A Complete Practical Guide of Deep Learning Platform
Research from Gartner
Market Guide for Machine Learning Compute Infrastructures
Devising compute strategies for AI applications can be challenging as it involves navigating complex design considerations. I&O leaders can use this research to deliver highly efficient infrastructures for compute-intensive machine learning and deep neural network-based applications.
Overview
This annually updated document contains the forecast market model or methodology and explains the market dynamics and foundational assumptions that underpin our understanding and analysis of the market.
Key Findings
- The vendor landscape for ML compute infrastructure is fragmented and rapidly changing, making it tough for enterprises to navigate the market and filter the vendor marketing obfuscations.
- The number of accelerators per node varies greatly across vendors, creating challenges for end users to architect ML compute infrastructures that can efficiently scale.
- Integrating diverse system software components including libraries, drivers, and diverse ML and DNN frameworks can be complex and time-consuming, and require additional skills.
Recommendations
I&O leaders looking to accelerate infrastructure innovation and enable agility by delivering high-productivity infrastructure for AI workloads should:
- Use multidimensional ML compute infrastructure selection criteria by including speed of execution (data preparation and model training), broad DNN framework support and ability to simplify integration with other enterprise infrastructures.
- Select products that offer the highest density of accelerators per node and support high-bandwidth, low-latency networks (such as InfiniBand) to deliver the scalability and performance SLAs that AI applications require.
- Simplify infrastructure management and enhance portability by selecting solutions that support and enable container images for a wide range of DNN frameworks.
Strategic Planning Assumption
By 2023, nearly 15% of enterprises will be developing DNN training and inference ecosystems, up from less than 3% today.
Market Definition
This document was revised on 27 September 2018. The document you are viewing is the corrected version. For more information, see the Corrections page on gartner.com.
This market is characterized by hardware-accelerated, high-performance compute platforms that host integrated accelerator technologies like graphics processing units (GPUs) or custom processors. Machine learning (ML) compute infrastructures feature accelerated computing systems designed to speed up compute-intensive statistical machine learning and deep neural networks. As a result, ML compute infrastructures require optimized and preintegrated middleware stacks including ML and DNN frameworks, along with libraries and operating systems that are preconfigured to easily harness the advanced compute capabilities. To minimize the scale and complexity of coverage, this Market Guide is limited to the training stage of AI pipelines and does not address the inference stage.
For cloud-hosted ML IaaS that provides similar capabilities, see “Market Guide: Machine Learning Infrastructure as a Service.” For data science and machine learning platforms that feature software frameworks and systems, see “Magic Quadrant for Data Science and Machine-Learning Platforms.”
Market Description
Enabling successful artificial intelligence (AI) initiatives requires effective ML and DNN pipelines. These pipelines commonly feature five key stages (see Figure 1):
- Data source access and aggregation
- Data cleanup and preparation
- Model training and validation
- Model deployment
- Accuracy monitoring and retraining
Figure 1. Key Stages in Compute-Intensive ML and DNN Workloads
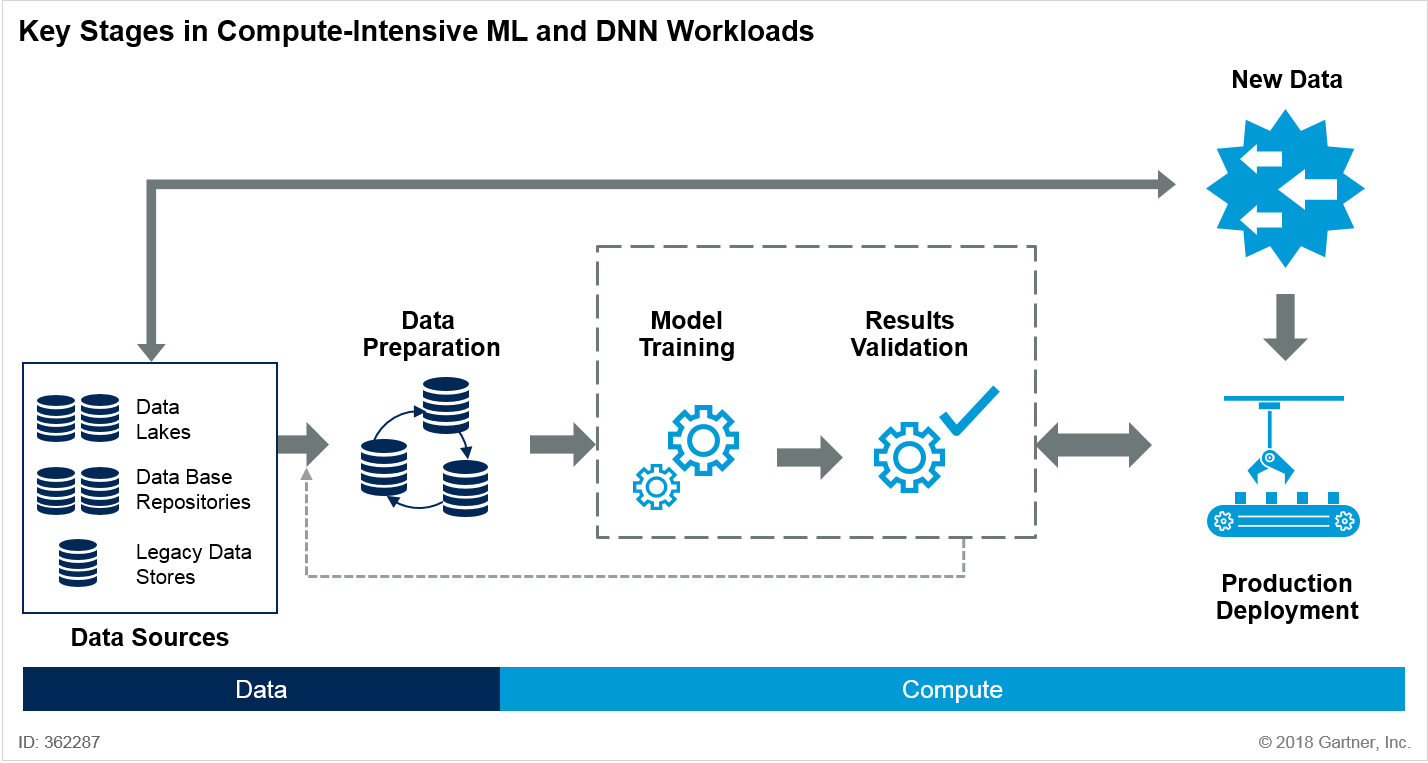
Source: Gartner (September 2018)
This Market Guide focuses on ML and DNN compute infrastructures (highlighted in the dotted-line box in Figure 1) for the model training and results validation stage as it is the most compute-intensive.
The model training and results validation stage involves heuristics and numerical optimization techniques such as back propagation and gradient decent that are compute- and data-intensive. The heuristics involved can be broadly classified into two broad categories:
- Statistical machine learning
- Compute-intensive ML and deep neural networks
Statistical machine learning heuristics comprising techniques such as support vector machines (SVM), clustering and random forest often require small datasets, and from a compute resource perspective can utilize existing compute platforms (either on-premises, in the cloud or hybrid). Efficiently executing statistical machine learning-based techniques often does not require new compute hardware ecosystems like GPUs or custom chipsets (application-specific integrated circuits [ASICs]).
Compute-intensive ML and deep neural networks require large-scale training datasets. These heuristics are usually executed in the data center using compute systems accelerated with technologies such as GPUs and ASICs, complemented with high-bandwidth, low-latency networking infrastructures. In addition to specialized hardware, these techniques also require an optimally integrated middleware and systems software.
This Market Guide focuses on the training stage of AI pipelines. This research doesn’t cover the inference stage of AI pipelines. This is because the inference stage often features diverse processors (field-programmable gate arrays [FPGAs], ASICs, GPUs and CPUs) and different deployment models (data center, cloud, edge or IoT environment). Therefore, including coverage of the inference stage of the pipeline would dramatically increase the scope and complexity of the Market Guide. In 2019, potentially, we plan to develop a Market Guide focused on the inference stage of AI pipelines.
Market Direction
Early adopters in AI, especially digital natives, are actively integrating AI capabilities including highly specialized DNN models and have demonstrable early-mover advantages. Beyond digital-native environments, many leading organizations across diverse industries (including healthcare, retail, insurance, energy and manufacturing) are actively piloting DNN-based AI initiatives. For instance, financial services and payment processing companies are using DNN techniques to accurately detect fraudulent transactions and insider trading, and perform market sentiment analysis. Healthcare organizations are using compute-intensive ML and DNNs for MRI/radiology image analysis to aid diagnostics. However, a vast majority of organizations are in the very early stages of defining their AI initiatives (see Figure 2).
Figure 2. Current State of AI Strategic Planning and Deployment
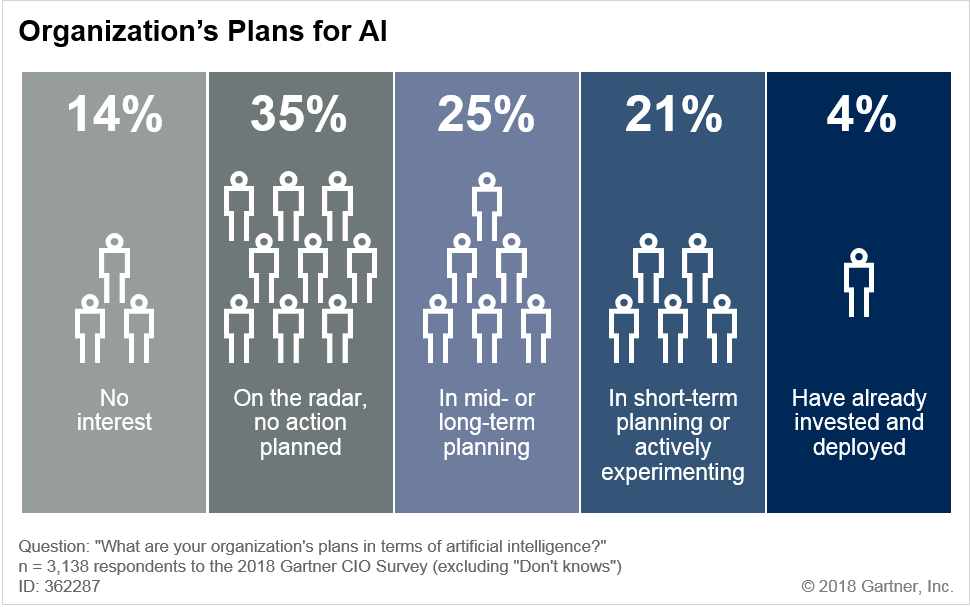
Source: Gartner (September 2018)
Due to various factors including total cost of ownership (TCO), data gravity, ease of use and lack of data scientists across end users, a majority of organizations leverage on-premises ecosystems for building machine learning models. In a recent Gartner survey, end users cited that nearly 57% (mean summary) of their ML models are developed on-premises (see Figure 3).
In this context, ongoing infrastructure investments will be influenced by five market forces:
- Evolution in standards, frameworks, languages and APIs
- New deep neural network models and evolving state-of-the-art in ML models
- New and expanded use cases from the business
- Growth of data and new data sources
- Availability of specialized data science and system design skills
- Cost changes in the technologies
- New technologies and system architectures
The ability to customize systems infrastructures and adapt on-premises data ecosystems, and the ability to deliver TCO-optimized compute infrastructures are making ML compute infrastructures attractive platforms for running AI workloads. For I&O leaders evaluating on-premises versus cloud or machine learning infrastructures, please see “Use This Decision Framework to Determine If Machine Learning Should Run in the Cloud.”
Figure 3. Machine Learning Current Adoption – On-Premises vs. in the Cloud
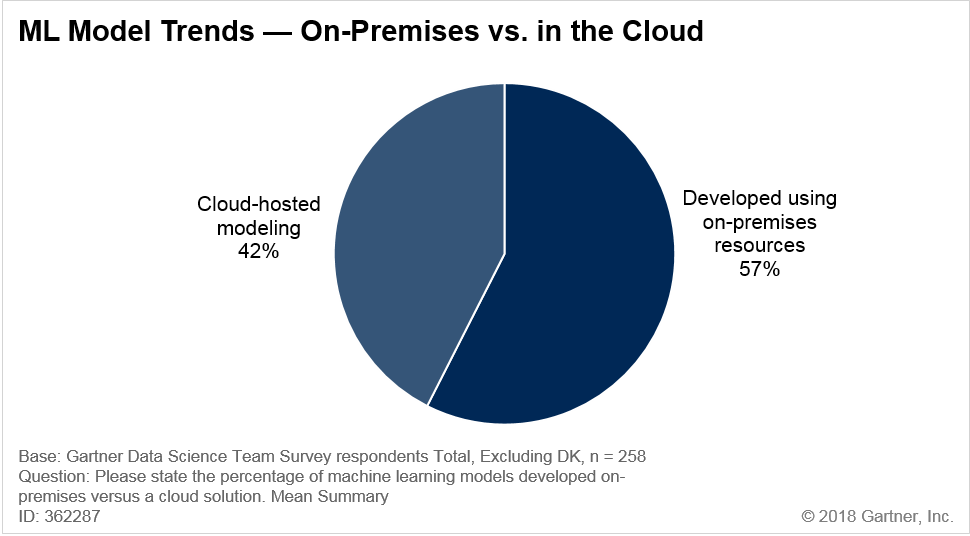
Source: Gartner (September 2018)
Market Analysis
ML compute infrastructures (as defined in this Market Guide) are primarily catered toward organizations looking to build infrastructure stacks on-premises. The following six core capabilities are needed in ML compute infrastructures to enable high-productivity AI pipelines involving compute-intensive ML and DNN models.
Compute Acceleration Technologies
Compute acceleration technologies such as GPUs and ASICs can dramatically reduce training and inference time in AI workloads involving compute-intensive ML techniques and DNNs. Accelerators should be picked to match application needs, and frameworks must be configured for those specific accelerators to use their capabilities. While there are diverse accelerator technologies in this market including NEC Aurora Vector Engine, AMD GPUs and NVIDIA GPUs, only a few of them have wide support for ML and DNN frameworks. Currently, the DNN training ecosystem is dominated by NVIDIA GPUs because of two key factors:
- High-performance hardware that utilizes unique capabilities such as tensor cores and NVLink
- A high degree of software integration all the way from libraries to frameworks
As a result, most of the commodity solutions in the market feature compute systems that are accelerated using NVIDIA GPUs.
Improve productivity of your ML compute infrastructures by selecting accelerator technologies that deliver the highest compute-intensive ML/DNN training performance and offer the broadest preoptimized middleware framework support.
Accelerator Density
Compute-intensive ML and DNN frameworks are scale-up-oriented. A higher number of accelerators in each compute node can dramatically reduce training times for large DNNs. Compute platforms addressing this market feature a high degree of variance in accelerator densities. Most vendors support four accelerators per compute node, while performance-oriented configurations feature eight accelerators per compute node. In GPU-accelerated compute systems, some vendors offer 16 GPU compute nodes.
While the most common approach to scaling in compute-intensive ML and DNN frameworks tends to be scale-up-oriented, early adopters are also curating scale-out strategies. Uber’s Horovod enables distributed deep learning for DNN frameworks like TensorFlow and PyTorch. IBM’s Distributed Deep Learning and Elastic Distributed Training are also designed to deliver scale-out capability when model size and complexity grow. NVIDIA’s NCCL communication libraries also enable multi-GPU and multi-node scaling foundations for DNN frameworks. When selecting scale-out strategies, make sure to select solutions that are preoptimized, easy-to-deploy and minimize TCO.
Enable high-performance ML compute infrastructures by selecting solutions that offer the highest density of accelerators as required by your current and emergent problem sizes.
High-Speed Compute Interconnect
Because of the high density of accelerators, the manner in which the accelerators are connected to the compute node and how the compute node components interplay with accelerators can dramatically impact performance in compute-intensive ML- and DNN-based workloads. Within ML compute infrastructures, two types of data movement operations commonly occur:
- Data ingest and copy operations to load input data — These operations are data movement-intensive and usually require direct involvement of the CPU. As a result, high-bandwidth data movement bus architectures between the CPU and the accelerators are crucial to prevent data bottlenecks. x86-based compute systems utilize PCIe Gen3 (PCIe 3.0)-based connectivity between CPUs and GPUs. The IBM POWER processor natively supports NVIDIA NVLink, which enables higher bandwidth connectivity than PCIe 3.0 interconnects. As a result, systems featuring CPUs with native NVLink support can deliver high-bandwidth connectivity between the base CPU and NVIDIA GPUs.
- Data exchange between the compute accelerators during the training phase – These operations usually happen between accelerators, and, as a result, DNN training times depend on how accelerators are interconnected. In ASIC and GPU-accelerated systems, pooling of the accelerators commonly occurs via PCIe 3.0. However, NVIDIA GPU-accelerated systems can also utilize NVIDIA’s SXM, which enables GPUs to leverage NVIDIA’s NVLink interconnect technology and consequently can enable higher bandwidth data exchange across GPUs within a compute node.
Systems utilizing PCIe 3.0-based connectivity between GPUs can easily be added-in or user- customizable. When desired, I&O leaders can add-in the necessary GPU cards easily. Systems relying on SXM-based connectivity across GPUs are mainly delivered in preintegrated form factors, which in some cases impose challenges in changing the densities.
Pick systems that feature high-bandwidth interfaces between compute-intensive processors (GPUs and, in some cases, CPUs) to dramatically reduce training times.
Network Connectivity
Large-scale, compute-intensive ML and DNN techniques require fast movement of large amounts of data across compute nodes. High-bandwidth, low-latency networking technologies that interconnect compute nodes can accelerate data movement and can enable some DNN models to scale. From a networking perspective, DNN processing compute environments rely on two key capabilities:
- High-bandwidth and low-latency pooling of GPU resources
- GPUDirect remote direct memory access (RDMA) capabilities
Utilizing RDMA-compatible networking stacks enables accelerators to bypass the CPU complex and, as a result, enables high-performance data exchange between accelerator components. Four interconnect technologies that are used in practice today include:
- InfiniBand (Mellanox)
- Ethernet (with RoCE v.1/2)
- Intel Omni-Path
- Proprietary network technologies
High-performance hyperscale environments for DNN and ML often feature InfiniBand interconnects.
Architect for high-performance scalability by selecting network architectures that feature high-bandwidth, low-latency cross-node connectivity and pooling of cross-node GPU (and possibly ASIC) resources via RDMA-like capabilities.
Local Storage
Most DNN and computationally intensive ML workloads are also inherently data-intensive. The data ingest stage, where the training dataset is loaded into GPU memories, tends to be read-intensive. Additionally, the training stage requires a large volume of random small-file input/output (IO) operations. As a result, most ML compute infrastructures prefer to use solid-state drive (SSD)/flash to accelerate random small-file I/O operations. This enables the systems to move data efficiently within a compute node and minimize data-access-related bottlenecks.
Minimize data access bottlenecks in your architecture by selecting ML compute infrastructures optimized for high-throughput small random read operations.
ML and DNN Frameworks
ML and DNN frameworks deployed on accelerated compute platforms need to be reconfigured with the right set of libraries and supporting middleware technologies to enable utilization of accelerators. Integrating these technologies from scratch can be incredibly complex and resource-intensive for enterprise organizations. Most system vendors provide preoptimized DNN and ML framework containers (such as TensorFlow, Caffe, PyTorch, Spark and H2O.ai) to minimize deployment and integration time. Some of these include:
- NVIDIA GPU Cloud (NGC) – Free and compatible with NVIDIA GPU-accelerated platforms. Only NVIDIA’s compute systems (DGX1, DGX2) and some public cloud ecosystems powered by NVIDIA GPUs are certified and extensively supported. NGC features Horovod for distributed deep learning. NGC can be deployed on most NVIDIA GPU-accelerated systems. NGC containers also run in Kubernetes-orchestrated environments.
- Bright Cluster Manager for Data Science (BCMDS) – Compatible with NVIDIA GPU platforms and widely offered by most system vendors, BCMDS also supports Horovod for distributed deep learning. From an operating expenditure (opex) perspective, this capability is mostly offered as an add-on, and I&O leaders should evaluate any associated licensing costs over the lifetime of the systems.
- IBM PowerAI Enterprise – Currently only available for IBM Power Systems, PowerAI Enterprise offers preoptimized stacks of open-source AI frameworks, integrated support for distributed deep learning and data scientist productivity tools. These tools span the entire model development process, from data ingest to inference deployment. While some features are free, enterprise-scale usage and support may require additional licenses, and consequently I&O leaders should evaluate any associated licensing costs required for their ecosystem.
- Lenovo intelligent Computing Orchestration (LiCO) – The Lenovo-exclusive LiCO is a software solution designed to provide simple cluster management and to improve use of infrastructure for AI model development at scale on both NVIDIA and Intel processors. While LiCO is free to use, support offerings for LiCO are enabled through a per-CPU and per-GPU subscription and support model, and consequently I&O leaders should evaluate any additional licensing costs.
When devising ML and DNN infrastructure strategies, ensure the vendor-provisioned container ecosystem supports the core subset of ML and DNN frameworks used in your organization.
Select ecosystems that provide the ability to test the latest GitHub versions alongside stable versions for iterative A/B testing. DNN and ML frameworks are continuously improving, and the latest GitHub versions can address key challenges that stable versions might not yet address. Finally, take into account the opex associated with middleware management and optimize the TCO to your organizational context.
Representative Vendors
The 13 vendors listed in this Market Guide do not imply an exhaustive list. This section is intended to provide more understanding of the market and its offerings. We have assessed each vendor using a template of six standardized content groups (see Note 1 for additional details).
Market Introduction
Table 1 gives an overview of the providers included in this Market Guide that offer ML compute infrastructures.
Table 1. Representative Vendors in ML Compute Infrastructures
| Vendor | Product, Service or Solution Name | Base Processor | Maximum Accelerator Family and Density | Accelerator Form Factor | Network | Operating System |
|---|---|---|---|---|---|---|
| Atos | BullSequana X410 E5 |
|
|
|
|
|
| BullSequana X450 E5 |
|
|
|
|
|
|
| BullSequana S X800 |
|
|
|
|
|
|
| BullSequana X1115 blade |
|
|
|
|
|
|
| Cisco | UCS C480 ML M5 Rack |
|
|
|
|
|
| UCS C480 M5 Rack |
|
|
|
|
|
|
| UCS C240 M5 Rack |
|
|
|
|
|
|
| HyperFlex HX240c M5 Node |
|
|
|
|
|
|
| Cray | CS-Storm 500GT |
|
|
|
|
|
| CS-Storm 500NX |
|
|
|
|
|
|
| CS500 |
|
|
|
|
|
|
| XC50 |
|
|
|
|
|
|
| Dell EMC | PowerEdge C4140 |
|
|
|
|
|
| PowerEdge R740 and R740xd |
|
|
|
|
|
|
| PowerEdge R940xa |
|
|
|
|
|
|
| Fujitsu | PRIMERGY CX400 M4 (2x CX2570 M4) |
|
|
|
|
|
| PRIMERGY RX2540 M4 |
|
|
|
|
|
|
| Zinrai Deep Learning System |
|
|
|
|
|
|
| Hewlett Packard Enterprise | HPE Apollo 6500 (XL270d Gen10) |
|
|
|
|
|
| HPE Apollo 6500 (XL270d Gen9) |
|
|
|
|
|
|
| HPE Apollo sx40 |
|
|
|
|
|
|
| HPE Apollo 2000 Gen10 (XL190r Gen10) |
|
|
|
|
|
|
| HPE ProLiant DL380 Gen10 |
|
|
|
|
|
|
| HPE ProLiant DL580 Gen10 |
|
|
|
|
|
|
| HPE ProLiant DL380 Gen9 |
|
|
|
|
|
|
| HPE Superdome Flex Server |
|
|
|
|
|
|
| HPE SGI 8600 (XA780i Gen 10) |
|
|
|
|
|
|
| Huawei | G560 |
|
|
|
|
|
| G560 V5 |
|
|
|
|
|
|
| G530 V5 |
|
|
|
|
|
|
| IBM | AC922 Newell |
|
|
|
|
|
| Inspur | NF5288M5 (AGX-2) |
|
|
|
|
|
| Lenovo | SD530/D2 |
|
|
|
|
|
| SR670 |
|
|
|
|
|
|
| SR650 |
|
|
|
|
|
|
| NEC | SX-Aurora TSUBASA A100-1 |
|
|
|
|
|
| SX-Aurora TSUBASA A300-2 |
|
|
|
|
|
|
| SX-Aurora TSUBASA A300-4 |
|
|
|
|
|
|
| SX-Aurora TSUBASA A300-8 |
|
|
|
|
|
|
| SX-Aurora TSUBASA A500-64 |
|
|
|
|
|
|
| NVIDIA | DGX-1 |
|
|
|
|
|
| DGX-2 |
|
|
|
|
|
|
| Sugon | W780-G20 |
|
|
|
|
|
* System supports addition of InfiniBand EDR if users prefer this type of a network.< br /> Source: Gartner (September 2018)
Vendor Profiles
Atos
Atos has a broad portfolio of compute platforms designed to accelerate AI training workloads. The BullSequana S and X series of servers include diverse form factors making them easy to integrate in diverse data center environments. From a systems perspective, Atos also has a reseller agreement with NVIDIA, enabling Atos to resell the NVIDIA DGX-1 system. The DGX-1 system can host up to eight of the latest NVIDIA Tesla V100 GPUs, supported by two Intel Xeon Processor E5 CPUs.
Atos has engineered an innovative Atos Codex AI Suite, an application toolset designed to deliver tools to scope, develop, deploy and manage AI applications. The suite includes four tools: Orchestrator for fast application development across multiple environments, Forge for a collaborative workspace for data scientists, Studio for an AI application development environment and DL Engine for a high-level API.
Cisco
Cisco has engineered a high-performance compute platform targeted to AI use cases across a broad range of industries. Cisco has partnered with key middleware providers to curate an AI middleware stack designed to simplify and accelerate all stages of an AI pipeline including data ingest, cleanup and preparation, training, and deployment.
In the data center, Cisco is expanding its relationship with big data ecosystems. For example, Cisco already has a blueprint (Cisco Validated Design) that incorporates Cloudera Data Science Workbench, enabling customers to run deep learning frameworks, such as Google’s TensorFlow, to access data lakes on the Hadoop Distributed File System (HDFS). Cisco is also partnering with Hortonworks 3.1 to schedule dockerized TensorFlow on a Hadoop cluster capable of scheduling not only the CPU but also GPUs. Cisco is also contributing code to the Google Kubeflow open-source project, where TensorFlow is being integrated with Kubernetes. Kubeflow enables an enterprise to have consistent machine learning tools on-premises and in the cloud, enabling a hybrid cloud architecture, even for machine learning.
With the UCS C240, Cisco is targeting the test/development, prototyping and model deployment ecosystems, while the Cisco UCS C480 and UCS C480 ML are designed to accelerate model training pipelines.
Cray
Leveraging its expertise as an industry pioneer in high-performance computing, Cray has devised an innovative product line. It includes the Cray XC50 supercomputer, the CS500 cluster supercomputer and the Cray CS-Storm GPU-accelerated cluster supercomputer (comprising CS-Storm 500GT and CS-Storm 500NX). These systems are designed to deliver high performance for scale-up deep learning workloads while enabling high-throughput scale-out capabilities where needed.
Cray provides the Urika-CS AI & Analytics suites (Urika-XC and Urika-CS) for data science. These suites include an optimized distributed training framework for deep learning training at scale, visualization and access (Jupyter Notebooks, TensorBoard), frameworks (TensorFlow, BigDL, PyTorch, Keras), and a diverse set of analytics tools for data preparation and machine learning (Apache Spark, Anaconda Python).
Cray’s Accel AI provides reference configurations that help users integrate Cray CS series solutions, storage ecosystems and the Urika-CS AI suite to simplify architecture and deployment of high-productivity systems across industries and use cases.
Dell EMC
Dell EMC PowerEdge servers are designed to address a wide range of use cases and deployment modalities. The company’s strategy in this market is to devise a scale-out-friendly compute platform. Dell EMC’s hardware portfolio for AI includes Dell EMC PowerEdge servers, networking and optionally Dell EMC Isilon Storage. Dell EMC has partnered with Bright Computing to offer its software stack on Dell EMC hardware in a portfolio of Ready Solutions configurations for multiple use cases. Using this combination, users can simplify deployment of system software and deploy preintegrated containerized frameworks.>
Dell EMC Ready Solutions for AI combine the middleware components needed to deliver productivity in enterprise AI initiatives. For deep learning with GPU acceleration, solutions include Bright Cluster Manager for Linux cluster provisioning and management, and the Dell EMC Data Science Provisioning Portal for data scientist workspace provisioning. Deep learning libraries and frameworks include Caffe2, Apache MXNet, TensorFlow, NVIDIA CUDA Deep Neural Network Library (cuDNN) and NVIDIA CUDA basic linear algebra subroutines (cuBLAS). Ready Solutions for AI’s design for machine learning with Hadoop includes Cloudera Enterprise Data Hub, Apache Spark, Cloudera Data Science Workbench and Dell EMC Data Science Provisioning Engine. It also includes the BigDL libraries.
Fujitsu
Fujitsu targets ML infrastructure with its GPU-capable PRIMERGY RX2540 M4 and CX2570 M4 servers. The PRIMERGY servers (RX2540 M4 and CX2570 M4) can be flexibly configured to optimize performance or price, or deliver a balance of both. Fujitsu’s PRIMERGY servers that are targeted to this market can support the widely used deep learning frameworks including Caffe, CNTK, TensorFlow, Theano and Torch.
To scale and deliver productive and efficient AI platforms, Fujitsu has also devised the Zinrai platform services. The Zinrai platform services can enable customers to utilize AI in diverse business scenarios with practical APIs backed by a deep learning system hosted either in the cloud or on-premises. The on-premises version, Zinrai Deep Learning System, supports up to eight GPUs, and is an appliance that enables acceleration of neural network construction. To accelerate the performance further, Fujitsu is developing a custom-engineered computing device called deep learning unit (DLU), a purpose-specific deep neural network accelerator.
Hewlett Packard Enterprises
Hewlett Packard Enterprises (HPE) has devised the broadest AI systems and services portfolio designed to deliver solutions across data center, edge and IoT ecosystems. With data center to edge solutions spanning scale-up rack and modular solutions alongside scale-out supercomputer class systems, HPE’s product portfolio is designed to address a broad range of use cases across industries.
To simplify deployment challenges, HPE offers HPE Apollo systems bundled with Bright Cluster Manager for Data Science and also offers free deployment of NVIDIA GPU Cloud. Additionally, HPE offers WekaIO for AI storage to ensure increased IO throughput required for deep learning training and inferencing. HPE GreenLake Flex Capacity enables flexible consumption models for infrastructure deployed on-premises. HPE GreenLake for Big Data and HPE GreenLake for SAP HANA provide consumption-based models for large-scale data and analytics needs. HPE Pointnext experts help enterprise organizations accelerate time to value through rapid artificial intelligence project delivery.
HPE’s Deep Learning Cookbook features use-case-driven reference architectures and a complementary set of performance benchmarks designed to profile a diverse set of neural networks and infrastructure combinations. The Deep Learning Cookbook can help end users navigate the complex space of architecting the right system for their use-case and workload requirements.
Huawei
The Huawei FusionServer G5500 server is designed to be deployed in two form factors: full-width (G560, G560 V5) and half-width (G530 V5), supporting a wide range of accelerator configurations including PCIe 3.0 GPUs, SXM2 GPU and PCIe 3.0 FPGAs. This enables the 4U G5500 modular server to deliver innovative features including high-performance computing, flexible orchestration, high-performance large-capacity built-in storage and easy maintenance. Huawei compute platforms also enable very high degrees of flexibility via support for one-click topology switching and different CPU/GPU configuration ratios (for instance, CPU:GPU ratios of 1:2, 1:4 and 1:8) for diverse applications.
The platform also supports a wide range of enterprise-grade operating systems including RHEL, CentOS Linux, Ubuntu, Microsoft Windows Server and SLES.
IBM
IBM has engineered accelerated compute systems in this market with an innovative combination of two Power-based systems AC922 and S822LC. IBM systems are driven by IBM Power Systems Architecture-based processors. IBM Power Systems processors feature several unique capabilities including native support for NVLink, PCIe Gen4 (PCIe 4.0) and Coherent Accelerator Processor Interface (CAPI), none of which are available in x86-based systems. As a result, IBM Power Systems processors can connect with NVIDIA GPUs using NVLink, enabling bandwidth close to 300 Gbps. The additional bandwidth can dramatically help improve data load and preprocessing. Additionally, InfiniBand interconnects are provisioned via the PCIe 4.0, which delivers higher throughput than PCIe 3.0 and mitigates IO contention.
The IBM PowerAI Enterprise platform integrates high-performance libraries, deep learning frameworks (TensorFlow, IBMCaffe), device drivers and acceleration libraries, along with optimized distributed deep learning capabilities that can help in scaling deep learning applications across multiple nodes. IBM PowerAI Enterprise also features enterprise-grade integration and support for RHEL and Ubuntu.
Inspur
Inspur’s NF5288M5 (AGX-2) system is designed to deliver high-performance acceleration for ML training workloads using eight NVIDIA Tesla V100 32GB (SXM2 or PCIe 3.0) accelerators in two-rack-unit (2U) form factor. High-bandwidth, low-latency scale-out capabilities are enabled via 4x 100Gb InfiniBand and EDR networking. The system also provides options for air cooling or air/liquid hybrid cooling, enabling power usage effectiveness (PUE)-optimized platforms. Users can also scale up to 16 GPUs using a GPU expansion box (Just a Bunch of GPUs [JBoG]) connected to each NF5288M5 via PCIe 3.0. The system can be configured to utilize either RHEL or SLES operating systems. Inspur has recently launched AGX-5 (NF5888M5), a scale-up system based on high-bandwidth NVSwitch and supporting up to 16 NVIDIA Tesla V100 GPUs or next generation.
Inspur designed comprehensive management suites for customers. Inspur’s Dashboard Visual Management Module helps simplify monitoring and management of the NF5288M5 systems. Specific for the AI market, Inspur has also engineered the AIStation environment that provides parameter management, model management and UI for diverse DNN frameworks. AIStation can manage the machine learning training process flow and schedule GPU resources efficiently. Inspur also provides parallel deep learning framework (including Caffe-MPI and TensorFlow) optimization services to customers.
Lenovo
Lenovo has devised a cohesive hardware and software strategy to address the AI market along with four global AI innovation centers to help customers accelerate their AI initiatives. Lenovo has designed scale-oriented density-optimized high-performance solutions for this market: ThinkSystem SD530, SR650 and SR670 supported by LiCO software.
Each ThinkSystem SD530 in a D2 enclosure features four high-performance compute density modules each of which can pack either two Intel Xeon CPUs or two NVIDIA Tesla V100 32GB accelerators. The ThinkSystem SR650 is a 2U rack system that can support up to two Intel Xeon processors and two NVIDIA Tesla V100 32GB accelerators. The ThinkSystem SR670 is designed to offer reconfigurable PCIe access to four NVIDIA Tesla V100 32GB accelerators, and is devised to maximize customization and configurability for end users while providing the ideal accelerator density for AI training workloads.
Lenovo users can also utilize a LiCO software stack based on open-source AI frameworks, which enables enterprise-grade deployment of machine learning models. The current set of AI frameworks supported (basic customer support) include: Caffe, Intel-Caffe, TensorFlow, MxNet and Neon. Additionally, a LiCO system also simplifies resource management and job scheduling to enable easy-to-manage high-productivity AI environments.
NEC
NEC has been an industry leader and pioneer in vector processing since 1983. Its current generation SX-Aurora TSUBASA is powered by PCIe 3.0-based vector engines supported by high-density 3D stacked memory (HBM2) modules. These proprietary innovations make the architecture uniquely suitable for memory-bandwidth-constrained machine learning workloads that are memory-bandwidth-bound. NEC SX-Aurora platforms can be configured in different ways depending on the Vector Engine density and scale desired.
At the high end of the supercomputer class, A500-64 can be configured with the highest density of vector engines. Because of the way the system is organized, users will need to develop custom applications using proprietary C, C++ to address the highly parallel vector engine and offload serial tasks to the Intel CPU. NEC SX-Aurora-based systems are better suited for ML applications that are memory-bandwidth-bound. NEC provides Spark MLlib, scikit-learn-compatible libraries and environments to accelerate Apache Spark and Python applications.
NVIDIA
NVIDIA, the deep learning industry pioneer, offers GPU accelerators and systems that form the foundational reference architectures for products in this category. The NVIDIA portfolio in this market segment includes two enterprise-grade systems (DGX-1 and DGX-2) that are purpose-designed to deliver extreme performance. The DGX-2 is the first system of its kind featuring 16 GPUs in a single node interconnected via the NVIDIA NVSwitch that delivers up to 2.4 TB/sec bisection bandwidth.
In addition to extreme performance and scale hardware, the NVIDIA DGX systems also feature prevalidated, optimized and fully supported deep learning frameworks provisioned using the NVIDIA GPU Cloud (NGC). The NGC container registry is free to use, and it features NVIDIA tuned, tested, certified and maintained containers for widely used deep learning frameworks. NVIDIA DGX systems are also backed by extensive support to troubleshoot any hardware, systems middleware or container issues.
Sugon
Sugon’s XSystem (W780-G20) deep learning compute environment features eight NVIDIA Tesla V100 16GB (PCIe 3.0 form factor) GPUs designed to accelerate training workloads. According to Sugon, the system is engineered to deliver high performance, high density and high reliability within an ultradense form factor. Additionally, the system has been engineered with innovative cooling techniques, enabling high performance and reliability. Because the system utilizes PCIe 3.0 to pool accelerators, users can use other accelerator technologies in this platform as well. The system can be configured with a wide range of Linux operating systems including Red Hat, SUSE and Ubuntu. However, users would be responsible for compiling and optimizing the system stack for DNN frameworks such as TensorFlow, Caffe and MXNet.
Market Recommendations
As is evident in the Representative Vendors section, the ML compute infrastructure market is significantly fragmented. I&O leaders devising infrastructure strategies for AI initiatives must use the following recommendations for highest efficiency and productivity:
Compute Acceleration Technology
Enable productivity of your ML compute infrastructures by selecting accelerator technologies that:
- Deliver the highest performance and consequently reduce training times for a wide range of DNN models
- Support a broad set of latest generation DNN frameworks
- Simplify deployment complexities by provisioning easy-to-integrate middleware and system software (including libraries, drivers and application acceleration libraries)
Scaling Up DNN Workloads
Most DNN training frameworks enable out-of-the-box support for scaling up. Deliver the highest scalability and performance by:
- Selecting compute infrastructures that provision the highest density of accelerators per compute node.
- Matching your scale of DNN model training requirements while taking into consideration potential for future growth.
- Utilizing compute accelerators that are interconnected by high-bandwidth interconnect technologies (for example, NVIDIA NVLink). Doing so can minimize IO bottlenecks.
Scaling Out DNN Workloads
Most DNN training frameworks struggle to scale-out, while there are open-source technologies such as Uber Horovod that can enable scaling out of DNN training. Enable scale-out efficiencies by:
- Utilizing high-bandwidth, low-latency networks that enable RDMA capabilities for accelerators
- Selecting vendors that deliver complementary preintegrated and scale-out-friendly deep learning frameworks
Optimizing Data Movement Within a Node
DNN workloads are inherently data-intensive. Minimize I/O bottlenecks by:
- Selecting storage mediums within a compute node that optimize small random read operations
- Utilizing SSD/flash or nonvolatile memory express (NVMe) disks that enable DNN productivity as opposed to overoptimizing on cost by selecting lower-performance hard-disk drives (HDDs)
Simplifying Deployment and Integration
Most DNN frameworks are open-source technologies and often involve integrating a complex set of libraries and supporting software. Simplify deployment and integration by:
- Selecting vendors that provision latest generation DNN frameworks via preintegrated and preoptimized containers. Ideally these containerized frameworks and scale-out ecosystems should be free.
- Validating that the containerized ecosystems support the widest range of the most relevant DNN and ML ecosystems including TensorFlow, PyTorch, Caffe/2, Keras and CNTK.
- Utilizing ecosystems that provide the latest stable versions of DNN frameworks alongside prior releases to enable easier A/B comparison where feasible.
Acronym Key and Glossary Terms
RHEL |
Red Hat Enterprise Linux |
SLES |
SUSE Linux Enterprise Server |
Evidence
This research draws on the findings of the following Gartner surveys and interactions:
- 2018 Gartner CIO Survey. This survey was conducted between 20 April and 26 June 2017. There were 3,160 respondents, with representation from all major world regions and industries (public and private). Respondents included members of Gartner Executive Programs and other IT leaders. Qualified respondents were the most senior IT leaders (often CIOs) of overall organizations or parts of organizations (such as business units and regional divisions). The survey was developed by a team of Gartner analysts. It was reviewed, tested and administered by Gartner’s Research Data and Analytics team.
- Gartner’s discussions with clients inquiring specifically about AI, as well as one-to-one meetings at events and other conversations.
- 2018 Gartner Data Science Team Survey. This survey was conducted to understand the priorities of data science teams and best practices. The research was conducted using computer-assisted telephone interviewing (CATI) from November through December 2017 among 302 respondents in the U.S., the U.K., Germany and France. Participating organizations were screened to have at least three years of data science capabilities such as machine learning, data mining or predictive analytics, prescriptive analytics, and/or text analytics. All industries qualified except technology vendors, business consulting and investment services. The respondents were screened to have both technical as well as strategic involvement in data science initiatives. The survey was developed collaboratively by a team of Gartner analysts who follow the data science industry and was reviewed, tested and administered by Gartner’s Research Data and Analytics team.
Source: Gartner Research Note G00362287, Chirag Dekate Arun Chandrasekaran, 24 September 2018
Note 1
Representative Vendor Selection
This Market Guide provides Gartner’s initial coverage of the market and highlights the market definition, rationale for the market and market dynamics. Gartner estimates that there are at least 20 vendors in this market. The 13 listed here are ones that have received the most client interest (as determined by searches on gartner.com and inquiries).