Reduce waste. Strengthen performance. Invest in what differentiates.
- Gartner client? Log in for personalized search results.
{kind=link}
New realities in cost optimization
Cost optimization today must be a continuous discipline that shapes long-term competitiveness, especially as organizations face rising expectations for speed, innovation and resilience — even while facing cost constraints.
And although cost optimization is an enterprisewide initiative, the pressures, decisions and levers vary significantly by function, so it’s critical for each leader to understand the risks and opportunities of optimizing costs in their function, given the specific context they face.
Cost optimization today requires multidimensional thinking
Traditional cost-cutting focuses on discrete savings, often at the expense of long-term capability. Today, the forces influencing enterprise cost structures are more complex. Think: rapid acceleration of AI and automation; increased spending on data, platforms and infrastructure; volatile input costs and shifting demand patterns; pressure to modernize operating models; and expanding expectations for workforce, security and sustainability.
As a result, cost decisions require multidimensional thinking: financial, operational, technological and organizational. These multidimensional demands also drive the need for function-specific actions on costs.
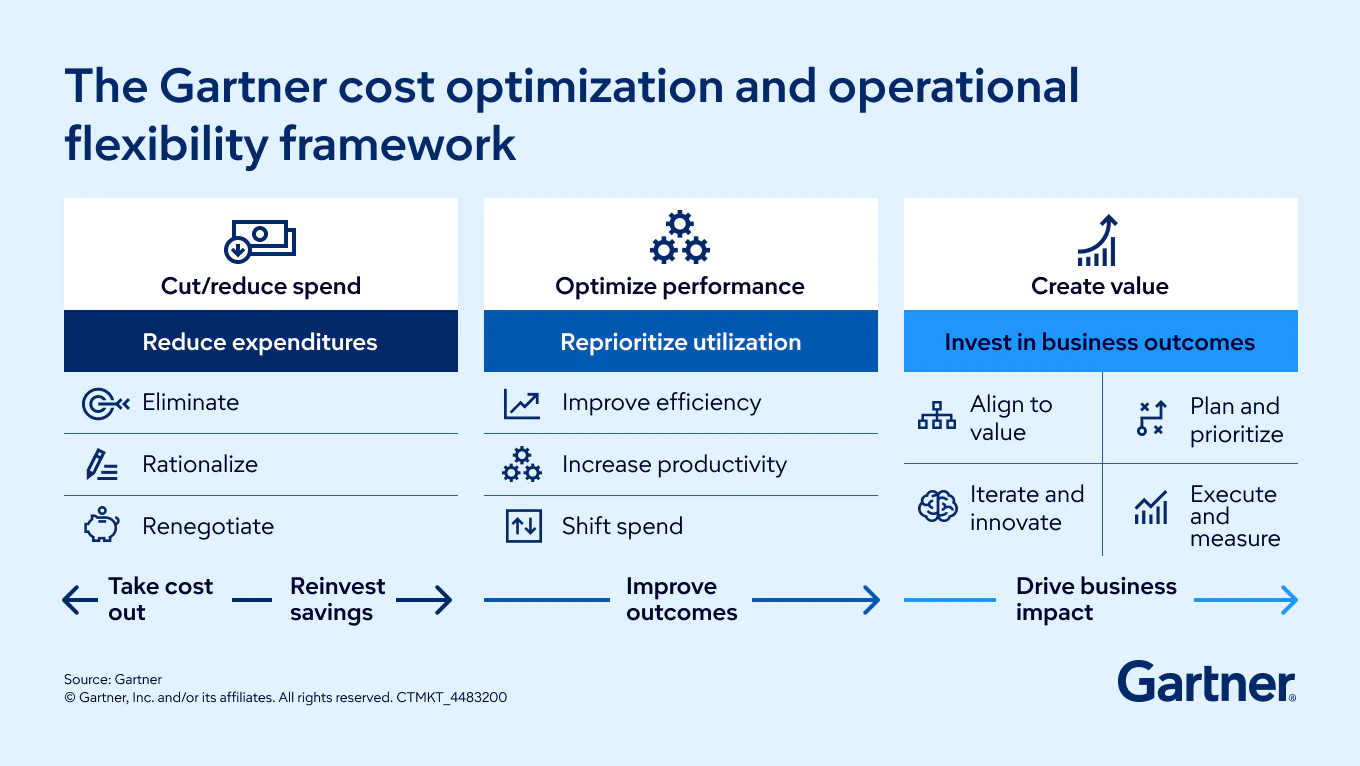
3 core dimensions of modern cost optimization
Systematically reducing low-value spend. Organizations benefit from analyzing costs through multiple lenses — such as fixed vs. variable, run vs. grow vs. transform, and value contribution — to uncover patterns that aren’t obvious in traditional line-item budgeting. The goal is not simply to cut but to identify where spending no longer aligns with strategic priorities or expected outcomes.
Improving enterprise performance. Cost optimization now includes redesigning workflows, removing friction, consolidating redundant tools, streamlining processes and using automation where it lifts both productivity and consistency. Performance optimization balances efficiency with capability, ensuring that changes improve enterprise capacity rather than erode it.
Reinvesting in future sources of value. Savings alone are not the outcome. Forward‑looking organizations reinvest in capabilities that support growth — including data foundations, AI integration, platform modernization, workforce evolution and cross‑functional operating models. Cost optimization becomes an engine for transformation rather than an alternative to it.
Taking a cost optimization approach fit for your function
Across the executive suite, different functions face very distinct questions. For example:
Finance: Balancing efficiency with growth investment, ensuring cost structures match economic conditions, and increasing accuracy in forecasting and capital allocation.
CIO and technology leadership: Managing consumption-based costs, modernizing platforms, governing AI adoption and aligning tech spend with value realization.
Procurement and supply chain: Reducing volatility in supplier ecosystems, evaluating total cost vs. value, and adapting to new risk and contract structures.
Data and analytics: Ensuring foundations are cost-effective, understanding the cost profile of AI and data platforms, and scaling responsibly.
Product, operations, HR and customer functions: Modernizing processes, improving productivity and reallocating resources from low-impact work to higher-value outcomes.
These role-specific pressures are reflected in specific mission-critical priorities (MCPs) — the decisions and outcomes each leadership role must navigate to contribute to enterprise efficiency and sustainable performance. Instead of applying one-size-fits-all responses, organizations should increasingly structure cost initiatives around these differentiated leadership perspectives.
What effective cost optimization looks like
Across industries and operating models, several patterns tend to characterize organizations that manage costs well. These organizations:
Treat cost as a continuous discipline, not a temporary exercise.
Emphasize transparency and shared accountability, with clearer insights into spending patterns and trade-offs.
Adopt a multiyear view, shifting from short-term cuts toward sustainable value optimization.
Maintain a strong link between cost, capability and performance, avoiding reductions that undermine differentiation.
Use scenario planning and adaptability to navigate economic shifts, regulatory changes and technology disruption.
- Build a culture where efficiency and value are routine considerations in decision making.
Download the cost optimization framework for your function.
Cost optimization FAQs
What is cost optimization?
Cost optimization is the strategic, ongoing process of reducing and managing expenses while maximizing value, efficiency and business performance. Rather than focusing solely on cutting costs, it aims to align spending with business objectives, improve operational efficiency and free up resources for future sources of value.
What is the difference between cost reduction and cost optimization?
Cost optimization is a continuous, business-focused discipline aimed at maximizing business value while reducing costs. Cost cuts are a short-term move to decrease expenses. Whereas cost optimization is a strategic, ongoing and holistic practice, cost cutting is a one-off, tactical and reactive initiative.
Attend a Conference
Accelerate growth with Gartner conferences
Gain exclusive insights on the latest trends, receive one-on-one guidance from a Gartner expert, network with a community of your peers and leave ready to tackle your mission-critical priorities.

Drive stronger performance on your mission-critical priorities.