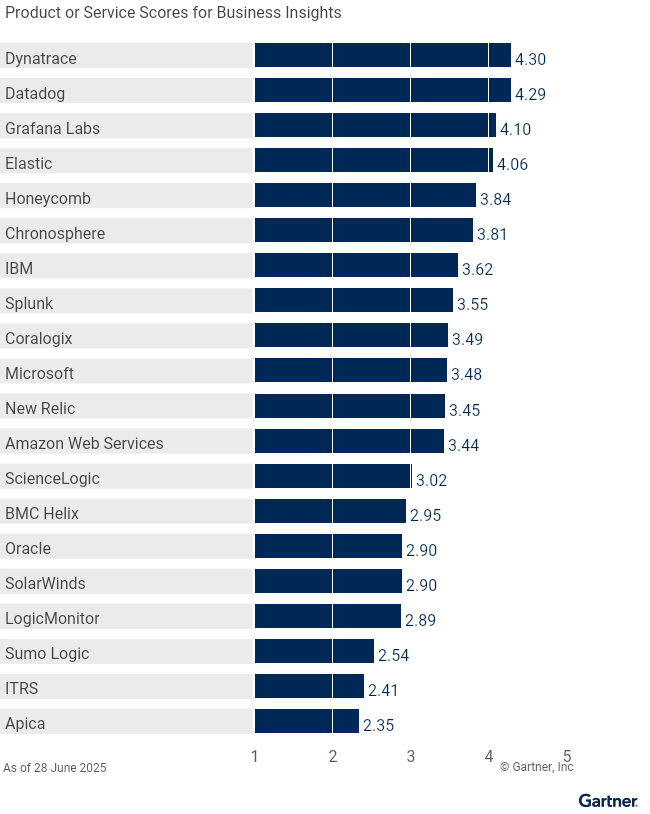
Business Insights | 3.44 | 2.35 | 2.95 | 3.81 | 3.49 | 4.29 | 4.30 | 4.06 | 4.10 | 3.84 | 3.62 | 2.41 | 2.89 | 3.48 | 3.45 | 2.90 | 3.02 | 2.90 | 3.55 | 2.54 |
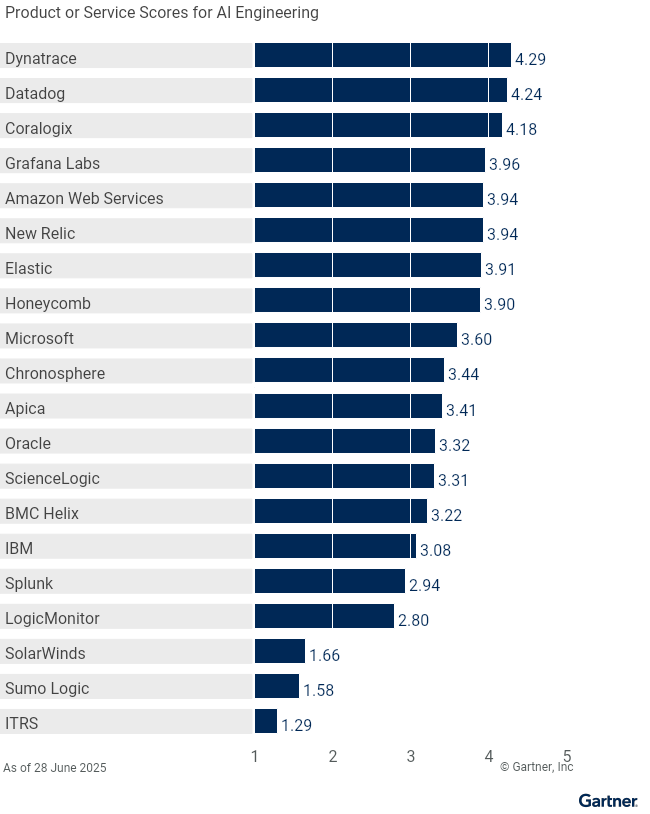
AI Engineering | 3.94 | 3.41 | 3.22 | 3.44 | 4.18 | 4.24 | 4.29 | 3.91 | 3.96 | 3.90 | 3.08 | 1.29 | 2.80 | 3.60 | 3.94 | 3.32 | 3.31 | 1.66 | 2.94 | 1.58 |
As of 28 June 2025 | ||||||||||||||||||||
Source: Gartner (July 2025)
To determine an overall score for each product/service in the use cases, multiply the ratings in Table 2 by the weightings shown in Table 1.
Critical Capabilities Methodology
This methodology requires analysts to identify the critical capabilities for a class of products or services. Each capability is then weighted in terms of its relative importance for specific product or service use cases. Next, products/services are rated in terms of how well they achieve each of the critical capabilities. A score that summarizes how well they meet the critical capabilities for each use case is then calculated for each product/service.
"Critical capabilities" are attributes that differentiate products/services in a class in terms of their quality and performance. Gartner recommends that users consider the set of critical capabilities as some of the most important criteria for acquisition decisions.
In defining the product/service category for evaluation, the analyst first identifies the leading uses for the products/services in this market. What needs are end-users looking to fulfill, when considering products/services in this market? Use cases should match common client deployment scenarios. These distinct client scenarios define the Use Cases.
The analyst then identifies the critical capabilities. These capabilities are generalized groups of features commonly required by this class of products/services. Each capability is assigned a level of importance in fulfilling that particular need; some sets of features are more important than others, depending on the use case being evaluated.
Each vendor’s product or service is evaluated in terms of how well it delivers each capability, on a five-point scale. These ratings are displayed side-by-side for all vendors, allowing easy comparisons between the different sets of features.
Ratings and summary scores range from 1.0 to 5.0:
1 = Poor or Absent: most or all defined requirements for a capability are not achieved
2 = Fair: some requirements are not achieved
3 = Good: meets requirements
4 = Excellent: meets or exceeds some requirements
5 = Outstanding: significantly exceeds requirements
To determine an overall score for each product in the use cases, the product ratings are multiplied by the weightings to come up with the product score in use cases.
The critical capabilities Gartner has selected do not represent all capabilities for any product; therefore, may not represent those most important for a specific use situation or business objective. Clients should use a critical capabilities analysis as one of several sources of input about a product before making a product/service decision.