A Complete Practical Guide of Deep Learning Platform
1. Criteria of Selecting a Deep Learning Platform
1.1 Well-known Domestic and Overseas Deep Learning Platforms
In order to better satisfy needs in business scenarios and increasingly improve research and development capabilities, corporations with strong technology have built their own deep learning platforms. Leading platforms, in terms of overall capacity, include Google Cloud Platform, AWS Machine Learning, and Microsoft Azure Machine Learning.
At the same time, many high-level deep learning platforms have appeared in China, such as Tencent DI-X, Alibaba Cloud PAI, Baidu Paddle Paddle, and Qiniu Cloud AVA, etc. These platforms enable users to conduct large-scale trainings with different deep learning frameworks, manage models, perform massive batch forecasting online, and eventually achieve practical use with integrated API.
1.2 Comprehensive Evaluation Criteria of Deep Learning Platforms
All deep learning platforms have their own unique advantages. For users who want to fully integrate deep learning technology with their business scenarios, the following ten criteria should be followed in building or selecting a platform.
- Data preprocessing support: the data loss rate should be less than 0.01%, and batches of data can be processed into unified formats.
- Visualization of performance indicators: initial parameters of models and learning rate can be adjusted, such as Accuracy, loss, mAP, etc.
- Mainstream frameworks support: such as MXNET, TENSORFLOW, PYTORCH, CAFFE, etc.
- Low parameter exchange delay in training: less than or equal to 200ms.
- Strong scalability: private/public clouds are supported with the use of distributed storage and computation.
- User-friendliness: new users are able to use the platform to start training after 6 hours’ study.
- Quick private deployment: the deployment of customized deep learning platforms can be finished within 48 hours.
- Separation of Storage and Computation: computing clusters can be separated from storage clusters; data exchange bandwidth can reach 10Gbps during the training; storage access bandwidth can reach 100Gbps.
- The optimization of parameter tuning and iteration: parameters can be adjusted according to the training in the real time; resources occupied by the training can be monitored in the real time to easily configurate resources.
- Security: data can be kept within the data island with multiple copies of storage.
2. Challenges and Solutions of Building a Deep Learning Platform
In order to satisfy users’ ever-changing demands, the deep learning platform needs to continuously evolve and adapt itself to support different frameworks and algorithms. Thus, many challenges arise in the process of building and using a deep learning platform.
- Storage cannot meet the needs of deep training on the PB-level data volume, performance and scalability.
- Some data cannot be directly used in existing frameworks due to inconsistent formats or other factors, which leads to the time-consuming and inefficient process of conversion.
- It is difficult for existing deep learning frameworks to make full use of the computing power of multiple GPUs, so there is not always a positive correlation between the number of GPUs and training performance growth.
- It is hard to increase the training efficiency due to the complex training procedures and lack of unified integration scheduling. Nowadays, large-scale deep training platforms tend to extend data storage and computation separately and to overcome various challenges through the optimization of the training process.
2.1 Build a Deep Learning Platform Based on Cloud Storage to Equip the Storage System with Good Scalability
Deep learning requires far more data than traditional applications. Especially in the video training, not only video files but also large numbers of frame files are generated when captured during the training process. Although the local distributed storage cluster can support deep training in the scale of one hundred trillion byte, bottlenecks soon appear.
There are two main problems. First, when the volumn of data deep learning requires reaches the scale of PB-level, it is difficult for local distributed storage systems to meet the expansion needs. Second, because most of the training data come from the Internet, it is inefficient to turn them into local data. Meanwhile, the management of metadata is also a huge challenge. The best solution is to host full amount of data on the cloud. The problem in massive data storage can be solved by utilizing the large capacity and high scalability of object storage. At the same time, Alluxio, a high-efficient cache system, should be introduced to improve the reading performance by over 100%.
2.2 Provide Efficient and Convenient Dataset Management and Support Automatic Format Conversion
To increase training efficiency, many deep learning frameworks (such as MXNet, Pytorch, TensorFlow, etc.) have specific requirements on the format of input data. Since most of the deep learning data come from the Internet or object storage, they need to be converted into the format that the framework can recognize before use.
However, the traditional manual conversion is not only complicated, but also can cause a lot of errors. Therefore, in order to increase the efficiency of distributed training, some frameworks require direct access to data. It would be better to slice data into suitable fragments according to the access mode so that data can be stored nearby when accessed. The deep learning platform can provide comprehensive dataset management, automatically transform the format of input data, and increase the efficiency of data concurrent access.
2.3 Customize Computing Strategies to Increase GPU Efficiency
Although the performance of the GPU has been greatly improved, due to scarce GPU resources at present, the limited computing power restricts the deep training performance to a large extent. Therefore, to create a highefficient deep learning platform, suggestions below should be followed on improving the efficiency of GPU.
- Turn the GPU into a shared resource pool so that resources can fully flow and be shared by different users and in different trainings.
- Connect different GPUs in one machine to the same CPU through PCIE switches; or connect them through different CPUs. Different connections constitute different topologies. The platform needs to perceive the impact of the GPU's topological relationship on the performance, and avoid the use of inefficient GPU topology connections through customized scheduling strategies.
- Equip the platform with a distributed scheduling strategy and make full use of the advantages of multi-machine and multi-GPU so that the training speed maintains an approximate linear growth with the increase in the number of GPUs.
- Avoid introducing GPUs of different standards or models in building platforms. At present, the platform should avoid selecting GPUs of different models in one training and should select GPUs of different models for different trainings according to actual needs. Based on the above strategies, the customized computing platforms and different scheduling strategies can increase the GPU efficiency by over 40%.
2.4 Optimize Procedures to Increase Training Efficiency
A complete procedure for a deep training task is shown below:
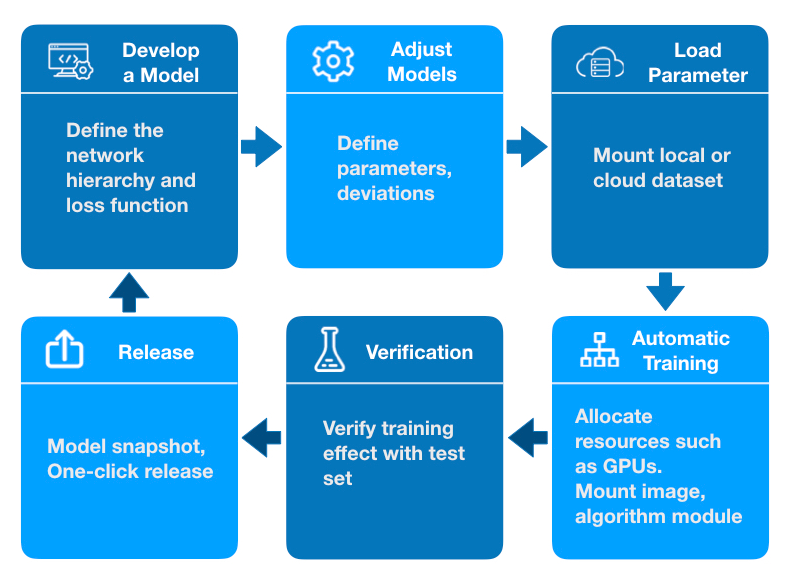
Source: Qiniu
Deep training requires repeated iterations to finally decide an ideal model. Each iteration training is performed manually by the user, which is complex and often goes wrong. The deep learning platform can quickly start a training with the use of graphics, and carry out the procedures of parameter tuning and iteration concurrently through automated, or semi-automated procedures to increase the training efficiency.
2.5 A High-performing Deep Learning Platform
In summary, it is inevitable to face various challenges in the deep training. However, if high-performing deep learning platforms are utilized, these challenges can be overcome singly. The following two actual cases demonstrate an overall comparison of users between before and after using the deep learning platform.
One research institute deploys the Qiniu Cloud AVA deep learning platform, and then the use of GPU transforms from exclusive mode to shared mode, which has greatly increased the GPU utilization. One image processing company initially deployed all their data in the cloud. During the training, data were accessed from the cloud, which was slow and generated much traffic costs. By deploying the AVA platform, most of the training data are cached in the local system, which has significantly improved the reading performance and meanwhile greatly reduced traffic costs.
With the overall comparison, the benefits of introducing the deep learning platform on the training effect is shown in the following chart:
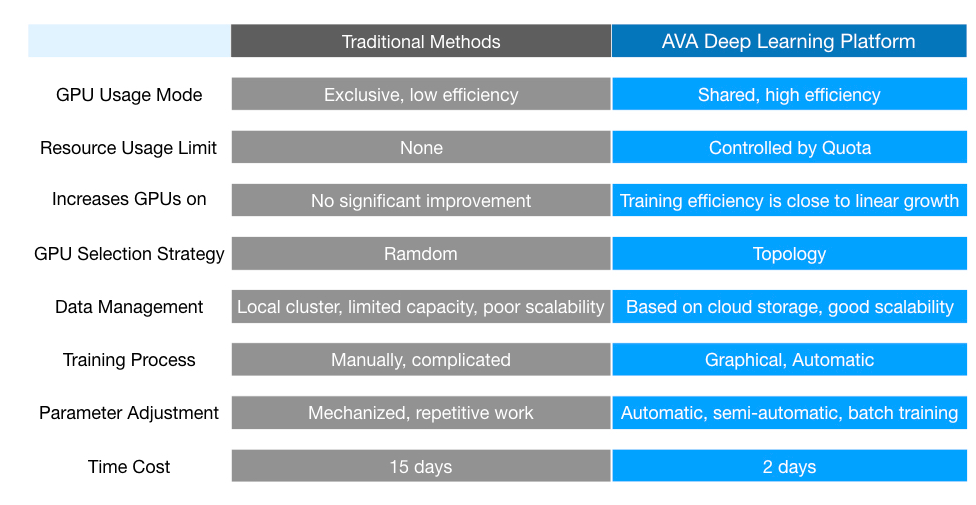
Source: Qiniu
3. Features and Advantages of the AVA Deep Learning Platform
The AVA Deep Learning Platform is built and greatly optimized based on general servers and standard open source components. It can be seen from the overall architecture diagram of the AVA platform below that storage and computing clusters are independently built and evolved. Because the storage is completely built in the cloud, it can be simultaneously connected to the object storage of various mainstream manufacturers to break the regional confinement in the training. And it is equipped with a local cache to meet the requirements of high performance and high scalability. The AVA deep learning platform uses Kubernetes to manage GPU clusters, makes full use of GPUs and increases the training speed with a customized scheduler and the Quota management framework.
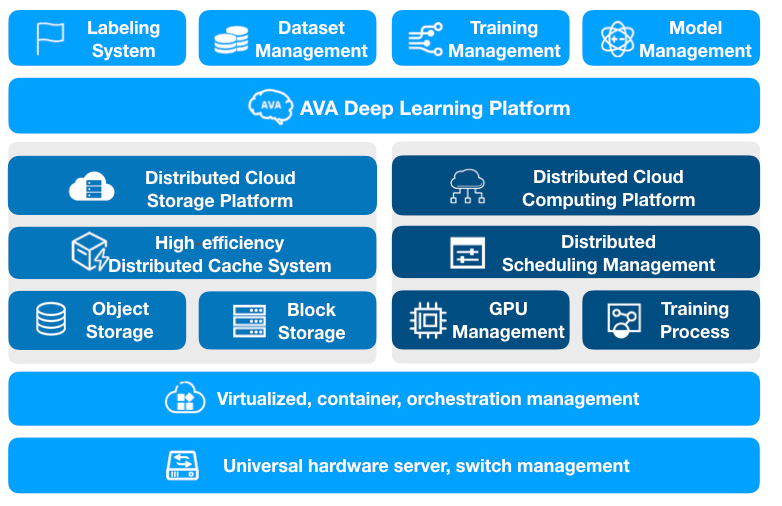
Source: Qiniu
3.1 Maximize GPU Utilization Through Resource Scheduling
The design of the scheduling algorithm has a crucial impact on the training speed and effect. In this regard, the following optimizations are made in the AVA platform:
- Select a GPU with Affinity When Scheduling Different GPUs are connected differently on one machine. GPUs connected to the same CPU and connected to each other through the PCIE-Switch has Affinity. The communication bandwidth between non-Affinity GPUs may only reach 3GB/s, while the bandwidth between Affinity GPUs can reach up to 12GB/s. Therefore, the AVA Deep Learning Platform takes the difference into account when scheduling GPUs, and always prefers GPUs in the same Affinity state.
- Adopt the equalized or centralized scheduling mode through configuration, and adopt the centralized scheduling mode as default
Kubernetes adopts the default scheduling strategy of equalized scheduling, which can equally distribute the training to different machines to achieve load balance. However, this scheduling strategy cannot be applied in certain training scenarios. For example, when some algorithms need to use as many GPUs as possible on the same machine for training, if equalized scheduling is adopted, the total number of GPUs will meet the requirements, but the single machine cannot meet the training demand.
In addition, communication may be required between different training tasks. The communication efficiency between two training tasks on one machine is significantly higher than that on two different machines. With the assigned strategy, AVA can adopt different scheduling methods to meet different training needs.
3.2 Easy to Install, Integrate and Use
All services on the AVA platform are built based on Docker and Kubernetes and provided through Docker image and Yaml script deployed by Kubernetes. The AVA platform can be deployed in both public and private clouds. The AVA platform can dock common standard components of public clouds, and the deployment and debugging can be finished in one day. Even in a more complex private cloud environment, the deployment and debugging can be finished in two to three days.
The integration of the AVA platform is improved since all services are offered by APIs. Users can create datasets, initiate trainings and release training models through APIs. In addition, the upper-layer business can be also directly joined to the platform through APIs and make full use of platform resources and features.
The primary goal of the AVA platform is to remove users from caring about the underlying implementation details. The second is to quickly start a deep learning training and provide the following management functions:
- Basic image management: the images the AVA platform provides include most of mature frameworks, such as MXNet, Caffe, Pytorch and Tensorflow, and CUDA drivers are pre-installed. Users only need to select the image when starting a training, avoiding the process of building an image and installing the driver.
- Dataset management: different training frameworks have certain requirements on the input data format, and input images and other files need to be pre-processed like cutting, rotating, etc in some trainings. It will be complex if these operations are carried out manually. The AVA platform provides a one-click service. Through specifying a list of input files and preprocessing operations, the platform will generate files with the unified format the training framework needs for the deep training. Users can also share the data with other users to avoid repeating setup procedures.
- Training management: users can start a training only by deciding the type and quantity of the GPU on the platform, and assigning the dataset and the image. The whole process only takes ten seconds, which reduces the time cost for the training.
- Resource management: all the GPUs and CPUs for the training are managed and scheduled by the platform. When an old machine moves out of the platform or a new machine joins in the platform, you can use the new machine right after simple configuration.
- More functions
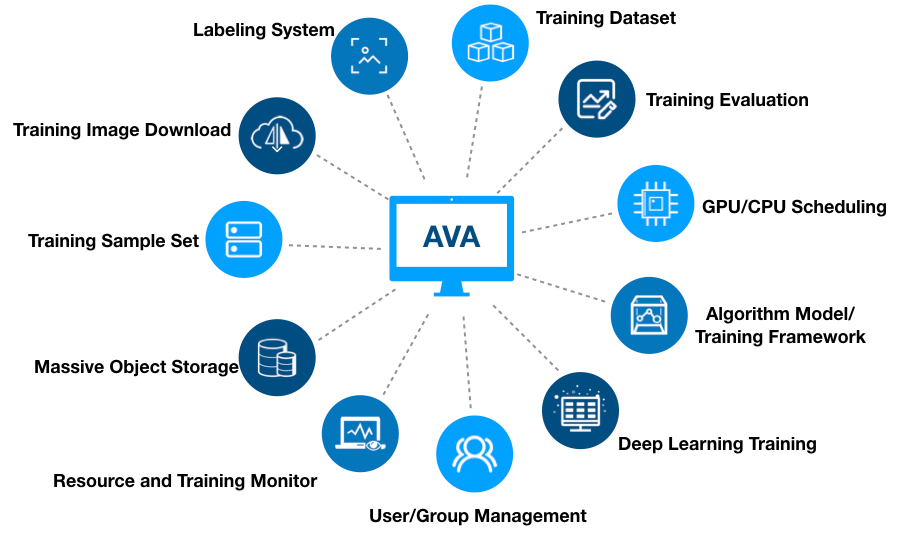
Source: Qiniu
3.3 Flexible to Deploy in Both Public and Private Clouds
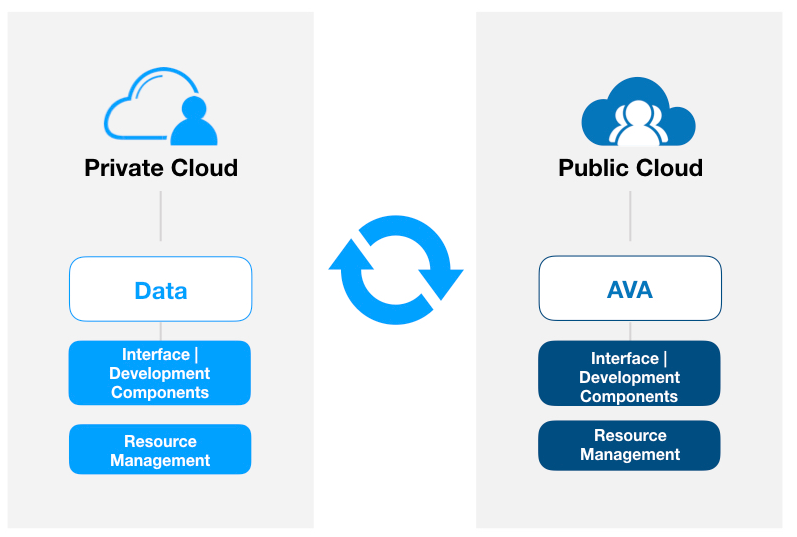
Source: Qiniu
The AVA platform is flexible enough to be deployed in a private or public cloud environment. So, the data or services won't be restricted to a single service provider. After users complete the deployment, they can easily move from the public cloud to the private cloud, and vice versa. For industries with sensitive data, users can deploy the AVA platform to the private storage system and the training can be conducted within the data island. In addition, the training platform and data can be deployed separately. Data stored in AWS or Azure can be trained on the AVA platform without data migration.
3.4 Efficient Management of Parameter Tuning and Iteration
The choice of parameters also poses an important influence in the deep training effect. To obtain a precise model, deep training requires repeated supervision of training accuracy and the loss rate, and then constantly adjusts parameters such as model hierarchy, learning rate, etc. The AVA platform can integrate the training process, use efficient searching and sorting algorithms, and automatically or semi-automatically select network models and combine different training parameters according to predefined rules, in order to conduct deep training in batches.
By comparing the results of the training, the platform can automatically sort the models in order. According to the recommended results by the platform, trainers can readjust the parameters, and then carry out the next batch of deep training until a satisfactory model is found. Platform-assisted semiautomated or automated deep training significantly increases the training efficiency.
4. Industry Value from Applications Based on the AVA Deep Learning Platform
It can be seen that, with the AVA deep learning platform, algorithm engineers are able to conduct lots of difficult trainings in a short time and apply them into production in real life.
4.1 Accelerator of Content Security Regulation – Dispose Images in Billions Per Day
With the robust development of online live broadcasting and short videos, contents are updated in the scale of 100 million on a single platform per day. Besides the data explosion, we should also pay attention to contents against regulations. In April 2018, 8.765 million valid cases are reported online to the authorities nationally, with 72.4% increase compared to last month and 200% increase to last year. 63 thousand of them are reported to the China Internet Illegal Information Reporting Centre, with 46.7% increase compared to last month and 11.5% increase to last year. If companies are to recognize contents with pornography, violation, terrorism, or politically sensitive topics completely by humans, it will additionally expend vast amounts of human and materials resources and management costs.
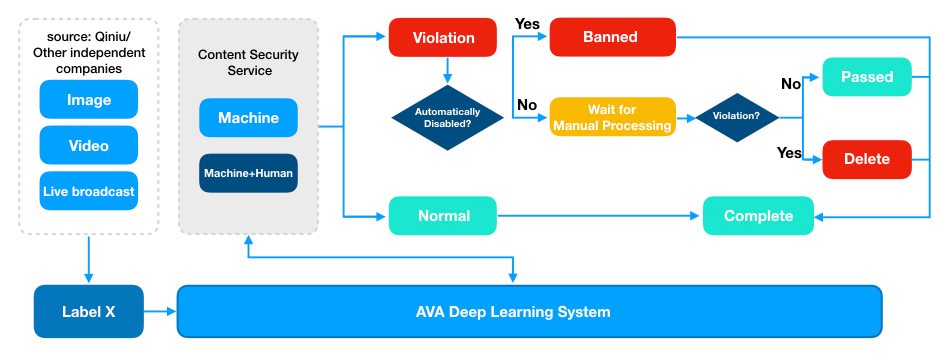
Source: Qiniu
In the training process, the AVA platform offers Label X, a data preprocessing platform where the standard data set capable of being put into training is available with marks by marking engineers or existing dataset downloaded from outside links. Thus, algorithm engineers can focus themselves on developing algorithms more efficiently.
In addition, the AVA also provides a hosting platform for algorithm engineers to run algorithms related to deep learning, watch training monitoring, find out and solve bugs, optimize models and improve accuracy. In the past, each person can only check hundreds of images per day. However, with the AVA deep learning platform, there is an exponential increase in the efficiency of this application. The daily deposal of images and videos can reach the scale of one billion and deposal results can be responded in milliseconds.
4.2 Full Upgrade of Intelligent Cities – Operate Highefficiently and Cooperate Among Departments in Seconds
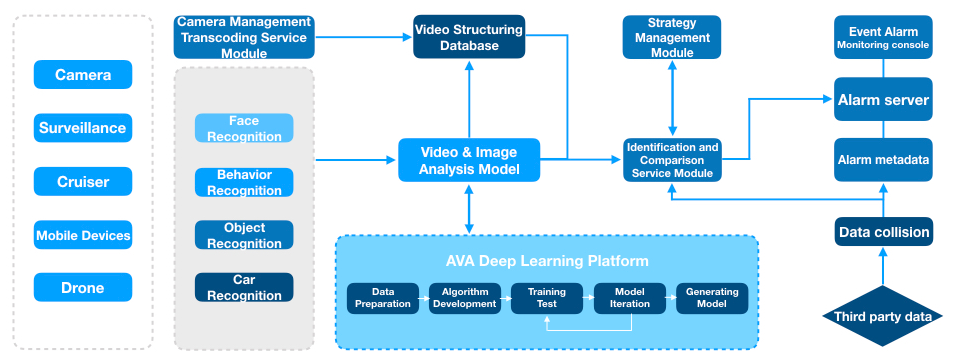
Source: Qiniu
A highly-developing city needs excellent operation and management. It becomes a difficult problem for densely-populated cities to guarantee security in public areas. With the monitoring at key crossroads, the current city monitoring system can monitor the number and density of population at entrances and exits day and night, and produce daily trend charts and heat maps of population distribution. During holidays, the tracking technology can assist with warnings of people gathering and quick evacuation.
Large amounts of construction trash causes serious pollution. Computer vision can be used to solve the problem and other problems like speeding, occupying roads and throwing trash along the road of construction trucks. Cameras of traffic control can be used to recognize trucks violating laws and intelligently give warnings of their misdeeds. The monitoring system for construction trash of “excavation-transportation-backfilling” can be formed to significantly improve the efficiency and effect of construction trash control. The AI model, based on the powerful GPU cluster calculation and outstanding deep learning algorithms, can conduct quick iteration on the AVA platform and keep upgrading according to users’ feedback. Guaranteeing data security by private deployment is needed in operating and managing a city.
4.3 Powerful Support of Intelligent Radio and Television – Save Manpower Dramatically and Allocate Resources Properly
Massive data are stored in the radio and television domain. The VOD hour in a single channel can add up to the scale of one million annually. Besides, as the news is time-sensitive, data with seemingly low value density are actually of great social value if utilized effectively.
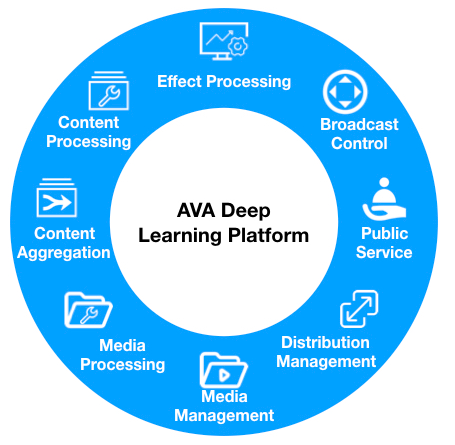
Source: Qiniu
For example, feature tags can be added to one certain figure captured in the video to generate the video album of that figure automatically. Later, if users input keywords, the system can find all clips about that figure for users to retrieve, delete and download. Users no longer need to expend large amounts of manpower to search the whole lengthy video for a short clip and are less dependent on senior scriptwriter. In addition to figure recognition, other functions like scenario recognition, information orientation and video database management can all help the upgrade in the radio and television domain.
The current cloud broadcasting and control as well as cloud media resources, respectively for live scenarios and VOD scenarios, are both based on deep learning. Combined with the AVA, the efficiency of live scheduling and interaction increases by 50% with the 20% reduction of manpower. The efficiency of media resource management increases by 30% with the 50% reduction of manpower. An outstanding deep learning platform is like a stable foundation, with which “bricks” like target segmentation, feature study, dynamic regression, sequential analysis and targeted angle unification can be piled up to carefully operate business.
4.4 The Era of AI for Everyone
In the domain of medical treatment, researchers have been making use of big data and deep learning technology to discover new viruses in the past few years. In medical imaging, tumors, cancers, pathological changes or nodules can be found through examinations. Models can be established with the help of the AVA deep learning platform and optimized with massive medical data training. Artificial nerve cells can reach the scale of 100 million, and synapses can reach the scale of 100 billion, which helps simulate the subtle process of neural activities in figure recognition in the high visual cortex in one second and eventually assists doctors in making appropriate judgments and effective decisions accordingly.
In the domain of traffic control, with the help of OCR, license plates can be monitored dynamically in the real time and roads can be planned in a dynamic way in the rush hour, to alleviate traffic pressure. Monitoring with multiple terminals integrated with hardware can remind drivers of driving properly and safely as well as help find hit-and-run drivers. Traffic control combined with deep learning enables the number of traffic accidents, deaths and the injured to decrease by 25%-35%.
In the domain of logistics, road conditions in cities vary greatly, which makes it impossible for trucks of different height or load to drive completely according to the GPS. However, AI applications combined with the AVA can schedule routes in the real time to save transportation time and average fuel consumption, with the 10%-25% reduction of transportation costs. Besides, the sorting system with machine intelligence can replace humans to scan and input order codes and recognize destination addresses with character recognition. Scanning and inputting information can be finished within 10 seconds, reducing 90% time of couriers.
In the domain of education, teachers scoring examination papers need to score hundreds of compositions in one morning. Due to factors like fatigue, manual scoring can probably generate omission. But with the accurate character recognition, the scoring of one piece of writing can be finished in only one second, and at the same time the piece of writing will be compared with other writings from the same province or even nationwide and checked in terms of plagiarism to find papers with high similarity, which transforms the previous scoring pattern.
5. Summary
We can conclude that deep learning has great value and vast development prospects at present. Besides the applications mentioned above, we can achieve more: combined with VR, AR can be applied in more business scenarios like inspecting houses or playing games, or be used to help develop industrial robots in different domains; applications will be increasingly mature in household assistance, text translation, intelligent Q&A, unmanned driving, aeronautics and astronautics as well as military machines. When people apply, the key to the success of products lies in the algorithm optimization with the full use of the deep learning platform. The technology of deep learning stands for the future trend, and it is now a must and the best choice for us to choose an outstanding deep learning platform.
Source: Qiniu
