
SRE for EUC: Endpoint Reliability as the “Last Mile” of Site Resilience
Over the past two decades, the global enterprise technology ecosystem has undergone a profound structural and operational transformation. Driven by the imperative to deliver highly available, hyper-scalable, and deeply resilient digital services, organizations have fundamentally reimagined their backend infrastructures. At the absolute core of this transformation has been the widespread adoption and maturation of Site Reliability Engineering (SRE). Pioneered in the early 2000s to manage vast, complex cloud infrastructures with unprecedented precision, SRE permanently shifted the paradigm of IT operations by treating systems operations strictly as a software engineering problem. By developing systems and tools to automate operations away, SRE introduced highly rigorous, deterministic methodologies designed to eliminate manual toil and ensure that complex distributed systems remain operational under immense computational scale.
The financial and operational results of this engineering discipline are exceptionally well-documented. SRE has transitioned from a niche operational philosophy to the foundational bedrock of modern enterprise computing.
However, despite these massive capital and intellectual investments in backend reliability, a critical, systemic vulnerability remains deeply embedded within the modern enterprise architecture. This vulnerability threatens to unravel the entirety of the SRE investment thesis. It is the true "last mile" of digital delivery—the endpoint device itself, which serves as the final physical computing boundary where software execution completes and meets the end-user.
Traditional SRE methodologies operate on a fundamentally flawed assumption: they assume that if the backend application microservices are highly available and processing database requests within strictly defined latency parameters, the digital service is functioning correctly and delivering value. But as hybrid workflows and End-User Computing (EUC) frameworks have become the ubiquitous standard, the endpoint—whether it is a corporate-managed physical laptop or a remote virtual desktop interface (VDI)—is now the definitive point of service consumption.
If an enterprise invests tens of millions of dollars to achieve "five nines" (99.999 percent) of availability in its backend Kubernetes clusters, but the endpoint device consuming those resources is crippled by aggressive background updates, localized CPU exhaustion, or catastrophic operating system crashes, the effective reliability of that digital service drops to zero. The entire SRE investment thesis—which promises maximized worker productivity and continuous service availability through backend optimization—fundamentally breaks down if the endpoint devices are intrinsically unreliable.
This structural disconnect necessitates an urgent and highly strategic evolution. The convergence of legacy EUC and modern Site Reliability Engineering has birthed a critical new operational discipline: Endpoint Reliability Engineering (ERE). ERE represents the systematic, uncompromising application of SRE principles to the endpoint fleet. By treating the laptop or desktop as an extension of the "site," ERE decisively shifts focus from reactive device management to continuous autonomous reliability, securing the final and most critical segment of the digital supply chain.
The Backend SRE Investment Thesis
Traditional Site Reliability Engineering focuses almost exclusively on the reliability, scalability, and performance of upstream infrastructure segments. In these backend environments, performance can be meticulously optimized due to a high degree of architectural homogeneity and centralized administrative control. SRE teams deploy highly advanced distributed tracing protocols and dynamic scaling mechanisms to ensure that internal microservices do not buckle under sudden spikes in user load.
Yet, these highly engineered backend mechanisms remain entirely decoupled from the chaotic reality of the endpoint. The local operating system on an employee's laptop represents a highly volatile execution environment, characterized by fiercely competing local software agents, continuous security scanning, and unpredictable user behaviors.
When critical performance degradation occurs within this device-level environment, it is completely invisible to standard backend monitoring tools. A backend server might proudly report an API response time of 50 milliseconds, satisfying its internal Service Level Objective and generating a "green" status on the SRE team's dashboard. However, if the user's local endpoint is suffering from severe CPU thermal throttling due to a misconfigured endpoint detection and response (EDR) agent, or if the system crashes into a Blue Screen of Death (BSOD), the actual time-to-interact for the end-user goes to zero. From the backend perspective, the service is perfectly healthy; from the endpoint's perspective, the service is dead.
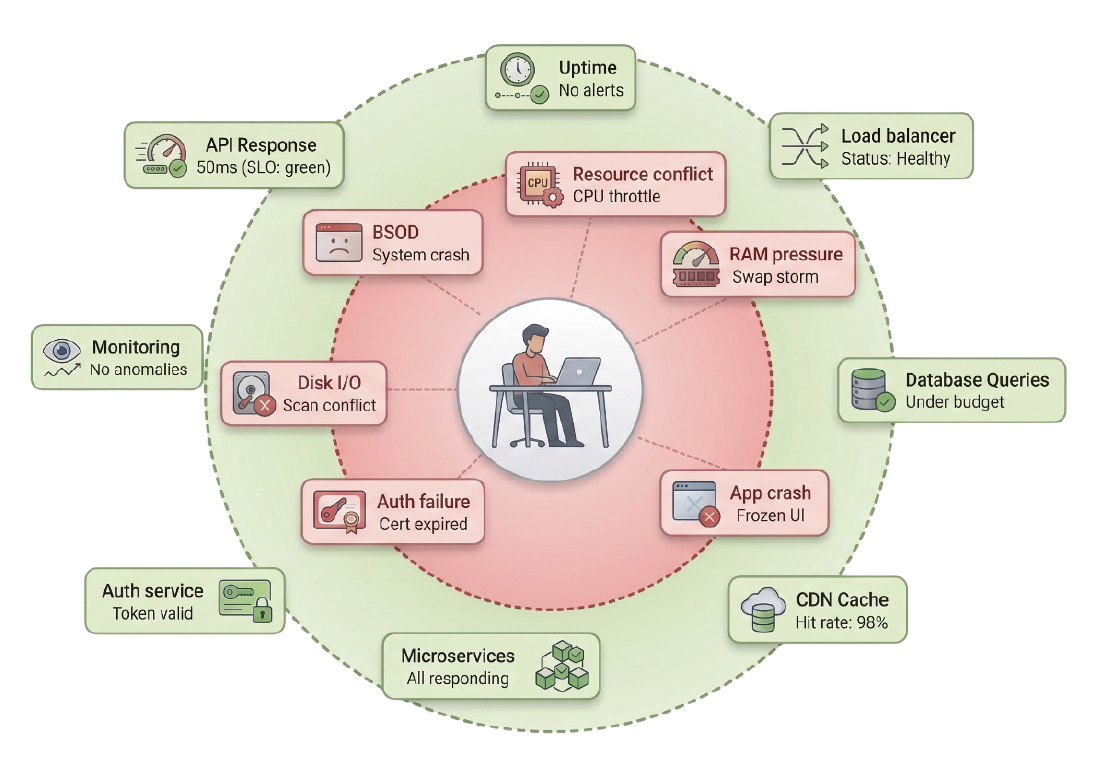
Endpoint Failures and the True Bottleneck of Business Value
In the context of SRE, the endpoint must be viewed as the absolute final node of the distributed computing network. When this node fails, the economic damage is profound. While backend outages trigger massive, coordinated incident responses, endpoint failures are often suffered in silence, causing a creeping, chronic destruction of productivity.
Downtime costs extend far beyond a single IT ticket; they include total revenue loss, idle staff, and delayed deliverables. Industry analyses reveal that even small and mid-sized businesses can lose up to $100,000 per hour during critical localized outages. For example, a standard 15-person team losing access to their systems for just two hours due to device lockups equals 30 paid hours of idle, completely unproductive time. According to Google, at the enterprise level, outages and service disruptions are severely impactful, lasting an average of 196 minutes across all industries.
Furthermore, traditional support models for resolving these endpoint failures are inherently manual and deeply inefficient. Industry surveys of SRE and IT operations professionals reveal that 41 percent feel that half or more of their work is "toil"—mostly manual, repetitive, and tactical tasks that could easily be automated. SRE aims to systematically eliminate this toil to free up engineering time. If the legacy IT focus remains strictly on backend uptime while ignoring the massive operational drag of failing endpoint hardware and OS crashes, the overarching promise of cloud-era productivity will never be realized.
Why EUC Must Rely on Deterministic Engineering
Site Reliability Engineering is, at its very core, a hard engineering discipline firmly rooted in objective mathematics, system design, and automation. It relies exclusively on Service Level Indicators (SLIs) that are infinitely measurable, temporally consistent, and immediately actionable by an automated system or a human engineer. In contrast, traditional DEX practices have relied on a combination of endpoint data and employee surveys to gauge performance—often to make up for hard telemetry gaps. But sentiment, by its very definition, is inherently subjective, deeply retrospective, and subject to severe human reporting bias.
Consider a routine operational scenario where an enterprise endpoint fleet is experiencing an intermittent memory leak caused by a recent update to a critical business application. A DEX sentiment survey deployed to the fleet might simply reveal that 40 percent of users are "highly frustrated with laptop speed today." This qualitative, emotion-based feedback provides little actionable telemetry for an IT engineering team. It does not identify the specific fault domain, the exact application version causing the issue, or the extent of the memory leak in megabytes. It is essentially a statement of abstract pain, offering no diagnostic cure.
Contextual Metrics and the Foundation of Deterministic Engineering
Endpoint Reliability Engineering entirely dispenses with the pursuit of sentiment and replaces it with deterministic, kernel-level telemetry and hard engineering metrics. Just as a backend Site Reliability Engineer meticulously monitors garbage collection pauses in a cloud-based application, an Endpoint Reliability Engineer continuously monitors local page faults, application thread exhaustion, system crashes, battery health, and device age.
By measuring the actual physical and computational states of the machine rather than surveying the fluctuating emotions of the human operator, ERE enables the deployment of highly complex, automated remediation pipelines. An autonomous algorithm cannot dynamically execute a self-healing PowerShell script based on a user reporting they are "annoyed." It can, however, instantly execute a remediation workflow when an edge sensor detects that an endpoint's disk usage has exceeded a defined performance threshold, or when specific endpoints fail to maintain a required response time. In the end, a fast, reliably performant system is what satisfies a user’s productivity needs—not the opportunity to respond to endless IT satisfaction surveys.
Comprehensive Edge Observability
The foundational layer of any ERE architecture is edge-native analytics. Traditional IT monitoring tools rely heavily on polling mechanisms that periodically pull data from devices on a set schedule. This creates massive blind spots where critical transient errors are completely missed. ERE utilizes highly optimized, lightweight, event-driven agents that run continuously on the endpoint operating system, executing deep, contextual telemetry collection in real-time.
These agents monitor the actual endpoint hardware, the local operating system state, the screen focus, and the local software execution. This comprehensive, continuous visibility eliminates the traditional IT "blame game." When a critical application fails to load for a remote executive, ERE analytics can instantly and definitively determine if the fault lies in a localized CPU thermal spike on the laptop, a local memory fault, or a systemic software conflict.
Autonomous Self-Healing and Programmatic Remediation Pipelines
The defining operational characteristic of Endpoint Reliability Engineering is the decisive transition from manual incident response to autonomous self-healing. In a traditional IT support model, resolving an endpoint issue follows a highly inefficient, human-dependent workflow requiring manual ticketing, remote log-ins, and investigative troubleshooting. This archaic process routinely takes hours, resulting in massive productivity losses. In fact, research indicates that the average time employees spend troubleshooting IT issues is roughly 3 hours per week.
ERE replaces this manual workflow with automated remediation playbooks designed to autonomously address known, recurring failure modes without human intervention. When the ERE edge agent detects a system anomaly—such as memory bloat, a disconnected local print spooler service, or a failing background synchronization service—it automatically matches the real-time telemetry signature to a massive, centralized database of predefined remediation scripts.
The autonomous self-healing workflow operates flawlessly at machine speed:
- Detect: The edge telemetry agent detects the anomaly in real-time.
- Diagnose: The system analyzes the root cause of the issue.
- Remediate: The platform recommends or executes the corresponding remediation.
- Verify: The system continuously monitors the endpoint to vet its operational state.
- Log: The action is logged and enriched with context for future analytical review.
Core SRE Principles Applied to Digital Employee Experience
To successfully integrate SRE into EUC, organizations must redefine their foundational metrics. The SRE hierarchy of Service Level Indicators (SLIs), Service Level Objectives (SLOs), and Service Level Agreements (SLAs) serves as a mechanism for translating technical data into business value.
Service Level Indicators for the Modern Endpoint
An SLI is a quantitative measure of a service's performance from the user's perspective. In the context of EUC and DEX, traditional infrastructure metrics like CPU utilization or server uptime are insufficient because they do not correlate directly with employee satisfaction. Instead, EUC teams must adopt Golden Signals tailored for the endpoint.
| SLI Category | EUC Metric Example | Impact on Employee Productivity |
|---|---|---|
| Latency | Application launch time, web page load speed, boot time | High latency leads to context switching and frustration. |
| Traffic | Network throughput, VPN utilization, web requests | Insufficient bandwidth disrupts remote collaboration and workflow. |
| Errors | Application crash rate, Blue Screen of Death (BSOD), failed logins | Immediate cessation of work and high support costs. |
| Saturation | Memory exhaustion, disk I/O bottlenecks, CPU spikes | Gradual performance degradation that hinders flow state. |
| Availability | Fraction of time a device or service is usable | Total loss of productivity during downtime. |
The most effective SLIs measure what users actually experience. For example, rather than measuring server latency, a DEX-focused SLI would measure the 95th percentile of application response time at the endpoint. Success occurs when SLO compliance directly correlates with user satisfaction.
The Quantifiable ROI Business Case for ERE
The operational transition from legacy EUC to a highly advanced ERE architecture requires significant upfront capital investment. Validating this enterprise investment requires a financial model built on quantifiable, hard metrics rather than theoretical productivity gains. The business case for ERE is deeply anchored in measurable value creation: massive Service Desk labor arbitrage, operational efficiency, and predictive hardware lifecycle management.
1. Service Desk Ticket Volume Reduction and Toil Arbitrage
The most immediate, visible financial return of an ERE implementation is the massive reduction in Level 1 and Level 2 IT support ticket volumes. In a traditional EUC model, technicians frequently spend immense amounts of their workday executing manual data handoffs and managing routine issues. Across Lakeside Software’s customer portfolio, customers state that an average of 15 percent of their total IT costs tied up in labor, making the financial burden of this inefficiency immense.
ERE permanently alters this economic equation through the relentless application of foundational automation and proactive remediation. By tightly integrating telemetry directly into the overarching IT Service Management (ITSM) platform, ERE enables proactive, systemic ticket deflection.
The early detection of failing hardware components or outdated local security definitions triggers automated background remediation. Organizations utilizing AI-driven remediation and proactive support frequently report significant cost reductions due to lower help desk expenses and the rapid scaling of self-service interventions. This represents pure labor arbitrage, allowing the IT organization to permanently reallocate highly paid engineering headcount from reactive firefighting to proactive infrastructure architecture.
2. Automated Incident Remediation and Extreme MTTR Compression
Beyond routine ticket deflection, ERE delivers massive ROI through the acceleration of incident remediation and the algorithmic compression of Mean Time to Resolution (MTTR). Traditional ITSM metrics merely measure human efficiency constrained by the physical limits of manual dashboard observation. ERE, operating on the principles of hyperautomation, processes millions of telemetry events per second to identify the root cause of an incident with extraordinary precision.
The downstream financial impact of this capability is profound. By drastically lowering MTTR through automated remediation, organizations successfully preserve continuous worker productivity and prevent revenue-impacting infrastructure downtime.
3. Predictive Hardware Lifecycle Extension and CapEx Deferral
One of the most capital-intensive aspects of managing a distributed workforce is hardware procurement. Historically, IT organizations have relied on rigid schedules—such as a three-year hardware refresh cycle—to manage their laptop fleets. This forces the premature, wasteful retirement of perfectly viable hardware, while simultaneously failing to identify devices that will physically fail months before their scheduled refresh date.
Endpoint Reliability Engineering introduces predictive maintenance directly into the hardware lifecycle. By analyzing granular telemetry derived directly from the physical CPU, battery capacitance degradation, and internal thermal sensors, ERE algorithms can predict impending hardware failures with massive accuracy. A 2024 Intel-commissioned Forrester study specifically measuring the economic impact of optimized enterprise hardware platforms found that leveraging these advanced capabilities yielded up to a 213 percent ROI over three years, alongside an astounding 90 percent reduction in hardware-related on-site IT visits.
Because the ERE agent continuously optimizes the endpoint operating system in the background—cleaning corrupt registries and relentlessly managing resource-heavy background services—the physical hardware experiences significantly less daily operational stress, vastly extending its usable lifecycle.
Operationalizing EUC Reliability Engineering with DEX
Achieving the formidable ROI promised by Endpoint Reliability Engineering requires a holistic organizational transformation. It demands shifting the culture of the EUC department from a posture of reactive IT support to one of proactive, software-driven Site Reliability Engineering.
Enforcing the 50/50 Rule at the Endpoint
A foundational tenet of SRE culture is the strict enforcement of the "50 percent rule," where reliability engineers are expressly prohibited from spending more than 50 percent of their working hours on manual, repetitive operational toil. The remaining 50 percent of their time must be dedicated to higher-order software engineering, advanced tool development, and the creation of automation projects.
In legacy EUC environments, engineers operate at near 100 percent operational capacity, perpetually drowning in daily break-fix tickets. SRE surveys reveal that over 40 percent of practitioners report that half of their work consists of manual, repetitive tasks that should be automated. By aggressively deploying ERE automation and out-of-the-box self-healing scripts, IT leadership can instantly eliminate large swaths of this toil.
Shifting from SLAs and XLAs to SLOs and Error Budgets
Finally, the complete transition to an ERE architecture requires a fundamental modernization of how the enterprise measures success. Legacy EUC environments measure operational success based on performative Service Level Agreements (SLAs), such as "average time to answer the phone."
Endpoint Reliability Engineering replaces these with strict Service Level Objectives (SLOs) and Service Level Indicators (SLIs) for the endpoint fleet itself. An SLO defines a clear, mathematical target for service reliability. For instance, a properly defined ERE SLO might dictate that "99.9% of all global endpoints must maintain an application crash rate below 1% during active business hours."
If a specific geographic region or hardware subset begins to experience elevated failure rates that violate these thresholds, the ERE system automatically consumes its designated "error budget". The error budget quantifies the amount of acceptable unreliability a system can tolerate before customer happiness is impacted. In EUC, the error budget serves as a financial and operational currency that balances the speed of change with the necessity of stability. The error budget represents the acceptable level of unreliability; for a 99.9% SLO, the error budget is exactly 0.1%.
Once this mathematical error budget is depleted, the enterprise engineering team must enact predefined error budget policies. This means they are operationally forced to halt the deployment of any new, non-critical features—such as aggressive OS feature updates or new background agents—and dedicate all available resources strictly to stabilizing the affected endpoints until the budget recovers. This mechanism mathematically enforces the delicate balance between operational agility and infrastructure stability at the absolute edge of the network.
Quantifying the ROI: The Business Case for SRE in EUC
To secure executive buy-in for an SRE-DEX transformation, IT leaders should present a compelling financial case based on measurable ROI. Organizations with mature SRE practices report significantly better outcomes across all key performance indicators. For example, our research shows that a 5,000+ seat enterprise could realize a 235% ROI from ERE implementation over a three-year period, with a payback period of just 9 months. The financial impact includes $3.4 million in saved operational costs and $4.7 million in avoided downtime. The chart that follows contains additional useful metrics sourced for the SysTrack customer community:
| Metric | Traditional EUC Operations | ERE Operations | Improvement |
|---|---|---|---|
| Annual Uptime | 99.9% (3 nines) | 99.99% (4 nines) | 90% reduction in downtime. |
| Annual Downtime | 8.76 hours | 52.56 minutes | 7.8 hours reclaimed per user. |
| Incident Resolution | 1.0x (Baseline) | 4.1x Faster | Significant MTTR reduction. |
| Outage Frequency | Baseline | 62% Fewer Outages | Improved stability. |
| Manual Effort (Toil) | High | 71% Reduction | Reallocated to innovation. |
| Deployment Frequency | Monthly | Multiple times per day | 340% increase in velocity. |
Winning the Acronym Bingo: SRE, EUC, DEX, and ITSM
The integration of Digital Employee Experience platforms and Site Reliability Engineering principles represents a significant shift-left in end-user computing. By moving away from custom, reactive support models toward a rigorous framework of SLIs, SLOs, and error budgets, organizations can dramatically reduce the cost of ITSM while simultaneously improving the productivity and satisfaction of their workforce.
The massive capital investments poured into public cloud migrations and backend Site Reliability Engineering over the past decade have successfully pushed server-side availability to historical heights. Yet, the realization of this immense financial value remains critically dependent on the structural integrity of the final computing node: the physical endpoint device. If the remote user's laptop is inherently unstable, locally resource-starved, or continuously crashing, the entire upstream cloud infrastructure investment is rendered completely ineffective.
Endpoint Reliability Engineering (ERE) represents the necessary architectural maturity of End-User Computing. By systematically applying the proven principles of SRE—including strict SLO enforcement, error budget management, and the relentless elimination of manual toil—directly to the endpoint fleet, ERE extends SRE to the “last mile” of the digital enterprise. The resulting labor arbitrage, MTTR compression, cost savings, and hardware lifecycle extensions yield a highly quantifiable ROI that cements ERE as a fundamental pillar of modern operational resilience.