
Adopt Site Reliability Engineering Principles to Get Digital Workplace Operations AI-Ready
Modern digital workplaces rely on numerous interconnected devices and applications, making them too complex for traditional, manual IT operations. Heads of I&O must adopt SRE principles — balancing risk and speed, eliminating toil, and treating operations as software — to boost reliability, cut costs, and enable AI automation.
Strategic Planning Assumption
By 2028, 80% of enterprises will use site reliability engineering practices across their organizations to optimize product design, cost and operations, up from 30% in 2024.
Impact Brief
In the next 12 months, heads of I&O must create operational headroom to support critical AI initiatives. Traditional “keep the lights on” operations consume too many resources and fail to prevent employee frustration. By adopting SRE principles, heads of I&O can fundamentally change the economics of their support model.
The opportunity: SRE practices optimize operational efficiency by automating manual interventions, ensuring staff time is spent on engineering value rather than repetitive tasks.
The risk: Organizations that rename operations teams to “SRE” without changing the underlying principles risk failing to deliver tangible benefits and may reduce DEX.
Actions and Cautions
To modernize digital workplace operations using SRE principles, heads of I&O should take the following actions:
Actions
- Manage “toil” aggressively: Cap the time spent on manual, reactive operational work (toil) at 50%. Mandate that the remaining 50% be spent on engineering projects that automate future work, improve system architecture and enhance DEX.
- Govern velocity using error budgets: Use the concept of an “error budget” to make data-driven decisions on when to solely focus on stability issues versus when to accelerate the deployment of new features. If you have even a small amount of error budget, use it in service of making long-term improvements to the user experience.
- Shift to a “systems” mindset: Move beyond component-level management. Treat the digital workplace as an interconnected system — comprising device, app, network, user — where reliability is a core feature that must be engineered, not just supported.
Cautions
- Avoid “SRE in name only”: Do not simply rebrand existing engineers as site reliability engineers without changing their scope, authority, or backlog. This is a common mistake that leads to failure.
- Do not neglect culture: SRE requires a “blameless” culture that views incidents as engineering failures to be analyzed and fixed systemically, rather than human errors to be punished.
- Don’t automate bad processes: Simply automating a broken process is not SRE. You must reengineer the process for reliability and maintainability before applying automation.
- Be proactive: Improve reliability proactively rather than in response to incidents and problems.
How to Execute
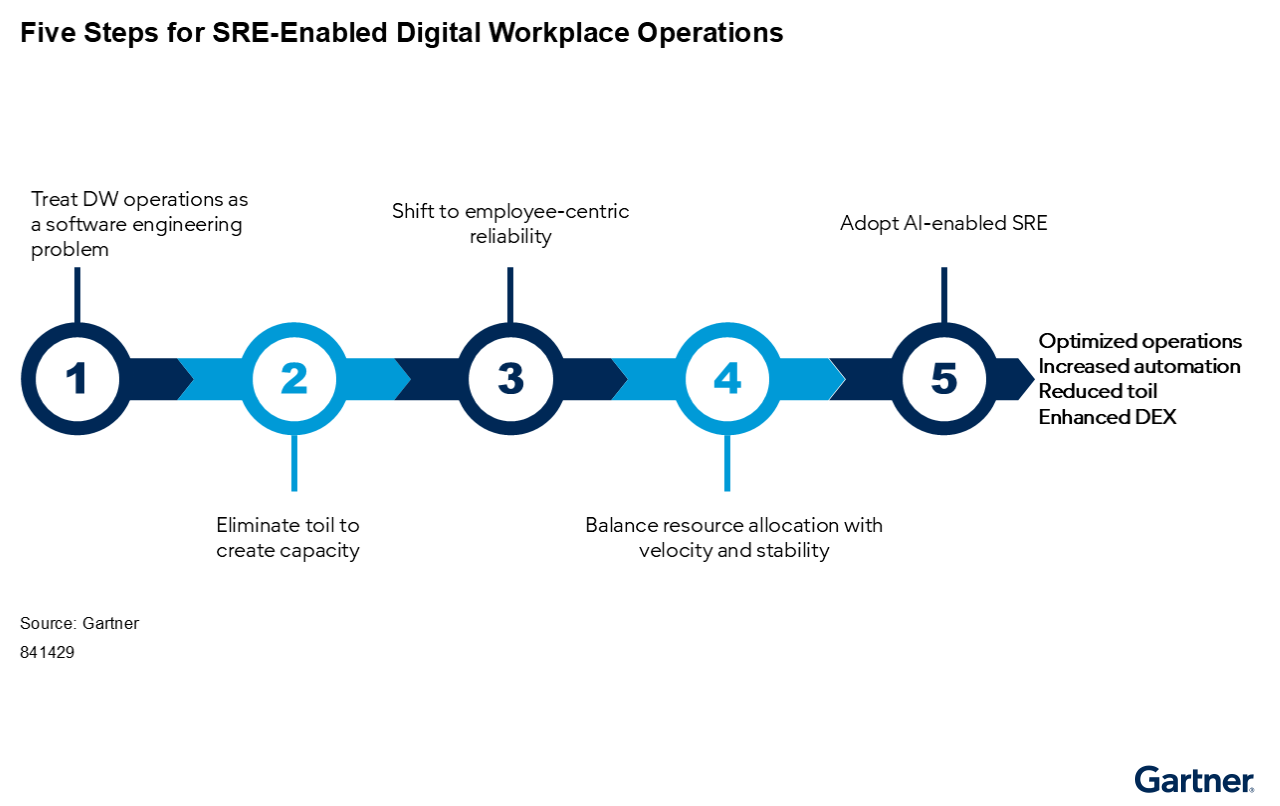
Heads of I&O must transition digital workplace operations from a reactive support function to a proactive engineering discipline. This requires applying SRE principles, traditionally reserved for cloud-native applications, to the end-user computing environment. Figure 1 highlights the steps needed to align digital workplace (DW) operations to SRE principles:
Figure 1: Five Steps for SRE-Enabled Digital Workplace Operations
What is site reliability engineering (SRE)?
SRE is a collection of systems and software engineering principles used to design and operate scalable, resilient systems. SRE practices are essential for modern software and cloud-native infrastructure, enabling organizations to innovate rapidly while improving availability, reliability, and performance. SRE extends beyond traditional operations to optimize system design and value delivery, focusing on customer needs and experiences. The approach emphasizes collaboration between site reliability engineers and product or platform teams to define service-level indicators (SLIs) and service-level objectives (SLOs) that guide reliability efforts and ensure systems meet employee expectations (see Site Reliability Engineering Essentials).
Step 1: Treat Digital Workplace Operations as a Software Engineering Problem
The core tenet of SRE is using software engineering to solve infrastructure problems. In the digital workplace, this means moving away from manual “click-ops” (manually clicking through GUIs to fix issues) toward code-based configuration and remediation.
- Define infrastructure as code (IaC): Ensure Windows, macOS and infrastructure configurations, policies, and application deployments are thoroughly documented and version-controlled. Where possible, use infrastructure as code, scripts, or procedures to enable version control. This approach allows for rapid rollback if a change destabilizes the environment. Where this is not possible — for example, iOS or Android — use the same IaC repositories to document and version control processes, procedures and configuration settings.
- Adopt “blameless” root cause analysis: When the digital workplace fails (e.g., a bad patch causes widespread crashes), the focus must be on the systemic cause, not the person who pushed the button. The output of an incident should be an engineering task to prevent recurrence, not a reprimand.
Step 2: Eliminate Toil to Create Capacity
“Toil” is defined as manual, repetitive, tactical work that scales linearly with the service size (for example, manually clearing disk space, resetting passwords, or tagging assets). SRE mandates that toil must be minimized to free up time for engineering.
- The 50/50 rule: Aim for a target where 50% of the digital workplace team’s time is spent on operations (incidents, tickets) and 50% on engineering (automation, architecture improvements).
- Automate remediation: Instead of fixing the same issue 10 times, engineer a self-healing script to fix it automatically. Use automation capabilities within endpoint management, DEX tools and IaC initiatives to trigger these scripts based on alerts.
- Stop “feeding the machine”: If a process requires constant manual intervention to keep running, it is broken. Prioritize engineering resources to redesign that process to be self-sustaining.
Step 3: Shift to Employee-Centric Reliability
Traditional operations focus on server uptime. SRE focuses on the employee’s experience. Reliability is defined by whether the user can perform their job, not whether the server is pingable.
- Measure what matters: Align your reliability targets (SLOs) with the actual digital employee experience (DEX). A server might be up, but if the login takes five minutes, the service is effectively unavailable to the user.
- Align engineering to sentiment: Use employee sentiment data to validate your engineering priorities. If telemetry says the network is fine, but users report video lag, trust the user sentiment and direct engineering resources to investigate the disconnect.
Step 4: Balance Resource Allocation With Velocity and Stability
One of the hardest conflicts in IT is the tension between the need for speed (e.g., deploying Windows 11, new apps, patch deployment) and the need for stability. SRE solves this with the error budget. While service-level indicators (SLIs) and objectives (SLOs) are the mechanisms used to measure this, the error budget is the governance policy that dictates the team’s behavior.
- Define the budget: The error budget is 100% minus your reliability target. If your target is 99% reliability, your error budget is the remaining 1%. This 1% is the amount of “risk” you are allowed to “spend.”
- Spend the budget: As long as you are within your error budget (reliability is high), you should aggressively push changes, updates, and new features.
- Enforce the freeze: If you exhaust the error budget (reliability drops below target), you must halt new feature releases. Engineering resources must pivot immediately to “paying down technical debt” and stabilizing the environment until reliability recovers.
Step 5: Adopt AI-Enabled SRE
If adopting SRE principles for the first time, integrate AI to accelerate the transition from reactive automation to predictive prevention. AI can assist in deploying the new processes and enabling staff who are digital workplace engineers bridge the initial gaps in their SRE knowledge.
- Predictive capacity planning: Use AI to forecast infrastructure needs (e.g., DaaS/VDI capacity) based on usage trends to prevent performance degradation before it happens.
- Intelligent alerting: Use AI to correlate events and reduce alert noise, allowing SREs to focus on genuine anomalies rather than false positives.
- Investigate AI-enabled SRE tools: AI SRE tooling can lower the cost of SRE adoption, meet operational demands and deliver effective reliability, efficient products, platforms and services. See Market Guide for AI Site Reliability Engineering Tooling.
Success Measures
Successfully implementing SRE principles results in a more resilient digital workplace and a more efficient IT team.
KPI Profile: Operational Efficiency (Toil Reduction)
- KPI name: Toil ratio
- KPI definition: The percentage of time the team spends on manual, repetitive operational work versus engineering work.
- Specific measure: (Hours spent on reactive tickets + manual tasks) / Total team hours.
- Business objective: Reduce toil to <50% to create capacity for strategic initiatives and innovation.
KPI Profile: Service Reliability (Error Budget Adherence)
- KPI name: Error budget remaining
- KPI definition: The measure of available “risk” capacity remaining before stability policies must be enforced.
- Specific measure: 100% − (Actual reliability score / Target reliability score).
- Business objective: Balance the speed of innovation with the stability of the environment. If the budget remains unspent, the team is moving too slowly; if exhausted, the team is moving too recklessly.
Contributors
Daniel Betts, Hassan Ennaciri, Chris Saunderson
Evidence
1 Digital Workplace Maturity Assessment Results. Data was collected through the Digital Workplace Maturity Assessment Tool, which helps IT leaders assess their digital workplace maturity and align with their organization’s ambitions for the digital workplace. Survey respondents receive a report identifying areas of greater or lesser maturity to help plan digital transformation initiatives in the future. As of publication, the dataset represents more than 1,200 unique assessments collected since January 2024 from globally distributed companies of all sizes.
2 Three Strategies to Reduce End-User Services Total Cost of Ownership.